The implementation uses a history structure, which maintains information about the order pages were seen in. There is one history structure shared and updated by all the users of a given proxy. Gif files are not included in this history, as they are considered to be sub parts of html pages.
The history structure is a forest of trees of a fixed depth K, where K>m. This history encodes all dynamic sequences of accesses (by any one user) up to a maximum length K. One root node is maintained for every page seen, and in this node is a count of how often this page was seen. Directly below each root node are all pages ever requested immediately after the root page and a count of how often the pair of requests occurred. The next level encodes all series of three pages and a count of how often this particular sequence of three pages occurred. This is continued to the K-th level.
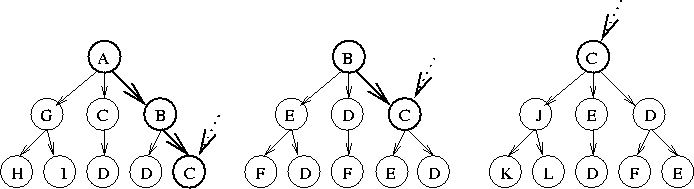
Every time a user makes a request for a page the history structure is updated. For each user there is a list of the last K pages the user requested (this can be maintained as a list of pointers into the history structure). The update involves incrementing counters and possibly adding new nodes to the history structure. Each update involves changing one node at each level of the history structure. Figure 6 shows an example of the history structure. In this example K=3, and the structure is being updated after a user accesses page C following accessing pages A and B. The sequence ABC is updated, with the counters for A and B and C incremented. The sequence BC is updated and so is the sequence C.
Encoded into the history structure is the observed relative probability of what page will follow a given sequence of references. This can be calculated by following a given sequence through the history structure and then looking at the relative counts of all nodes immediately following that sequence. The probability of a node following another node is the ratio of the count of the child to the count of the parent.