Due Sunday, October 29 at 11:59pm
This assignment is designed to support your in-class understanding of how in-memory data analytics stacks and stream processing engines work. You will learn how to write streaming applications using Structured Streaming, SPARK's latest library to support development of end-to-end streaming applications. You will deploy Apache Storm, a stream processing engine to process real tweets. Finally you will also deploy and run Apache Flink, which another popular streaming analytics system. As in assignment 1, you will produce a short report detailing your observations, scripts and takeaways.
After completing this assignment, you should:
Apache Storm has its own stack, and it requires Apache Zookeeper for coordination in cluster mode. To install Apache Zookeeper you should follow the instructions here. First, you need to download zookeeper-3.4.6.tar.gz, and deploy it on every VM in /home/ubuntu/software. Next, you need to create a zoo.cfg file in /home/ubuntu/software/zookeeper-3.4.6/conf directory. You can use zoo.cfg as a template. If you do so, you need to replace the VMx_IP entries with your corresponding VMs IPs and create the required directories specified by dataDir and dataLogDir. Finally, you need to create a myid file in your dataDir and it should contain the id of every VM as following: server.1=VM1_IP:2888:3888, it means that VM1 myid's file should contain number 1.
Next, you can start Zookeeper by running zkServer.sh start on every VM. You should see a QuorumPeerMain process running on every VM. Also, if you execute zkServer.sh status on every VM, one of the VMs should be a leader, while the others are followers.
A Storm cluster is similar to a Hadoop cluster. However, in Storm you run topologies instead of "MapReduce" type jobs, which eventually processes messages forever (or until you kill it). To get familiar with the terminology and various entities involved in a Storm cluster please read here.
To deploy a Storm cluster, please read here. For this assignment, you should use apache-storm-1.0.2.tar.gz. You can use this file as a template for the storm.yaml file required. To start a Storm cluster, you need to start a nimbus process on the master VM (storm nimbus), and a supervisor process on any slave VM (storm supervisor). You may also want to start the UI to check the status of your cluster (PUBLIC_IP:8080) and the topologies which are running (storm ui).
To set up Flink on your cluster, download it from this link and untar it with tar -xzvf flink.*.gz in your software directory on the master VM. After extracting flink edit conf/flink-conf.yaml and set jobmanager.rpc.address to the private IP of your master node.(The conf directory here refers to the directory inside your flink installation and not the conf directory in ~/.) Also edit the conf/slaves and enter the IPs of your slave VMs. Each of these worker nodes will later run a TaskManager process.
The Flink directory must be available on every worker under the same path. Copy the entire Flink directory to every worker node. Once you have performed the above steps, run bin/start-cluster.sh inside the Flink directory of your master node to start Flink.
Once you have set Flink cluster up, you can use the Flink quickstart script to setup a project for you. To do this, run the following commands in your home directory on the master.
if the build is successful run the following example to verify your installation and project setup.
~/software/flink-1.3.2/bin/flink run -c org.myorg.quickstart.WordCount ~/quickstart/target/quickstart-0.1.jar
This part of the assignment is aimed at familiarizing you with the process of developing simple streaming applications on big-data frameworks. You will use Structured Streaming (Spark's latest library to build continuous applications) for building your applications. It is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data.
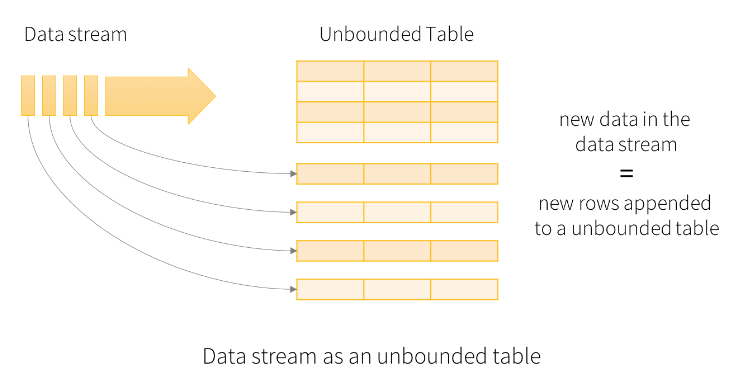
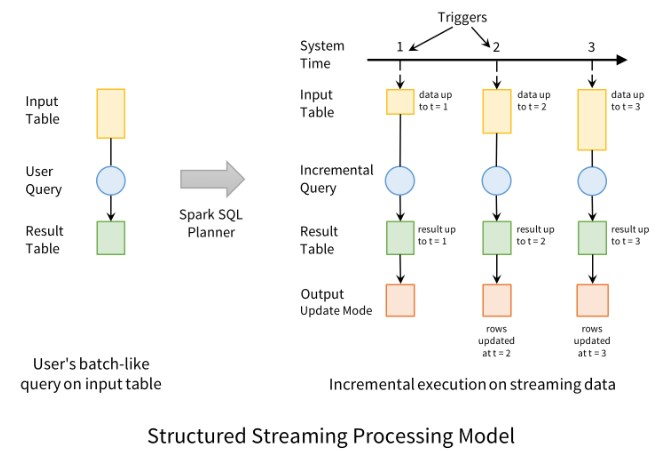
Structured Streaming has a new processing model that aids in developing end-to-end streaming applications. Conceptually, Structured Streaming treats all the data arriving as an unbounded input table. Each new item in the stream is like a row appended to the input table. The framework doesn't actually retain all the input, but the results will be equivalent to having all of it and running a batch job. A developer using Structured Streaming defines a query on this input table, as if it were a static table, to compute a final result table that will be written to an output sink. Spark automatically converts this batch-like query to a streaming execution plan.
Before developing the streaming applications, students are recommended to read about Structured Streaming here.
For this part of the assignment, you will be developing simple streaming applications that analyze the Higgs Twitter Dataset. The Higgs dataset has been built after monitoring the spreading processes on Twitter before, during and after the announcement of the discovery of a new particle with the features of the Higgs boson. Each row in this dataset is of the format <userA, userB, timestamp, interaction> where interactions can be retweets (RT), mention (MT) and reply (RE).
We have split the dataset into a number of small files so that we can use the dataset to emulate streaming data. Download the split dataset onto your master VM.
Question 1. One of the key features of Structured Streaming is support for window operations on event time (as opposed to arrival time). Leveraging the aforementioned feature, you are expected to write a simple application that emits the number of retweets (RT), mention (MT) and reply (RE) for an hourly window that is updated every 30 minutes based on the timestamps of the tweets. You are expected to write the output of your application onto the standard console. You need to take care of choosing the appropriate output mode while developing your application.
In order to emulate streaming data, you are required to write a simple script that would periodically (say every 5 seconds) copy one split file of the Higgs dataset to the HDFS directory your application is listening to. To be more specific, you should do the following - Question 2. Structured Streaming offers developers the flexibility is decide how often should the data be processed. Write a simple application that emits the twitter IDs of users that have been mentioned by other users every 10 seconds. You are expected to write the output of your application to HDFS. You need to take care of choosing the appropriate output mode while developing your application. You will have to emulate streaming data as you did in the previous question. Question 3. Another key feature of Structured Streaming is that it allows developers to mix static data and streaming computations. You are expected to write a simple application that takes as input the list of twitter user IDs and every 5 seconds, it emits the number of tweet actions of a user if it is present in the input list. You are expected to write the output of your application to the console. You will have to emulate streaming data as you did in the previous question. Notes: For Part-B of this assignment, you will write simple Storm applications to process tweets. For this part, ensure that only the relevant Storm daemons are running and all other daemons are stopped.
To write a Storm application you need to prepare the
development environment. First, you need to untar apache-storm-1.0.2.tar.gz
on your local machine. If you are using Eclipse please continue reading
otherwise skip the rest of this paragraph. First, you need to generate the
Eclipse related projects; in the main storm directory, you should run:
mvn eclipse:clean; mvn eclipse:eclipse
-DdownloadSources=true -DdownloadJavadocs=true. (We assume you
have installed a maven version higher than 3.0 on your local machine).
Next, you need to import your projects into Eclipse. Finally, you should
create a new classpath variable called M2_REPO which
should point to your local maven repository. The typically path is /home/your_username/.m2/repository.
Once you open the Storm projects, in apache-storm-1.0.2/examples/storm-starter, you will find
various examples of Storm applications which will help you understand how to
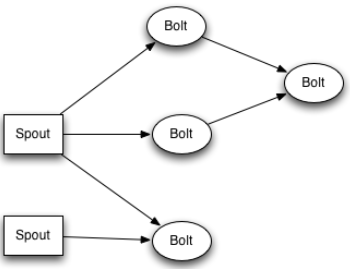
write / structure your own applications. The figure below shows an example of a typical Storm topology: The core abstraction in Storm is the
Part B - Apache Storm
Prepare the development environment
Typical Storm application
We recommend you place your Storm applications in the same location as the other Storm examples (storm-starter/src/jvm/storm/starter/PrintSampleStream.java in 0.9.5 version and storm-starter/src/jvm/org/apache/storm/starter/PrintSampleStream.java in 1.0.2 version).To rebuild the examples, you should run: mvn clean install -DskipTests=true; mvn package -DskipTests=true in the storm-starter directory. target/storm-starter-0.9.5-jar-with-dependencies.jar will contain the "class" files of your "topologies". To run a "topology" called "cs744Assignment" in either local or cluster mode, you should execute the following command:
storm jar storm-starter-0.9.5-jar-with-dependencies.jar storm.starter.cs744Assignment [optional_arguments_if_any].For rebuilding the examples in 1.0.2 version, look at the documentation here.
In this assignment, your topologies should declare a spout which connects to the Twitter API and emits a stream of tweets. To do so, you should do the following steps:
Question 1. To answer this question, you need to extend the PrintSampleStream.java topology to collect tweets which are in English and match certain keywords (at least 10 distinct keywords) at your desire. You should collect at least 200'000 tweets which match the keywords and store them either in your local filesystem or HDFS. Your topology should be runnable both in local mode and cluster mode.
Question 2. To answer this question, you need to create a new topology which provides the following functionality: every 30 seconds, you should collect all the tweets which are in English, have certain hashtags and have the friendsCount field satisfying the condition mentioned below. For all the collected tweets in a time interval, you need to find the top 50% most common words which are not stop words (http://www.ranks.nl/stopwords). For every time interval, you should store both the tweets and the top common words in separate files either in your local filesystem or HDFS. Your topology should be runnable both in local mode and cluster mode.
Your topology should have at least three spouts:
Notes:
Flink is another stream processing framework for distributed, high-performance, reliable and accurate data streaming applications. It has a unified architecture for both stream and batch data processing, and it treats batch processing as a special case of stream processing where the stream is infinite. . It supports event time, ingestion time and processing time process, and it has a flexible windowing mechanism (for example, tumbling window, sliding window and etc.) Look here for a detailed description of Flink's useful features.
Streaming source: we will use the same dataset as that of structured streaming part (here, copy this data set to all the vms in the same path), using Collection-based Data Source to simulate the streaming source. reference to this page for more detail. Read the input file and create a data stream according to the input file (Set the rate to 10 lines per millisecond, you can achieve this by sleep 1 ms per 10 lines). The source code to simulate stream is provided here. You can use it to simulate a stream for Flink using the higgs data set.
Question 1. Develop an application to find all the disjoint 1-min time intervals that have more than 100 retweets (RT), mention (MT) or reply (RE). (E.g., the intervals will be[0, 1] min, [1, 2] min etc.) What if the time intervals do not need to be disjoint? (E.g., [0, 60s], [1s, 61s], [2s, 62s] etc.) You can assume that the data is sorted according to the timestamp. Output all the satisfying time windows, according to the following format (using millisecond timestamp format).
Question 2. Handle out-of order data. Flink allows the data to arrive in a different order from their real timestamps, which is a common case in real time streaming systems. Change your dijoint 1 minute time window application in Question 1, allow late arrive. Change the time bound of the late allowance to 30 seconds, 60 seconds, 100 seconds and 500 seconds. For each of these allowance values, compute the number of intervals that stay the same (compared to your original application in question 1). A window is the same as another window if start, end, count and type fields of the two windows are the same. Please use shuffled data set which simulates late arrivals for your application in question 2.
You should tar all the following files/folders and put it in an archive named group-x.tar.gz
You should submit the archive by placing it in your assignment2 hand-in directory for the course: ~cs744-1/handin/group-x/assignment2/.
Apart from submitting the above deliverables, you need to setup your cluster so that it can be used for grading the applications developed. More specifically, you should do the following -