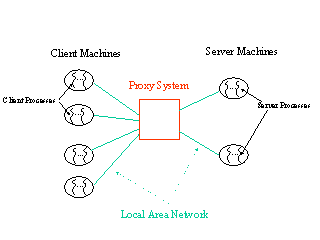
Design of WPB 1.0
The general setup of the benchmark is that a collection of Web "client" machines are connected to the proxy system under testing, which is in turn connected to a collection of Web "server" machines. There can be more than one client or server processes running on a client or server machine. The client and server processes run the client and server codes in the benchmark, instead of running a browser or a Web server. The client is configured to send HTTP requests to the proxy. The above figure illustrates a typical benchmarking setup.
Master Process
A master process is needed to coordinate the actions of client
processes. Once a client process starts, it sends an "ALIVE" message
to the master process, and then waits for a "GO" message from the master.
Once it receives "GO", it starts sending HTTP requests to the proxy as
described below. The master process waits till all client processes
send it the "ALIVE" message, then sends "GO" to all clients. The
number of client processes that the master has to wait for is given in a configuration
file, whose name is passed as the command line argument to the master process.
The third line in the configuration file specifies the total number of
client processes involved in the benchmarking run. Once the master
process finishes sending "GO" messages, it exits.
Client Process
The client process runs on the client machine and issues HTTP requests
one after another with no thinking time in between. The client process
takes the following parameters as command line arguments: URL address of
the proxy server (e.g. cowb05.cs.wisc.edu:3128/), number of HTTP requests
to issue, seed for the random number generator, and name of the configuration
file specifying the Web servers to which the client should send requests.
The configuration file specifies the following: the machine where the master process runs, the port number that the master process is listening at, the total number of client processes, the total number of server machines, and the specfication of the server processes for each server machine. The specification of the server processes includes the name of the server machine, the base port number, and the number of ports at which there are server processes listening. For example, if the specification is "cowb06.cs.wisc.edu 8000 10", it means that there is a server process listening at each of the ports 8000, 8001, 8002, ..., 8009 on cowb06.cs.wisc.edu. This way one server machine can host more than one server processes.
Currently, the clients send HTTP requests in the format of "GET http://server_name:port_number/dummy[filenum].html HTTP/1.0", for example, "GET http://cowb06.cs.wisc.edu:8005/dummy356.html". The server_name, port_number and filenum vary from requests to requests. Clearly, our client code does not yet include other types of HTTP requests or HTTP 1.1 persistent connection. We plan to fix it soon, once we learn more about the typical mix of HTTP requests from the clients and the characteristics of most persistent connections.
The client process varies the server_name, port_number and filenum of each request so that the request stream has a particular inherent hit ratio and follows the temporal locality pattern observed in most proxy traces. The client process sends requests in two stages. During the first stage, the client sends N requests, where N is the command line argument specifying the number of requests need to be sent. For each request, the client picks a random server, picks a random port at the server, and sends an HTTP request with the filenum increasing from 1 to N. Thus, during the first stage there is no cache hit in the request stream, since the file number increases from 1 to N. These requests serve to populate the cache, and also stress the cache replacement mechanisms in the proxy. The requests are all recorded in an array that is used in the second stage.
During the second stage, the client also sends N requests, but for each request, it picks a random number and takes different actions depending on the random number. If the number is higher than a certain constant, a new request is issued. If the number is lower than the constant, the client re-issues a request that it has issued before. Thus, the constant is the inherent hit ratio in the request stream. If the client needs to re-issue an old request, it chooses the request it issues t requests ago with probability propotional to 1/t . More specifically, the client program maintains the sum of 1/t for t from 1 to the number of requests issued (call it S). Everytime it has to issue an old request, it picks a random number from 0 to 1 (call it r), calculates r*S, and chooses t where sum(1/i, i=1,...,t-1) < r*S < sum(1/i, i=1, ..., t). In essence, t is chosen with probability 1/(S*t).
The above temporal locality pattern is chosen based on a number of studies on the locality in Web access streams seen by the proxy. (We have inspected the locality curves of the requests generated by our code and found it to be similar to those obtained from traces. ) Note here that we only capture temporal locality, and do not model spatial locality at all. We plan to include spatial locality models when we have more information.
Finally, the inherent hit ratio in the second stage of requests can be changed through a command line argument. The default value is 50%.
Server Process
The server process listens on a particular port on the server machine.
When the server receives an HTTP request, it parses the URL and finds the
filenum. It then chooses a random number (according to a particular
distribution function) as the size of the HTML document, and forks a child
process. The child process sleeps for a specified number of seconds,
then constructs an array of the specified size, fills the array with string
"aaa[filenum]", replies to the HTTP request with the array attached to
a pre-filled response header, and then exits. The response header
specifies that the "document" is last modified at a fixed date, and
expires in three days. The server process also makes sure that
if it is servicing a request it has serviced before, the file size and
array contents stay the same.
The sleeping time in the child process models the delay in the Internet and the server seen by the proxy. We feel that it is important to model this delay because in practice, latency in serving HTTP requests affects the resource requirement at the proxy. Originally, we set the sleeping time to be a random variable from 0 to 10 seconds, to reflect the varying latency seen by the proxy. In our preliminary testing, in order to reduce the variability between experiments, we have change the latency to be a constant number of seconds that can be set through a command line argument. We are still investigating whether variable latencies would expose different problems in proxy performance from constant latency. For now, we recommend using a constant latency (see below, benchmarking rules).
Currently, the server process does not support other types of GET requests, such as conditional GET, which we will fix soon. The server process also gives the fixed last-modified-date and time-to-live for every response, which would be changed as we learn more about the distribution of TTL in practice.
The file size distribution coded in the server program is very primitive. It is basically a uniform distribution from 0 to 40K bytes for 99% of the requests, and 1MB for 1% of the requests. We are just using this distribution for our testing purposes, and the code can be easily changed to reflect a more realistic file size distribution, which would be included in the next version of the server code.
Recommended Benchmarking Steps and Rules
The setup of the benchmarking experiments should follow the rule that
the ratio between the number of client machines and the number of server
machines is always 2 to 1, and the ratio between the total number of client
processes to the total number of server processes is also kept at 2 to
1. (Until we have a better understanding of the spatial locality
in user access streams, the 2 to 1 ratio is a reasonable choice.)
Each run should last at least 10 minutes, and the total size of HTTP documents fetched by the clients should be at least four times the cache size of the proxy.
The benchmarking has two steps:
1. Configure the proxy to be no caching. Set the server latency
to be 3 seconds. Increase the number of client processes and correspondingly
server processes, and measure the average latency and 90 percentile latency
seen by the client.
The number of client processes should be increased to the point where
the average latency starts to increase linearly or the number of connection
errors from the client to the proxy becomes significant, that is, the saturation
point for the proxy system.
2. Configure the proxy to perform caching. Keep the server latency
at 3 seconds. Vary the client and server processes as before, and
measure the average and 90 percentile latency seen by the client, the hit
ratio and byte hit ratio of the proxy cache, and the number of connection
errors.
Report:
1. the average latency, 90 percentile latency and error count curves,
for no-caching and caching configuration;
2. the hit ratio and byte hit ratio curves;
3. a summary finding in the form of the following statement: "the proxy
system can adequately support x number of concurrent clients with an average
latency saving of y% when server latency is 3 seconds and a hit ratio of
z% when the maximum achievable hit ratio is 50%."
Limitations in WPB 1.0 v1
The benchmark code currently does not model:
. DNS lookups;
. HTTP 1.1 persistent connections;
. conditional GET and other forms of HTTP requests;
. spatial locality in Web accesses (i.e. once a user accesses a document
from one Web server, it tends to access other documents at the same Web
server);
. realistic path name for URLs;
We are continueing the development of the benchmark and hope to eliminate these limitations in future versions of the benchmark.
Acknowledgment
Qinqin Wang, Dan Yao and Wei Zhang implemented version 0.1 of the Wisconsin
Proxy Benchmark. Our work benefited significantly from their experience
in testing proxy software.