Niagara System Notes
I've assembled this from the so-called Bolo Report that
everyone has sent me with regards to their portion
of the system.
I hope that by reading this everyone will be exposed to some of
the issues that other people deal with and, by doing so, gain
greater knowledge about the system as a whole.
Remember that each of these notes are from the viewpoint of
the person writing them; two people may have quite different
viewpoints about the same area of the system.
That can reflect either a misunderstanding on the part of a person,
or it can reflect that a portion of the system does more than one thing,
and maybe should be split a bit to reflect that.
There may also be criticisms aired about a portion of the system
that you are responsible for. Try to not take thos criticisms
personally. They reflect difficulties that other people have with
designs or code that you wrote, or that may have seemed a good
choice at the time, but didn't turn out that way.
Most people I know are rather proud of the things that they build,
and would like them to be really good.
Unfortunately, time and good enough for now is often the
killer on making things really good.
There are a lot of things that can be done on the system, and finding
out where the problems lie and exposing them to everyone's view
is the first step towards finding or making the time to fix those
problems.
As you read these notes, I hope you start to recognize some of
the larger scale design problems and coding issues that I have been
talking to you about. There are certainly several good examples,
especially in some of the longer writeups.
Issues like that are why good interfaces and design are really
important. Once other parts of the project start depending upon
things that are less than optimal, it becomes a lot more difficult
to change or remove them.
This is an Overview of the Index Manager.
Architecture
Th figure below shows the architecture of the Index
Manager (IM). Labels on the boxes are C++file/class names. In general
each class is defined in its own C++ file, but there are some exceptions.
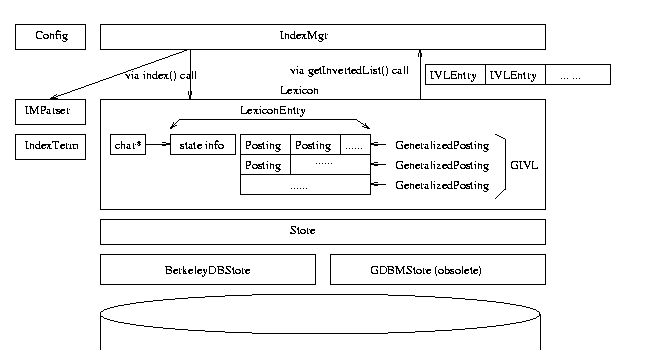
The architecture of the Index Manager
I only go through each class briefly. Hopefully this document provides
a good enough roadmap to start exploring IM. For the details please see
the source code or contact me (Chun). The code was developed incrementally
over an extensive period. Sometimes I looked at my code and had to think
hard to figure out what I did, when that happens, I usually would add some
comments. By this practice, I hope that the code is not too obscure.
Brief Overview of the Various Classes
The Config class groups together the knobs to turn to
configurate the IndexMgr.
All the parameters have default values, so one pretty much can
leave the Config class alone. In fact this is what most Niagara people do.
I bet I am the only person who would turn those knobs.
The IndexMgr class is the interface to the rest of the
world (DM, QE, triggers, etc).
All requests to IM go through this class and it controls the
activities in IM. The header file contains extensive comments. IM currently
operates in two modes: indexing and retrieving.
I separate the two modes just for clarity and conveniency. The Index
Manager can, and should
be able to, operate in the two modes simultaneously. The indexing mode
is triggered by the index() call, at which time the XML
file is parsed
via the IMParser class to generate Postings, which
are then
deposited into a Lexicon. The retrieving mode is
triggered by the
getInvertedList() or getIVL() call.
The Lexicon class is an in-memory representation of an inverted
index. There are three lexicon instances: element lexicon, text
lexicon, and dtd lexicon. They store mappings for elements, text words,
and dtds, respectively. Note that the architecture figure depicts
class relationships, not instance/object relationships, so you only see
one Lexicon class. Each Lexicon is a map of terms into
LexiconEntrys, where a term is a tag (e.g., book,
author), or a text
word (e.g.,java, naughton), or a dtd (e.g., http://www.foo.com/bar.dtd).
A LexiconEntry encodes the occurrances of the term. The
idea is that
given a term, we can find exactly where it occurs in the collection of
XML documents
indexed. A Lexicon has a collection of LexiconEntrys.
A LexiconEntry contains the wordno (misnomer,
should be called
termno), the in-memory inverted list (represented by the class
GIVL), a mutex, and two flags. One of the flags tells
whether the
inverted list is cached in memory. If a list is not cached in memory, it
is either on disk or it does not exist. The other flag tells whether the
list was modified (dirty) since read into memory. A ``dirty'' list signals
the possibility that there is an incosistency between the in-memory copy
and the on-disk copy. Note that a newly created list is dirty but does not
exist on disk. There is more detailed comments in the source code.
A in-memory inverted list is represented by the GIVL class, which
stands for ``generalized inverted list''. The name comes for historic reason.
An inverted list used to be a vector of IVLEntry (which stands for
``inverted list entry''), but later I need to add more functionality and
I found that the IVLEntry representation is not flexible enough.
To see the difference between a new list (GIVL) and an
old list (vector of
IVLEntry), we need to talk about the Posting
class first.
A Posting encodes the occurrance of an element or a text
word in an XML document. It has the following fields: docno,
beginNumber, endNumber depth, and
elemid.
The meaning of the fields should be obvious. The first four are
used by IM, but the last is really used by DM and the Query Engine.
The reason that IM has to generate element id for DM is that the Query
Engine gets data from both IM and DM, and element ids serve to connect
the data coming from the two modules.
Now, a GeneralizedPosting is a sequence (vector) of
Postings.
The name was chosen as I consider it a generalization of simple Postings.
It is used to represent a sequence of related elements or text words that
form a data path. A GIVL is a sorted list of such sequences.
GeneralizedPosting and
GIVL allow me to use inverted index to
represent paths and compute path expressions---things such as
``book.author.name''.
At the beginning however, IM was designed only to retrieve simple inverted
list of single elements or text words. For that purpose, the class
IVLEntry was used. In addition, the Posting class
did not have
the docno field, which was kept in the IVLEntry
class (it is still
there). An IVLEntry contains a docno and a vector of
Postings that are all from the same document. I shifted to use
GIVL for an inverted list because it is more general and easier for
path expression processing. However, because the rest of the world still
sees the inverted list as a vector of IVLEntry, the class
GIVL
was only used internally by IM. Upon returning an inverted list to the Query
Engine, a generalized inverted list is converted into the old vector of
IVLEntry's. Currently the Query Engine does not use the functionality of path
expressions, and therefore it is fine for it to only see inverted lists of
single terms (represented by IVLEntry's) instead of lists of path expressions
(represented by GIVL's).
IM interfaces with the disk via the Store interface
and a set of Store drivers. The Store interface was
intended to be very generic. It only sees data records as (key,value)
pairs where both the key and the value are char*'s. The interface specifies a set of very
general member functions, such as fetch a record, store a record, append a record, etc.
One of the driver is the BerkeleyDBStore class. It is the one that is currently being
used by IM. Another driver is the now obsolete GDBMStore class. Future drivers can be
added to interface with Shore for example.
Issues and Miscellaneous
IM provides very primitive memory caching of inverted
lists. A list can be found in the memory for two reasons:
- It is currently in the indexing mode, and the list is newly
created. When in the indexing
mode, lists are accumulated in the memory until the used memory
exceeds some point (controlled by
IM_BATCH_BUFFER_SIZE in Config.h), and then flushed to disk.
- It is retrieved by the Query Engine and brought from disk.
Currently there is no
replacement implemented. The member function flush() can be used to
periodically free up memory.
As mentioned, because the other parts of the world still sees an inverted list as a vector of
IVLEntrys, IM returns lists of the old format to the
Query Engine. One can
also avoid using the old list format and get a GIVL
directly by calling getIVL().
This is more efficient as the normal getInvertedList()
call incurs a conversion between
the two formats.
I explained three lexicons previously. Each lexicon is stored in a
separate database file
under an IM data directory. The names of the data directory and these
database files are
controlled by parameters in Config.h (see comments there). Besides
the three inverted index
databases, there is an additional meta database, which
records meta data information as well as the urls IM knows about. The
meta information is read
in at IM startup time and kept there until shutdown, at which point
the meta information is
rewritten back to disk. This way any changes to the meta information
is reflected next
time IM starts up. The format of the
meta information can be found in the comments of IndexMgr::IndexMgr()
in IndexMgr.cpp.
Just as each element or text word is assigned an id, each document is
also assigned an id
(the docno mentioned previously). In addition, each
document has a timestamp. A (url,
timestamp) pair uniquely determines a document number. With
timestamps, IM supports versioning
of documents. The url,timestamp,docno associations are stored with ``double
mappings'' in the meta database. This means that a url can be used as
a key to retrieve its
associated versions (timestamps plus docno's, see
IndexMgr::_getTimestampDocnos() in IndexMgr.cpp),
and a docno can also be used as a key to retrieve its url (see
IndexMgr::getUrlName() in IndexMgr.h).
Leonidas partially and myself mainly have responsibility over the
following parts of the code-base:
- qe/PathExpressions - Leonidas/Stratis
- qe/Conditions - Stratis
- qe/LogicalPlan - Stratis
- qe/LogicalToPhysical - Leonidas/Stratis
Which means that I am responsible for the cyclic dependency. The reason
why it is there: when I was implementing the algebra, I tried to
completely replicate what was there in the algebra paper we were using
(which was far different than what we have now). In the original version,
the only way you could specify a path expression was by encapsulating it
into a follow operator. The implications were that even if you wanted to
specify a path expression as part of a condition, you would have to wrap
it into a follow operator. What I did, in order to keep it a little
cleaner was to create a single FollowContainer class as part of the
Conditions framework, which can be used to hold Follow operators inside
it, hence the cyclic dependency: a condition can be a FollowContainer,
which contains a Follow operator, and conditions can appear as parts of
Logical Operators.
Why it is still there? One good answer is that as you said, we kept on
deferring the solution until it became one of our "adored" features. An
other answer is that the Trigger people started using that implementation
and were not all that happy about me changing the code when they had an
implementation of their own stuff ready.
Other parts of the code I am not all that enthusiastic about:
- The Parser's syntax tree is closely tangled to XML-QL. The
whole structure is useless if we move to Quilt, so is the whole
translation from a parse tree to a logical plan which is a pain to write.
- I would like to put schema information in every logical operator so it
would make the optimizer's search strategy more efficient (some
transformations would not be considered if they did not lead to the same
schema).
- The Trigger manager uses a debugging method (toString()) in order to
generate plan signatures and test sub-plan equivalence! That does not seem
to make sense to me.
- There is no universal debugging message framework. Everyone (including
myself) adds cout lines to locate problems or specify execution
points. This is something we have to fix as soon as possible (specify
debugging levels/messages and everything).
- I will have to disagree though that the code base is a complete mess. I
think the "messy" picture was due to the level of detail we went to when
presenting the engine's structure. As far as the QE is concerned, here are
my thoughts:
- If neither Conditions nor the LogicalPlan were dependent on the
PathExpressions, that would mean both of them had discrete implementations
for the same logical entity. I think it would be much messier if they were
separate.
- Same thing for LogicalPlan and PhysicalPlan, with regards to Conditions.
If there were an entirely different representation, as it can be the case
in a relational system I would agree that there should be no code sharing
between these two (off the top of my head, the logical plan can refer to
attribute names, while the physical plan can refer to attribute positions
in a relational tuple)
- The problem we have so many dependencies stems from the fact that the
data model is so complicated. We need a whole bunch of information
traveling through the system at any time (you've read the algebra paper,
so you have a good idea of how hard it is to handle all the different
parameters).
- Another factor we haven't pointed out is that our plans are not straight
relational-style plans. We have a unified operator framework, which means
that our physical plan has Search Engine operators as its leaves. This
entails the physical plan and the operators frameworks having to link to
both the query engine and the search engine.
- I was thinking of re-writing the Conditions/LogicalPlan framework once
the deadlines had passed and the decision to move to Quilt was final. I
guess now is a good time to do it.
- The Query Engine obviously has to link to everything.
- I agree that a better design should have been made. It is my personal
opinion that we should have spent a whole semester just designing the
system. However, what we did was to rewrite the existing prototype in C++
and add new stuff in there without thinking of the repercussions. That
leads into the "messy" picture that was presented. In my opinion though it
is not a mess. It is a good approximation of what could be done under the
circumstances.
Here is my list of things that I think should be changed and things that I
don't like. There is no structure to this but I am rather going
through the monster and my notes reporting relevant stuff.
- General
- The various toString methods are I believe a mistake. I
thought it would be cleaner but it seems to me now that we should have
overloaded the >> operator.
- Thread Package
- I think that we probably should stay only with
CommonC++ and rewrite the query engine to use CommonC++ instead of
JTCThreads.
- const-ness
- People don't seem to know what const class members are. I myself
forget to supply the correct modifiers to class members. Other times I
cannot since I want to call a method of an object that is supposed
to be const but is not. So I have to change other peoples' code and
make it const (which I should not do and don't) or compromise and have
function be non const either. I will illustrate with an example further
below when I talk about the QENodes and the XNodes.
- General Operators
- The throw GeneralError in the execute procedure of
the Operators is java thing that made it to the C++ code. I think it
is never caught anywhere since as far as I can remember catching it
did not work.
- BaseOperator
- The BaseOperator class is supposed to be an interface with the least
things an operator should do. It was necessary since base operators
such as XbtFileScan, IndexScan and DOMFileScan do not subclass from
the generic operator but need this interface to be handled correctly.
What I don't like here is that I return pointer when I ask for the
source streams and destination streams to vector having null represent
the fact that there are no source or destinations.
- BasicSelect.hh
- The name of the file qe/Operators/BasicSelect.hh should be Select.hh
but it was clashing during inclusion of files since namespaces do not
enforce file names and paths as do java
packages. PredicateEvaluatorContainer is class to facilitate jianjun's
ideas for a specialized predicate evaluation but he has not yet used
the fact that there can be a different PredicateEvaluator to the
select and join operator. The evaluator currently used is the function
object Evaluator in qe/Operators/PredicateEvaluator.hh.
- DOMFileScan
- DOMFileScan (qe/Operators/DOMFileScan.hh) is a debug operator that
just creates a DOM object of the given file and feeds it to the
operators above.
- DOMConstruct
- DOMConstruct is a construction operator that transforms the tuples
into what the query wants to construct. The result is a stream of
DOMDocuments (should be DOMDocumentFragments) that represent the
result. However I think that constructed stuff should go into a
specific document into the data manager where it would be available
for querying again.
- Operator Tree
- You will notice HeadOp and HeadOperator. Both of them get attached the
operator tree on the top. Me and ravi have to talk about which one to
keep. There is also something called NewHeadOp which was a misnaming
but has no been removed yet. We always seem to forget about
it. Basically the head operator takes a user specified HeadProcessor
(see qe/QueryEngine) and executed it and then deletes it.
- Memory Management
- Both joins don't do any memory management. This I think is
important. We left it out since we were rewriting from java and wanted
the stuff to work first. It still doesn't. Also partial stuff is
missing.
- Predicate Evaluator
- The predicate evaluator is a recursive function that descents the
condition tree. In terms of performance this is really bad. Again the
java stuff had the same structure and bla bla...
- SearchEngineScan
- SearchEngineScan and IndexScan share a lot of the code. I meant to
somehow combine the common functionality in a superclass but have still
not done it.
- General QENodes
- This a collection of a couple of classes that are
intended to make the query engine independent of the XML data model
implementation. In other words the query engine should be able to
query over any dom-like XML interface not just DOM or feng's
persistent DOM-like implementation. So the specific subclasses of
QENode encapsulate the node needed and QENode defines the
interface. This creates some problems and I think that the solution in
place now is a bit more complicated than it should be.
- QENode::getChildNodes()
- For instance QENode::getChildNodes() returns a list of QENodePtr which
conceptually is a pointer (now it is a refernce counted object
containing the actual pointer). Reference counting is necessary since
otherwise I cannot keep track of what to delete. But this requires
that QENode is increased by the size of a JTCMutex (pthreads spinlock)
in order to keep a valid reference count across threads. For the DOM
implementation we have now this is kind of an overkill since the mutex
is larger than the objects that are beeing reference counted. I will
have to talk to you about that to figure things out since I think it
is difficult to explain in writing. My desiderata, however, would be
the following: I would like small QENode objects (now they are 60bytes
for QEXNode) so that I could allocate them on the stack and copy them
into vectors. For QENodes some of the supposedly read only functions
cannnot be made const since XNodes' corresponding functions are not.
- Logical Plan
- The Logical plan has the following known flaws: - The Child class is
not used any more. - The hierarchy needs some cleaning up - Vertex
and Expose should be unified to a single operator since the current
scheme does not work algebraically. For one it cannot create
arbitrarily complex structures and it cannot handle out most tag
variables. Vertex is both a logical operator and exposecomponent which
now we know that is wrong.
- Conditions
- In the Conditions stuff is really messy. I think a total rewrite with
a more recent version of the algebra in mind is needed. For example a
FollowContainer which is supposed to hold merely a path expression is
itself both an operator and a condition having the child vectors of
both condition and logical operator. This double hierarchy makes
SchemaAttribute (which is supposed to be an optimized form of a Follow
for execution) be both an LogicalOperator and a Condition. Thus
problems arise with cloning the Logical Plan trees since some nodes
are both LogicalOperator and Condition. Also problems arise in the
translation of LogicalPlans to Physical Plans. The worst of all is the
SchemaAttributeNode inheritance scheme: It is a Condition a
LogicalOperator and an ExposeComponent.
- PhysicalPlan
- The physical plan holds the lower level description of
the Plan and also the Search Engine part of the execution. The Search
Engine part comes from analyzing the LogicalPlan and creating
corresponding index operations that are translated to SEOp trees.
Basically the subtree below the first SearchEngine operator becomes
annotated with the correct SEOps that are later executed by the
IndexScan and SearchEngineScan. Inside PhysicalPlan you can also find
the scheduler which traverses (again recursively) the Physical
Operator tree bottom up and at each node it calls a function that
creates the Corresponding Operator (from Operators). I think this
section needs also work. Seems to me a lot of stuff in here belongs
to the Logical Plan (like the Tuple description for example).
- LogicalToPhysical
- Placeholder for a decent optimizer.
- PathExpression
- The mother of all evil. Take a look at the
qe/PathExpressions/RPENode.hh The comment header shows the
structure. While for the "Forward" part of the PathExpressions the
representation is suitable for doing the element unnesting (which is
really a nested loop join if you take a look at the method
QENode::getNodeReachable) it is probably complicated for some other
stuff. The representation of the reverse part is I think much more
complicated than needs to be. This representation gave me a lot of
unnecessary headache when I was trying to advance the entry point of a
path expression and trying to keep reverse part and forward part
consistent. Therefore a wrote the path expression parser which parses
a path expression into a string. So I ended up doing string
manipulations. (by advancing an entry point i mean make a.b.c b.c:a).
Also I think that the interface of the path expressions has not
evolved consistently since it was not designed in advance.
- Streams
- The thing I like about the streams is that the interfaces of
Source and Destination streams are separate and no "spoken" convention
is needed to define which function an operator may call depending
whether it is a Source of tuples or a destination of tuples. The stuff
in Stream.cc seems to be working even for small queues. The tuple
class models a tuple of QENodes. The tuples are manually deleted and
not reference counted since it is fairly straightforward to delete
them. Some partial stuff has to be defined here still.
- SEOperators
- This stuff seems to work fine except the IS operator
which we aren't sure how to implement and what it means. Personally I
think that it is not very important to have an IS operator. Here the
operators that interact with the index manager are ElementOp, DTDOp
and StringOp. I am not sure about the deletion of the postings
though. So far I have been deleting postings when executing a search
engine query unless it was an ElementOp or ISOp or DTDOp since then it
was the duty of the Index manager to its stuff. Also what I noticed in
this directory is the use of include files in mentioned. I think
similar things can be found all over the place. For example the ISOp
should include the index manager in the ISOp.cc file and not in the
ISOp.hh file.
- QueryEngine
- The query engine needs an interface clean up. The worst
example is the QueryInfo class. Some of the stuff that is accessible
should not and some that should is not. The query result object is
supposed to be some kind of cursor. I think we are not using it
now. It is a straight rewrite from the java stuff. Otherwise the query
engine seems to work in general in terms of scheduling and placing
queries and operators in their respective queues.
- Server-Client
- The src/client directory has the classes that a client needs to
communicate with the Server using the current xml protocol. I would
also like to put in the repository the source for niagara.jar in the
client directory.
- Server
- For the server a little cleanup probably is in order. We are using the
Common C++ package to manage the server threads and to use the socket
abstractions. The ClientRequestHandlers directory currently contains
only a handler for the XML protocol that we also used with the java
prototype. The things that need to be done here are the following: The
results currently are not batched before they are sent to the client
(currently the only client communicating with the server in xml is the
java client in niagara.jar). Now each result is enclosed in an xml
envelope and is sent to the client. Of course this is not efficient. I
tried to do the other batching thing but I had synchronization
problems implementing it. Also there needs to be a specialized
XMLHeadProcessor for the trigger specific query execution. One more
thing: The XMLQueryProcessor also duplicates a lot of work from the
query engine. Nevertheless it needs some XMLProtocol specific stuff
that the query engine cannot provide. I probably should talk to you
about it.
- IDM
- Data Manager and Index Manager are both personal work of feng and chun.
I am not familiar with their code to the point where I can make changes
effortlessly. I think that tha index manager is really stable and
realiable.
- Build system
- I have never used imake stuff but I believe that
autoconf can still be used in conjuction with imake. I personally
prefer automake since it is now most commonly used (GNU stuff only
uses automake/autoconf). But if you feel more comfortable with imake I
have no objection.
This deals with the Search Engine Operators,
the code in src/qe/SEOperators directory.
- CONCEPTUAL STRUCTURE
- SEOperator is the abstract class of the search engine operators; all
other search engine operators are derived from it. For the input,
output, and functions of individual operators, see comments in
*SEOperator.h*. For self-containment of this document, the summary of
the comments is enclosed.
- KNOWN PITFALLS
- There is an ORDER_OP defined in SEOperator.h but is not implemented in
the current version. This is due to the design decision of *excluding*
arithmetic comparisons from search engine operations.
- CODE DEPENDENCIES
-
- SEOperator.h depends on src/idm/im/IndexMgr.h
- All other 13 header files depend on SEOperator.h
- SEOperator.cpp depends on SEOperator.h
- All other 13 cpp files depend on their corresponding header files.
e.g. AndOp.cpp depends on AndOp.h
- In addition to (4), StringOp.cpp also depends on DistanceOp.h
- SUMMARY OF OPERATOR FUNCTIONS
- Returns the inverted list of the element of the given name
static const int ELEMENT_OP = 1;
- Returns the inverted list of a quoted string(may be multiple words)
static const int STRING_OP = 2;
- Returns the inverted list of a dtd url (where it appears in conformed documents)
static const int DTD_OP = 3;
- Given two inverted lists, produces an inverted list that satisfies the containment
static const int CONTAINS_OP = 4;
static const int CONTAINED_OP = 5;
- Given two inverted lists, produces an inverted list that satisfies the direct containment (adjacent in depth)
static const int D_CONTAINS_OP = 6;
static const int D_CONTAINED_OP = 7;
- Given two IVLs of the *same type* element, produces an inverted
list that satisfies corresponding set operation of positions.
static const int AND_OP = 8; //intersection of positions sets
static const int OR_OP = 9; //union of position sets
static const int EXCEPT_OP = 10; //difference of position sets
- Given two IVLs, one is an IVL of an element and the other is of a string
produces an inverted list of the element whose content is exactly the string
static const int IS_OP = 11;
- Given two IVLs, the second of which is a DTD IVL
produces an inverted list from the first input IVL that conforms to the DTD.
static const int CONFORMS_TO_OP = 12;
- Given: an IVL of an element with numeric values,
a numeric comparison operator (>,<,=,...), and
a numeric value to be compared to.
produces an inverted list of the element that satisfies the predicate
- Not implemented yet: Need index level support for efficiency
static const int ORDER_OP = 13;
- Given: two IVLs of text words,
a numeric comparison operator, and
a distance value to be compared to.
produces an inverted list of *minimal cover* positions, each of which
covers a pair of positions from the two IVLs that satisfies the predicate
static const int DISTANCE_OP = 14;
The trigger system consists of three main modules,
TriggerManager, GroupQueryOptimizer and EventDetector under src/trigger
directory. EventDetector is developed by Yuan and I guess he will send
you some descriptions of EventDetector. Below is a beief description of
the TriggerManager and GroupQueryOptimizer. If you have further
questions, feel free to let me know and I am happy to discuss you about
the code.
Class TriggerManager offers interfaces to the users for creating a
trigger
by using createTrigger() function. The TriggerManager constructor takes
parameters for specifying whether to use group optimizations and which
group optimization method (PushDown or PullUp) to use. TriggerManager
further
calls EventDetector to monitor related files of a installed trigger.
Then
the install process is finished and a trigger id is returned.
The main thread of TriggerManager is an infinite loop which waits for
notifications of
triggers to be fired from EventDetector. When EventDetector informs
TriggerManager, TriggerManager starts a new thread
of Class TrigExecutor to execute those triggers. TrigExecutor class
further
calls the fire() function in TriggerManager to execute those triggers.
Function
executeLogPlan() in QueryEngine is invoked in fire() for executing
a trigger query.
TriggerManager is the main module of the trigger system. It starts a
EventDetector and a GroupQueryOptimizer in its constructor, which are
two other main
modules of the trigger system.
A GroupQueryQptimizer traverses a parsed trigger query plan and tries
to perform
matching between selection and join operators in the query plan with
existing group plans. Two kinds of signatures SelectSig and JoinSig are
created for
selection and join signatures seperately. Both SelectSig and JoinSig are
inherited from a common class Signature. Another class in
GroupQueryOptimizer directory is ConstTblMgr, which invokes the common
DataManager instance to store a special XML file for
the group optimization purpose.
My part of Niagara is the "Niagara server", responsible for
establishing client-server communication, etc. I am also
working on a query optimizer for Niagara based on Opt++, but
this part is still in early development, and it is not yet part
of the Niagara code base.
NiagaraServer.cpp contains the main function that puts everything
together and is the main function of the entire Niagara project.
Next, I describe the functionality of the "server" module.
The server has two jobs:
- Establishing and maintaining communication with the clients
(connection management).
- Processing requests from clients (request handling).
Connection management is handled by the files in ./Server. The classes
responsible for connection management are "class Listener" and "class
ConnectionManager." Client request handling is handled by subclasses from
the abstract class "class ClientRequestHandler," which is defined in
./Common. ./Server also has a "class NiagaraServer" which encapsulates all
objects related to a server.
class Listener (Listener.h, Listener.cpp) is a listener thread that listens
for connection requests from clients on a TCP socket. Currently it accepts
all connection requests, but it provides a framework for accepting or
rejecting connections that may be useful for authentication or load
control. To accept a new connection, the listener calls
ConnectionManager::newConnection (TCPSocket &listenSocket), which handles
accepting the connection from the client. This function executes in the
listener thread. The job of the Listener class is thus only to listen for
new connection requests, not to accept them.
The listener has dependencies on two classes through the pointer members
"NiagaraServer* const niagaraServer" and
"ConnectionManager* const connectionManager." "niagaraServer" is a pointer
that points back to the NiagaraServer object that creates and encapsulates
this listener. This pointer is not currently used. "connectionManager"
points to the connection manager which the listener calls to accept
client connections. The listener also needs to know the hostname and
port on which it should listen.
class ConnectionManager is responsinble for all connection related
activities. It keeps a list of all clients currently connected to the
server, creates connections, ends connections, etc. When a new client
connects to the server, the connection manager newConnection method accepts
the connection request, creates a client request handler for the client,
and adds this client request handler to the list of connected clients (more
on client request handlers later). When a client disconnects, it is
removed from the list of connected clients. The connection manager class
owns and manages the list of connected clients and provides functionality
to accept and end connections, as well as a place where we can do
authentication and load control. The connection manager class is also a
thread. The connection mamanger thread is simply a garbage collector that
waits on a semaphore. Whenever this semaphore is signalled, the thread
wakes up and traverses the list of connected clients to see if there
are any clients that have disconnected but are still on the list.
The connection manager thread is currently never woken up, because it turns
out that client request handlers can always detect when a client has
disconnected and do an orderly disconnect.
Each client has an associated client request handler, which is a thread
that listens to service requests (e.g., queries) from the client and
processes them. The "server" does not know about the "service" being
provided. This "service" is encapsulated in the client request handler.
Right now, the only service provided is a Niagara query engine that accepts
XML-QL queries and processes them. We can use the same server to implement
different services. For example, a stand-alone search engine or data
manager. This would simply require defining a new type of client request
handler. This will be very useful for, say, building a distributed version
of Niagara.
Client request handlers are sub-classed from the abstract
"class ClientRequestHandler", defined in ./Common. To create a
new client request handler, we must provide "Run" and "shutdown" methods
for this class. We must also define a new element in the enumeration
NiagaraServices, also defined in ./Common.
When we start a server, we tell it what service it should provide. We also
give it a void* to an object providing this service. The server does not
need to know what this object does. When a client connects to this server,
we create the correct client request handler according to the service type:
switch (serviceType){
case XMLCLIENT_SERVICE:
crh = new XMLClientRequestHandler(listenSocket,this);
break;
case ..other service..:
crh = new ..other client request handler ..;
break;
...
}
Currently, there are two client request handlers, both defined in
./ClientRequestHandlers. The first is DummyClientRequestHandler.h and cpp.
This is just an example client request handler. The "service" it provides
is echoing back the text line taht it receives from the client in reverse
order.
The remaining files in the ./ClientRequestHandlers directory define the
XML client requst handler, which implements the Niagara query processing
protocol.
The final class of the Niagara server is "class NiagaraServer," which
contains the listener and client request handler. The server also has
a shutdown thread, which is woken up when the server terminates so that
any clean up can be done in its context.
Error reporting in the server is done by throwing exceptions. The exception
class is defined in ./Common.
The server uses the CommonC++ package for communication, synchronization,
and threads. I have several reservations on the design of CommonC++, but
it does make the job much easier.
An issue that is closely related to the Niagara server is how client
queries are processed in the query engine and how results are sent back to
the client. In particular, classes XMLQueryProcessor and XMLHeadProcessor.
These classes were written by other people, so they can describe them
better. However, if you would like me to, I can certainly send you a note
about them.
As I mentioned to you in an earlier message, I was pretty busy for
a while. I will have more time to work on Niagara now, and the
order of business for me is (in this order)
- Getting the client-server story fully working, especially with triggers.
- Writing a text based client so we do not always have to use the GUI.
- Testing Niagara with randomly generated data and large queries on this
data.
- Niagara query optimizer.
This section describes the Niagara Data manager.
The DM module parses raw xml files (text files) and stores the
parsed tree in database. Currently it uses Berkely DB package.
Query Engine
---------- XNode Interface -----------
DM
DM provides the XNode interface for upper layers of Niagara.
The XNode interface is defined in XNode.h
XNode.h
- DataManager
- Abstract Base Class. Provides interface for
Document level manipulation, for example,
createDocument,
getNode, (get an XNode)
getNodes, (get a vector of XNodes)
It also provides methods to manipulate at node level, for example,
parentNode(), childNodes(), (all children), etc.
These node level method is wrapped in XNode class, so modules
on top of DM only need to use XNode class.
- XNode
- Wraps over DataManager class. Provide DOM-like interface
XxNode.h and XxNode.cpp
- _Xx_DM (sub-class of DataManager)
-
Contains routines common to all DataManager subclass.
It is still abstract.
These common methods are implemented in XxNode.cpp
XvNode.h and XvNode.cpp, DMParser.h DMParser.cpp xv_util.h,cpp
- DMParser:
- DMParserHandler:
- Extends Xercesc parser, handler. Parses a raw XML file into
a in-memory format. The in-mem format is managed by a _Xv_DM
instance.
- _Xv_DM (Subclass of _Xx_DM)
-
In-memory implementation of DataManager. Manages parsed raw
XML file.
XbtNode.h,cpp db_util.h,cpp
- _Xbt_DM (Subclass of _Xx_DM)
-
On-disk implementation of DataManager. It starts a _Xv_DM as
one of its member data, the _Xv_DM handles the parsing job, and
parsed result is dumped into _Xbt_DM
- db_util.h,cpp
- Berkey DB utility. One could replace BerkeyDB with any B-tree
implementation (Shore, Relational DB etc)
im_util.h, cpp
DM depends on IM. The 2 files wraps IM method. Several
macro is defined so that one could start a fakeIM to unit
test DM without IM.
dm/test directory contains unit test program for datamanager.
Known Design Problem, Error, etc.
- The berkely db should be completely contained in some abstract
layer. Unfortunately, the header files had spreaded out to several
places.
- Due to incomplete support of transaction/thread of BDB, the transaction
semantics is "One writer, file-level, query processing readonly".
Need to rethink this and how Shore fits in the transaction picture.
- Now, an XML file is first parsed into memory, then stored to disk.
For a huge xml file, (SWISS_PROT), this will probably exhause available
memor. I will work on a SAX based parser or load-file generator.
- Now im/dm XML Element ID agrees on an "implicit protocal". This may
or may not cause trouble later.
Info about the Query Engine . (v 0.01)
The QueryEngine is among the components that has the most hangover from
the java version. This was probably because I felt the java stuff was
pretty ok. There are however a few changes and hopefully this would document
them.
The QueryEngine is responsible for executing the query so It parses a
given query, generates a logical plan, physical plan and schedules the
operators.
The Query Engine has a thread pool of query threads and operator threads.
Query threads pick up queries from the query queue and convert them into
a executable form ( a set of operators connected by streams) and puts the
operators into the operator queue which the operators threads will execute.
Queries can be submitted in the form of a string or a logical plan (usually
used by the trigger system). A QueryInfo object is created with necessary
information and is pushed into the query queue.
Query processing is abstracted by the query processor class.
The Query threads pick up the query info object from the queue and
obtain the query processor required to process this object from it
and call the execute method. So the query thread is not aware of
the actual query processing code. If you want to do something else
with a query (say just generate statistics ), you should put a appropriate
query processor object in the query Info. The default behaviour of
executing the query is encapsulated by the class SimpleQueryProcessor.
Every physical operator tree has a head operator at the root which
does some cleanup and also decides what to do with the result tuples
that it sees. This functionality is captured by the base class HeadProcessor.
SimpleHeadProcessor is the default behaviour that just prints the tuples
to stdout. Another subclass takes care of communicating results to the
client.
Some stuff about object deletes which was decided by a few of us.
- The QueryThread deletes the QueryProcessor even though it dosent
own it.
- The HeadOperator deletes the headProcessor even though it dosent
own it.
ActiveQueryList is a class that maintains the current list of queries
in the system. It uses STL hash_map to keep track of this information.
I am not sure If I have used this in the best possible way.
That was a broad overview of the Query Engine. These are some general
issues in my mind ..
- Query Engine uses JTC threads, should be re-written with a generic
threads package so that it is package independent.
- There is no provision to increase the number of running threads in
the thread pool. ( prob. not an issue currently)
- Lack of notion of memory for a query. We leave all queries to run
in the mercy of virtual memory. you mentioned paradise having
some notion of memory estimates. we need something similar ?
This also means that operators should have a memory parameter,
now all algorithms like hash join ,nested loops etc work in
a main memory environment.
- HTTPUtils was a wrapper class that I wrote for downloading urls
as part of the crawler which sekar put temporarily in this
directory to support getDTDs() function. This has to move to a
utils directory from it can be used wherever needed ( i believe
the event detector also has something similar) and the code is
just C code with stuff like AF_INET etc all over the place, so
it should be rewritten using something like Common C++
- QueryResult was supposed to be the object to encapsulate the results
which was inherited (read copied) from the java version. It was
easy to use in Java as you could just push objects down the wire.
I think this should go.
- Time.hh has a routine that gets the current time in milliseconds
This is used to measure the running time of the query. I think
the index mgr has a similar routine. So another candidate for utils.
- Code as such, I am sure it has much to benefit from the "Bolo list"
some places where the code is bad is in simplequeryprocessor.cc where
the main function is one piece of code. Should break things into
functions. Need to carefully work with destructors. The Query Engine
test program not exiting correctly has its source somewhere here I think.
QueryInfo is a mess, I started coding by making everything public and
thinking I would return for an interface cleanup after the stuff works.
I just havent got to it.
- Some data members in query info that really provide no information
and have to go.
- A Query should sometime in the future execute as a transaction
whether it does it thro libdb nested transactions as they have
no support for Xacts across threads or using shore, I think somehow
we need to design a generic interface that we can use and which can be
implemented using anything underneath.
More to come ..
Streams , Operators , Crawler , Opt++ ...
Overview on Event Detector
Event detector is a part of the continuous query (or trigger)
system. It maintains all trigger events and monitors change over
source files and web pages.
How does it work?
When a user submits a cq, the trigger manager splits it up into
several small triggers and add them to the event detector. The
information required by the event detector includes:
- Trigger Id.
- Source files -- a list of file names on which the trigger will be evaluated. They can be either local (intermediate) files or web pages.
- Starting time -- the trigger's first scheduled evaluation time.
- Interval -- the time between the trigger's consecutive evaluation.
- Expire time -- the time on which the trigger will be deleted from the system.
The event detector first determines whether the source files are
web pages or intermeidate files. Intermediate files are query result
of a lower-level trigger, and its change can be pushed to the event
detector. If the source files are web pages, the event detector will
ask the data manager to load them.
According to triggers' interval information, they are divided into
two groups, change-based whose intervals are equal to zero, and
timer-based (non-zero intervals). On the other hand, since triggers'
source files are either push-based or pull-based, there are totally
four kinds of triggers.
- Timer-based triggers whose source files are pull-based.
- Timer-based triggers whose source files are push-based.
- Change-based triggers whose source files are pull-based.
- Change-based triggers whose source files are push-based.
In general, Timer-based triggers are stored in a list, the event
list, which is sorted on triggers' next evaluation time. Change-based
triggers are stored in another list, the push_trigger group. There is
a default system trigger on the event list, which monintors all
pull-based files that are used by change-based triggers. So whenever
it finds that a file is modified, it will notify all change-based
triggers which rely on that file.
On the event list, each event, associated with a time, contains
triggers whose next scheduled evaluation time is the event time. On
the event time, the file change detector will check all source files
contained in this event and compute difference if there're
changes. Then the event detector will notify the trigger manager to
evaluate those triggers whose source files are changed.
For a trigger whose file change can be pushed to the event
detector, if it timer-based, the event detector will only notify the
trigger manager at the scheduled evaluation time; otherwise, the
notice will be sent whenever the event detector receives change.
Description of major classes
TriggerManager
| \
+---------------------------+--------+----------------+
| Event Detector | \ |
| | \ |
| EventDetector --- FiredTriggers |
| EventDetector --- FiredTriggers |
| / \ / |
| / \ / |
| / \ / |
| FileChangeDetector EventList |
| | FileTriggerGroup |
| | FileTriggerGroup |
| XDiff |
| | \ +-------------------------------+
| | \ |
| XHash +--+------ DataManager
| |
| |
+---------------------+
- EventDetector
- EventDetector administrates all trigger events. It detects change
on data source, generates delta files and notifies TriggerManager of
evaluating continuous queries.
- EventList
- EventList is a sorted list of events according to their
time. Basically, every timer-based trigger (in pull-model) will be put
on this list. At each event time, all related files of triggers on
that event will be checked. The current event will be removed from the
head of the list, and its triggers will be inserted back to the list
according to their interval, i.e., at position - current_event_time +
inverval.
- FileChangeDetector
- FileChangeDetector monitors triggers' source files. It checks last
modified time of files (either webpages or local files). If the page
or file is modified since last checking, or it doesn't provide
"Last-Modified", FileChangeDetector will retrieve a copy and call
XDiff to compute difference.
- FileTriggerGroup
- FileTriggerGroup contains all files that are monitored by
EventDetector. Each file is combined with ids of its related
triggers. Whenever, a file is modified, you can easily get all
triggers which need to be evaluated.
- FiredTriggers
- FiredTriggers is used in communication between EventDetector and
TriggerManager.EventDetector puts triggers that are to be evaluated
into an instance of FiredTriggers and passes to TriggerManager.
- TriggerList
- TriggerList is one of several data structures maintained by the
EventDetector. It is a hashmap in which the hash key is trigger id.
Each trigger is associated with two pieces of time information, the
last two evaluation time, and its source file list.
Notice, a trigger's evaluation time is actually the time when
EventDetector finds out some of ifs source files have been modified
and it should be sent to TriggerManager to be evaluated. The delta
source files are computed from the version of last evaluation time
and the current one. That's why we should keep these two evaluation time.
- XDiff
- XDiff computes the difference between two XML documents stored in
the data manager. The difference is saved in the third document. Due
to the query evaluation methods used in query engine and trigger
manager, all difference is restricted on the second level, i.e., a
second-level subtree is kept in the diff result if and only if there
are changes within the subtree.
- XHash
- XHash is in charge of computing hash values for each node
(attribute) in XML documents and converting the hash values into
string (if necessary), which will be stored in the data manager as
"UserData" defined in DOM.
So far, XHash employs a very simple (and high collision ratio) hash
function that is from STL's hashmap. For each string, the hash function
returns an integer, and in general, the hash value of a subtree is
Sum(hash values of all child nodes and itself) mod A_BIG_PRIME.
In the near future, it will be replaced by an MD5 or DES function.
I am sending a brief description of some parts of the system on
which I worked. There are some documents in the qe/Parser directory that
will complete this description. These are mentioned in the following
description
Brief Description
A brief description of the class hierarchy used in the Parser is in
the qe/Parser directory as a Readme file. The class hierarchy is
graphically represented in Parser.ps and a sample query covering most
of the classes is in Query.ps
src/qe/Parser/Readme
A brief description of the various classes follow:
- XmlqlExt
- Base class for all xmlql queries
Subclasses are
XmlqlQuery ... an Xmllql query;
XmlqlSeql ... an Seql query;
XmlqlTrigger ... Trigger query.
- XmlqlQuery:
- represents an XMLQL query. It has a constructquerylist member
which represents the entire query.
- ConstructQueryList:
- It is a list of XMLQL queries, each with its own where and
construct clause.
- Query:
- Represents a single XMLQL query. It has a list of where
clauses and a construct clause.
- Where:
- It represents the Where clause and can either be a pattern,
restriction or predicate.
Subclasses are WherePatter, WherePredicate, WhereRestrict.
- WherePattern
- represents a pattern in the where clause which
matches an xml fragment in a document (or previously defined pattern)
and conforms to a dtd
- WherePredicate
- represents a condition in the where clause eg.
- WhereRestrict
- represents a restriction in the where clause
eg. $v in {$v1, $v2}
- Pattern:
- Represents an element in the where clause. It may have
sub-elements, attributes and bindings to variables.
- Attr:
- Represents an attribute and its value
- Construct:
- The construct part with an optional oreder_by clause
- ConstructBase:
- The actual construct part
subclasses: ConstructLeaf, ConstructQueryList, Element
- ConstructLeaf:
- Creates a leaf node e.g. string type, or
variable construct
- ConstructQueryList:
- Construct has a list of queries in it
- Element:
- The most common type. Constructs an element, with
sub-elements, attributes and skolems
- DataNode:
- represents a leaf node, like variable, string, id ...
- Condition:
- represents either a search-engine operator, arithmetic condition,
boolean condition or data node.
src/qe/Parser/Parser.xfig
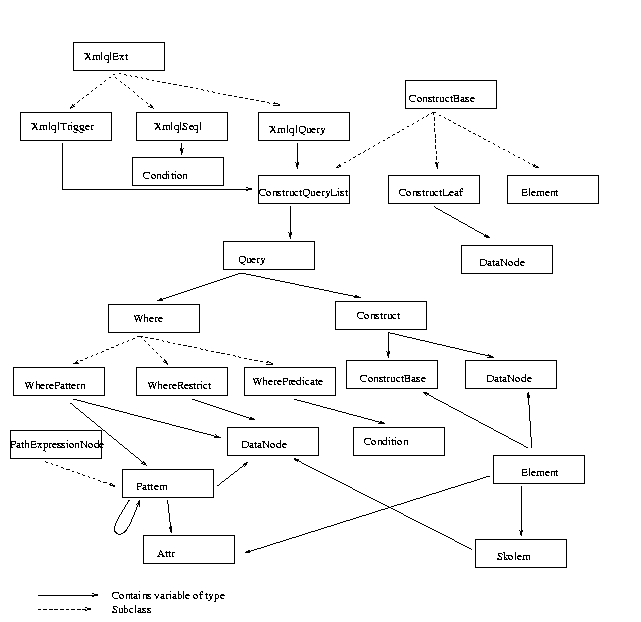
The Parser
src/qe/Parser/Query.xfig

The Query
Some observations about the parser
- Use the Parse class to access the parser. It takes in a file
containing the query, parses it and returns a AST.
- The query language is a combination of XML-QL and SEQL, with a SEQL
fragment allowed after each element in the Where clause. Look at the
grammar production for SEQLFragment in xmlqlparse.yy for more details.
- Lex and Yacc seem to have different approaches to support reentrant
parsers. While lex allows a mechanism to define C++ classes, Yacc has
a different approach and changes the interface in a different way. The
current solution has a monitor in the parser class and serializes the
parser operation.
- Exception handling doesn't work correctly. The Parse class and
xmlqlparse.yy need to be modified once this problem is fixed.
Testing the entire system
The current testsuite is in qe/testSuite. It currently allows testing
one or more queries which can be optionally validated with expected
results. There are 16 standard queries for the imdb database.
The test program does not sort the results before comparing with
existing results. Though, the results should arrive in the same order
every time, it may change if the operator implementations are
modified. So, a sorting routine needs to be added so that it works in
the general case.
Bolo Documentation
Bolo's Home Page
Last Modified:
Thu Apr 19 11:15:48 CDT 2001
Bolo (Josef Burger)
<bolo@cs.wisc.edu>