
![]()
|
Overview of Single-User MinibaseIt is easiest to understand Minibase in terms of how a query is processed. A query is first parsed and optimized to obtain an evaluation plan. The evaluation plan is structured as a tree of iterators, each of which supports a ``get-next-tuple'' interface, and corresponds typically to a relational algebra operator. Execution is initiated by calling get-next-tuple at the root of the plan tree, which successively generates get-next-tuple calls on descendant nodes. Execution consists essentially of a data-driven loop of such calls until all the input tuples have been processed. This is described below in more detail. (Only single-user Minibase is covered in this overview---in fact, only single-user Minibase is available for now, and most likely, for a while yet!)
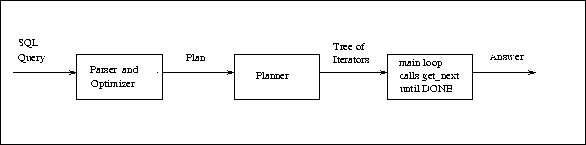
Parser and Optimizer: These modules take an SQL query and find the best plan for evaluating it. The optimizer is similar to the one used in System R (and subsequently in most commercial relational database systems). In optimizing a query, the optimizer considers information in the catalog about relations and indexes. It can read catalog information from a Unix file, and thus the parser/optimizer can be used in a stand-alone mode, independent of the rest of Minibase (say, for optimizer related exercises). Execution Planner: This module takes the plan tree produced by the optimizer, and creates a run-time data structure. This structure is essentially a tree of ``iterators'', each of which supports a ``get-next-tuple'' interface. Tuples are returned in response to get-next-tuple calls by copying them into dynamically allocated main memory (not the buffer pool). The figure below shows details of iterator trees and the Minibase code that they call.
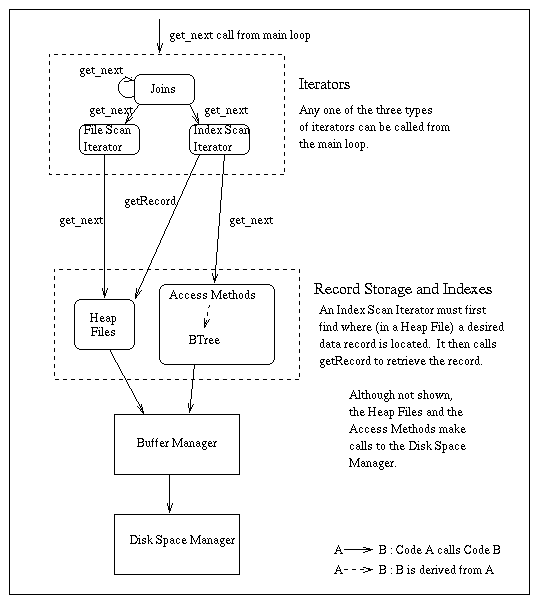
Main loop: Execution is triggered by ``pulling'' on the root of the tree with a get-next-tuple call. This results in similar calls to iterators lower in the tree. Leaf level iterators retrieve tuples from a relation (perhaps using an index), and intermediate level iterators in the tree correspond to joins. Selections and projections are ``piggy-backed'' onto these iterators. More information is available on each of these components: Iterators A ``get-next-tuple'' interface for file scans, index scans and joins. Join Methods Nested loops, sort-merge and hash joins are supported. Heap Files All data records are stored in heap files, which are files of unordered pages implemented on top of the DB class. Access Methods: Currently only a single access method is supported, B+ Trees. The access method in Minibase is dense, unclustered, and store key/rid-of-data-record pairs (Alternative 2, in terms of the text). Data records are always stored in heap files, as noted above, and access methods are implemented (like heap files) as files on top of the DB class. Buffer Manager: The buffer manager swaps pages in and out of the (main memory) buffer pool in response to requests from access method and the heap file component. Disk Space Manager: A database is a fixed size Unix file, and pages (in the file) on disk are managed by the disk space manager.
Click here to go the Minibase Home Page
|