Secondary crashes are one of the major crash types (in terms of the cause of a crash) on interstate highway systems. A secondary crash generally occurred in the queue triggered by a primary incident at a downstream location. Secondary crashes prolong the impact of the primary incidents and degrade both the safety and the efficiency of highway facilities. As a result, countermeasures are desired in reducing the chances of encountering a secondary crash after a primary incident (narrowed down to crash in the following discussion). Such countermeasures could be effectively developed based on analyses of historical crash data. One of the major challenges in analyzing historical crash data is to identify secondary crashes, since explicit information is not always available to indicate whether a crash was secondary or not.
The first step of identifying a secondary crash is to examine whether two crashes were close enough to each other in time and space. If they are, the later crash was potentially a secondary crash of the earlier one. A crash might have caused more than one secondary crash. Literatures have shown many alternatives of judging the closeness between two crashes, and were mainly divided into two categories: 1) static methods and 2) dynamic methods. Static methods use a fixed time threshold (typically 1 hour) and a fixed distance threshold (typically 1 mile) to scope potential secondary crashes of a given primary crash. For example, say given a primary crash Cpri, one identifies a potential secondary crash Csec_i when the highway distance between Cpri and Csec_i is no larger than 1 mile and Csec_i occurred less than 1 hour after Cpri happened. Dynamic methods are similar in concept but prefer to use dynamic distance threshold as time changes. A representative of these dynamic methods is the "progressive curve" proposed by Sun, et al (2006). A "progressive curve" describes the queue length as a function of time, ranged from the occurrence of a primary crash to its full clearance. A "progressive curve" is typically a parabolic-shape curve with a peak. All crashes plotted under the curve are considered secondary crashes of the primary crash.
Static or dynamic, the first step just provides an input to human reviewers to eventually identify actual secondary crashes base on human-but-not-machine readable crash descriptions. Even though, under a computer program's help, the first step significantly reduces human reviewing efforts by filtering out a large portion of the crash base. The rest of this document tries to show an upstream traversing algorithm of finding potential secondary crashes of a primary one, adopting a pair of fixed time and distance thresholds (static method).
The choice of algorithm highly depends on what data are available. The current study is supported by the WisTransPortal database system, which contains the state trunk highway network (STN) data (updated to 2011) and the crash records (dated from 1994) for the state of Wisconsin.
The STN data in WisTransportal database consists of a couple of tables. The major tables used for the proposed algorithm are the table of highway reference sites (REF_SITE table), the table of highway links (LINK table), the table of highway routes (RTE table), and the "joined" table of highway link and route (RTE_LINK table). Highway reference sites are reference locations on highways (square-numbered nodes in Figure 1). A highway link is then defined by a "from" reference site and a "to" reference site with direction, representing a uniform segment of highway (any circle-numbered solid arrow in Figure 1). A highway route consists of a sequence of successive highway links (rectangle-labeled dash arrow in Figure 1). For each route, along its traveling direction, the links are sorted by a route_link_sort number. A link's route_link_sort number is smaller than any of its downstream links on the same route, and larger than any of its upstream links on the same route. The circled numbers in Figure 1 can be treated as route_link_sort numbers for illustration purposes (but are actually link ID's). A distinction has to be made here that, a link ID is not a route_link_sort number. One link must have exactly one link ID, which is a unique and unreusable integer. On the other hand, a same route_link_sort number may be used by two different links on different routes, and a link can have different route_link_sort numbers on different routes.
For each crash happened on STN, there is a record in the WisTransPortal database, recording information that includes but not limited to crash date, crash time, link on which the crash happened, and the offset between the link's "from" reference site and the crash location. Figure 1 shows a red star shape to indicate a crash happened on link 3 with a certain offset to the "from" reference site 38.
The problem here is (looking at Figure 1 again), given a crash, how could we find all the links that are partially or totally within an upstream highway distance to the given crash. Upstream includes both directions of the highway (as illustrated in Figure 1). To give a concrete example, in Figure 1, assume links 1, 2, 3, 4, 7, and 9 are each 1 mile long, and link 8 is 2 mile long. Further assume the crash is 0.3 mile offset from reference site 38. Given a highway distance threshold of 1 mile, the links to be found are links 2, 3, 4, 7, and 8, since these links are reachable from the given crash in 1 mile.
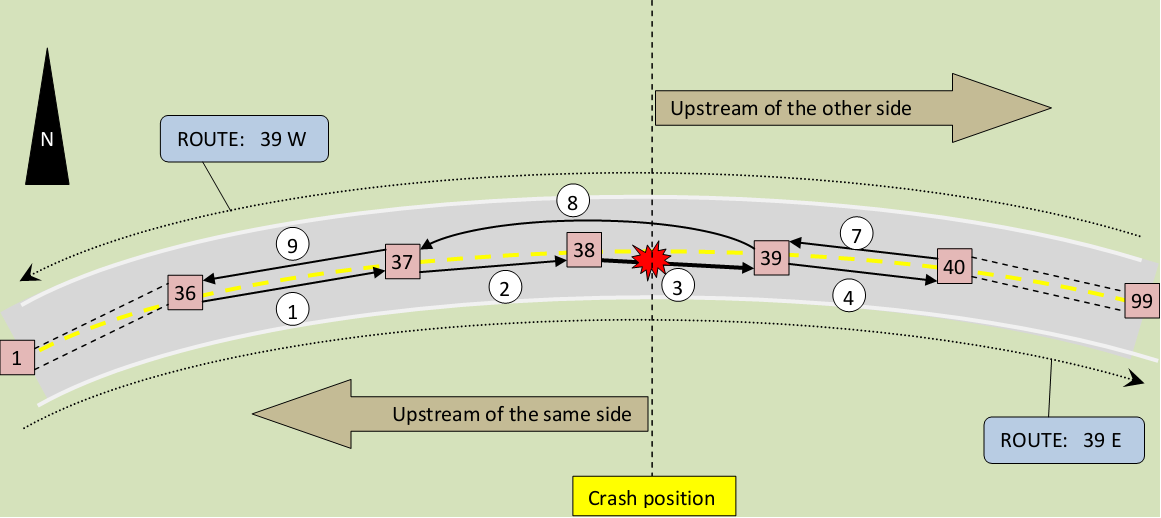
The idea of the algorithm is very straightforward: Given a crash Cpri, one finds the link (Lkpri) where the crash happened (like link 3 in Figure 1). Starting from Lkpri, there are two upstream directions to go. The first direction is upstream of all routes on the same side of and heading towards Lkpri (like route 39E in Figure 1). The second direction is upstream of all routes on the other side of the highway, heading to the opposite direction of Lkpri (like route 39W in Figure 1). The upstream traversals of these two directions are explained and pseudo-coded in the following subsections.
Before moving onto the algorithm, we define the following global variables that can be accessed by all functions:
result:dfilter:routesSameSide:routesOtherSide:The algorithm starts from Lkpri itself. The cumulative distance of Lkpri is the offset of Cpri minus the length of Lkpri. After that, all the routes that contain Lkpri are retrieved using the RTE_LINK table. For each of such routes (Rti), the algorithm calls a function upstreamSameSide(), which takes a route, the closest upstream link of Cpri in that route, and the corresponding cumulative distance of that link as inputs and recursively propogates the traversal to other merged-in routes and routes on the other side. The algorithm entry, initialization, as well as the triggering of successive recursive functions are pseudo-coded as below:
|
|
To handle a link link_cur from route route_cur that's on the same side of Lkpri, the following handleSameSide() function is used. This function first check if link_cur is of smaller cumulative distance than the distance threshold. If yes, the procedure continues, {link_cur, cum_dist_cur} is added to the result. After adding link_cur to the result, additional work has to be done in case link_cur's "from" reference site connects other upstream routes to be consider (e.g., merged-in routes or routes on the other side). In any of these cases, the link whose "to" reference site overlaps with link_next's "from" reference site will serve as a starting link of another execution of the upstreamSameSide() function, together with the route it introduces. The cumulative distance is updated correspondly.
|
To avoid redundancy, an item is added to the result only when its associated link is NOT YET in the result or the new cumulative distance is smaller than that of an old item with the same link. For the later case, the new item is not actually added, but is the old item updated with the new cumulative distance. This work is performed by using the following addToResult() function.
|
The traversing to the routes on the other side is triggered by the handleSameSide() function at a certain point. After started, the traversing works similarly to that of the routes on the same side. Below is the pseudo code for the upstream traversing of routes on the other side.
|
A minor difference here in function handleOtherSide() (compared to handleSameSide()) is that new routes are never intended to be explored across to another side (the "same side"). This is because routes on another side are either under traversal by the "same side" pass or contain no upstream links of the primary crash.
|
The above algorithm will terminate with a set of links together with their cumulative distances. Now the question is how to calculate the distance between any crash Ci and Cpri. The answer is as easy as one equation: