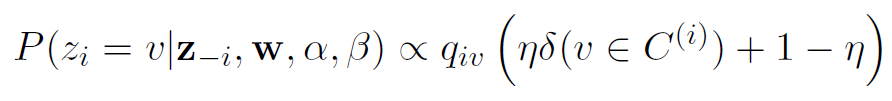from numpy import *
from zlabelLDA import zlabelLDA
# model parameters
(T,W) = (4,6)
alpha = .1 * ones((1,T))
beta = .1 * ones((T,W))
# corpus of documents
docs = [[1,1,2],
[1,1,1,1,2],
[3,3,3,3,5,5,5],
[3,3,3,3,4,4,4],
[0,0,0,0,0],
[0,0,0,0]]
# z-label strength
eta = .95 # confidence in the our labels
# z-labels (will be ignored unless it is a list)
zs = [[0,0,0],
[0,0,0,0,0],
[[0],[0],0,0,0,0,0],
[[1],[1],0,0,0,0,0],
[0,0,0,0,0],
[0,0,0,0]]
# set number of samples, random number generator seed
(numsamp,randseed) = (100,194582)
# Do inference to estimate topics
(phi,theta,sample) = zlabelLDA(docs,zs,eta,alpha,beta,numsamp,randseed)