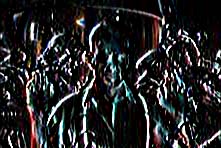![]()
![]()
影像檢索(Image Retrieval)包含了四個主要的部份: segmentation, feature extraction, representation 及 query processing。這些工作的目的,是要讓使用者能夠很快的找到他希望得到的影像資料。因為在數位圖書館中,影像的資料量可能非常大,如此要找某一張特別的圖片,便是一件非常困難且耗時的事,所以影像檢索對於數位圖書館而言,應是一個不可或缺的要件。 |
◎SegmentationSegmentation 的工作是將影像中不同的區域劃分出來,大多是時候是指者將影像中物件的邊緣找出來,然後再確定這個區域是否是有意義的區域。所以 Segmentation的第一件工作是要找出影像出物件的邊緣。 在一張影像中,邊緣就是在色彩上的不連續,例如:一邊是黑色,一邊是白色,很明顯的有能夠看到一個邊緣現在中間。但在實際的照片中,常常並不見得會有很大的色彩上的差異,而這就是在設計 Segmentation 元件時,必須針對各種不同需求而考量的參數。 基本上,Segmentation 分為兩個步驟:
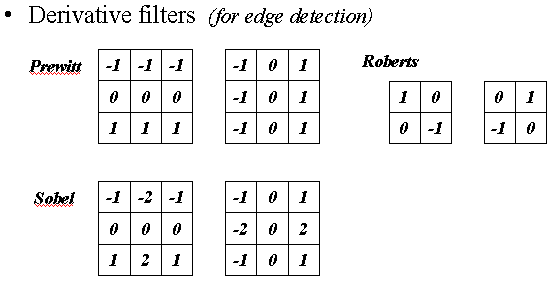
Edge detection 可用 Image Enhancement 技巧中的 Derivitave filtering.
運用這三組中的某一組,就可以把 Edge 上的點給找出來。例如:
但這樣所找出來的 Edge 是零散的點,若不將其連起來,就不能圈出一個一個的區域。所接下來就要做 Edge linking 的動作。這不是件容易的工作,有得時候也可能需要讓電腦有額外的知識才能辦得到,有時是由電腦和人合力完成。例如:
◎Feature Extraction對於數位圖書館而言,有哪些特稱需要擷取呢?這並沒有一個確定的答案,因為針對不同的需求,使用者會希望取得不同的特徵。一般而言(若沒有特殊的需求)大致有:顏色(color)、形狀(shape)、質地(texture)﹍﹍等。這些是不太需要額外知識,電腦就可以擷取的特徵。但有的時候,我們可能也會希望知道這張圖片上有沒有一輛汽車,而這就非常需要額外的知識了,而這樣的知識,通常被稱為 Domain Knowledge,因為即使是有同樣特徵的東西,在不同領域卻會被解釋成不同的東西。 有哪些特徵需要擷取,這是數位圖書館在設計時要決定的一個問題,一旦決定了之後,便可以開始思考要如何從數位影像中取得這些這些特徵。 通常擷取特徵是在 Segmentation 完成後才進行的工作,因為所謂的特徵通常是指一張影向上某一塊區域的特徵。而特徵的擷取跟特徵的表示方式(Representation)有直接的關係,因為不同的表示法,就會需要不同的擷取法! ◎Representation特徵的表示方式(Representation),依特徵的不一樣,而各有不同。以下以顏色、形狀及質地來加以說明:
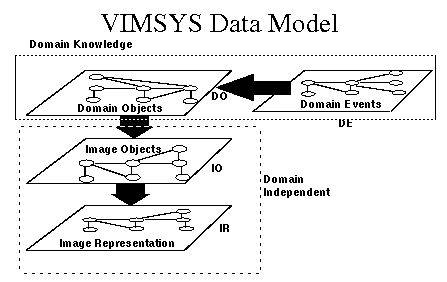
以上所介紹的 Representation 是簡單的把圖形中的特徵直接記錄下來,若我們並不希望系統提供強大影像擷取功能,則這樣的 Representation 就已經足夠了。但若我們需要強大的影像擷取功能,我們就必須要建立起一個完整的 Image Data Model。建構這樣的 Model 不只需要數位影像處理的知識,也非常需要影像本身所在領域的知識。UC San Diego 的 Visual Information Management System(VIMSYS)是一個不錯的 Model 可以參考看看。
◎Query ProcessingQuery Processing 是跟使用者關係最密切的一個部份。在這部份所關心的問題是:如何提供使用者期望的查詢介面?及如何讓我們之前做的 Segmentation, Extraction, Representation 發揮最大功效?以下將介紹 UC San Diego 所提出關於查詢方式及查詢種類的整理: How to represent a query?
Types of Queries:
|
By 陳必衷 Bee-Chung Chen, CSIE NTU Taiwan [To Homepage] [Back]