Using Priority to Increase Throughput of Explicitly Parallel Applications on SMT
|
Brian Fields |
Jim Gast |
Laura Spencer |
|
Computer Science |
Computer Science |
Computer Science |
|
Univ Wisconsin/Madison |
Univ Wisconsin/Madison |
Univ Wisconsin/Madison |
|
Madison, WI 53706 |
Madison, WI 53706 |
Madison, WI 53706 |
|
Fields@cs.wisc.edu |
jgast@cs.wisc.edu |
ljspence@cs.wisc.edu |
Abstract
Simultaneous Multithreading (SMT) improves instruction-level parallelism by augmenting it with thread-level parallelism. Estimates of the possible improvements are conservative, because previous studies assumed workloads with very little inter-thread interaction. This paper explores breaking down long tasks into short threads and pipelining those threads to gain greater thread-level parallelism. Kernels representing the seven major steps in delivering video teleconferencing are written as threads communicating through producer - consumer queues. Our goal is to balance threads so that communicating threads finish "just in time" to maximize the number of active, concurrent threads. SMT should also reduce the percentage of wasted instructions because of miss-fetches and wrong-path fetches to the extent that it prefers instructions that are less speculative.
Several priority mechanisms are examined which regulated the fetch mechanism and inserted differing instructions into the issue queue in an effort to meet our goal. Parallelism is measured based on Instructions Per Cycle using a simulation of an Alpha 21064, SMTSIM from UCSD.
Our results show that great care must be taken when breaking a large task down into component threads so that the threads are very nearly equal in duration. The differences we measured between the various priority mechanisms were small and unencouraging. We are still searching for a better way to improve parallelism.
Keywords: Simultaneous Multithreading, SMT, Priority, Thread-level parallelism
There are various existing synchronization mechanisms used in conventional as well as multithreaded environments. The most standard approach to synchronization has been the implementation of spin locks. This solution requires modification of memory and is a potential bottleneck in the case of simultaneous multi-threaded systems. In more modern approaches, lock-free synchronization has been implemented to block writes to a critical section. This idea could be adapted for use in simultaneous multi-threaded environments.
In the case of multi-threaded synchronization, a hardware-based implementation of traditional software blocking locks can be used [13]. These should give high-throughput with low latency by exploiting the close communication possible between threads on the same processor. It is important that this approach not consume processor resources while a thread is waiting for a lock, while retrying or spinning, waiting to retry.
These goals have been addressed in previous results synchronizing threads of programs for a simultaneous multi-threaded environment [6]. These simulations included lock-release prediction to minimize the cost of restarting threads. The results were highly sensitive to the exact synchronization mechanism and number of threads used.
Previous studies have assumed that large-scale internet servers will run general-purpose Operating Systems on commodity CPUs. Could we have higher-capacity and very high fault-tolerance if we didn’t make those assumptions? Previous studies [1,2,3] identified overheads in traditional OSes that contribute to lower than expected performance and scalability. This paper measured the potential of using Simultaneous Multi-Threading CPUs [6,7,8] as though they were Symmetric Multi-Processors. Embedded OS vendors are already converting their software to be SMP-aware for scalability and fault tolerance (independent of any progress on SMT CPUs) [4,5].
Our study assumed that poor ILP in SMT is sometimes due to having many threads blocked while waiting for input from other threads. We modified SMTSIM [11] to test our prioritization schemes. SMTSIM models an 8-wide SMT CPU using 2.8 fetching [7], but is otherwise very similar to the Alpha 21064. The test environment was actually a 21264 Alpha (paul.cs.wisc.edu).
1.2 Motivation for Priority
Simultaneous multi-threading improves throughput by increasing utilization of the machine by issuing instructions from different threads. Since these threads are guaranteed to be independent, this provides more exploitable parallelism. Fetch strategies evaluated to date [7] assume totally independent threads of computation during analysis. The metric of choice is instruction throughput for these independent threads. These analyses do not necessarily reflect the best fetch and execute strategies for explicitly parallel code.
Achieving high performance on an SMT processor running explicitly parallel code requires a good balance of work between the various threads. If one thread has much less work to do than the other threads, it will spend significant time waiting at barriers and locks. Yet, when an SMT processor is executing several threads simultaneously, it is usual for a particular thread to not perform as well as it would if it was executing alone. Thus, a thread that has a lot of work to do before the next barrier may be hampered by threads with little to do. Intuitively, it may be more efficient to give a higher priority to long threads dominating the critical path.
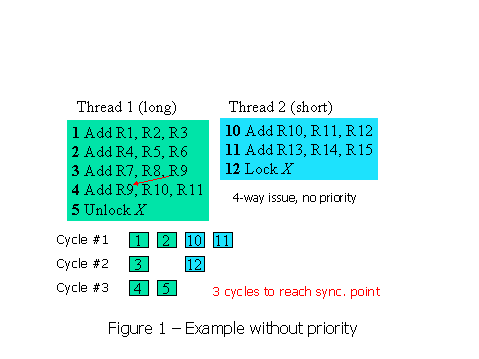
For an illustration of a situation where priority may have a possible performance improvement, refer to Figure 1. In this example, thread 1 has twice as many instructions to execute as thread 2 before reaching a synchronization point. In this example, each thread is given equal priority. An SMT is just as likely to choose instructions from thread 1 as thread 2. While thread 2 waits for a lock, it does not take up any functional units and it does not take up any space in the issue queue. This means fewer threads are able to issue instructions. This causes the average ILP to go down. Due to the dependence in thread 1 and the lack of work available from thread 2, the code sample takes three cycles to execute.
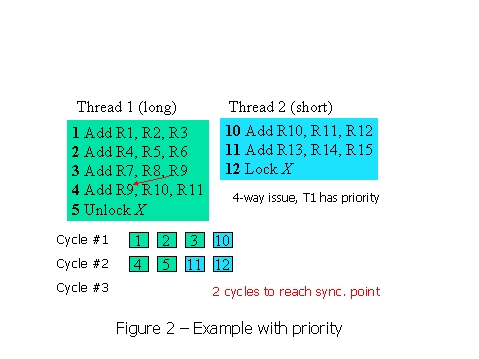
However, in Figure 2, thread 1 is given priority over thread 2. Permitting thread 1 to get more work done and exploit its own parallelism, results in allowing all four instructions to execute in two cycles. Thread 1 finishes sooner, and thread 2 is still not on the critical path.
This example is abstract and contrived. Achieving a performance improvement using real processor designs and real workloads is much more challenging. The question as to whether the above phenomenon can be exploited effectively on a larger scale is the central question of this project. We do not try to design a full system using priority, but only evaluate whether the idea has merit.
2.0 Possible Priority Implementations
To effectively support priority in hardware we need to apply priority to critical processor resources. Priorities should be most effective when used upon those resources contended for most by individual threads. The two critical resources chosen for study in this project were fetch bandwidth and issue bandwidth
2.1 Fetch Bandwidth
Fetch bandwidth has been recognized as a critical resource in SMTs [7]. The fetch policy determines the balance of instructions in the machine at any given time. Clearly this is a powerful mechanism for introduction of priority.
The danger in choosing a fetch policy that favors one thread over another, however, is that the benefits of SMT may be compromised. If one thread dominates the processor at any given point in time, the amount of available instruction level parallelism (ILP) may be insufficient to allow effective utilization of the machine. Thus, any fetch policy must be careful to balance the performance effects of priority and ILP advantages of SMT.
Two schemes were evaluated in this project: strict priority and fraction priority. The strict priority mechanism gives preference, each cycle, to the thread with the highest priority first, second highest priority second, third highest third, etc. A lower priority thread is allocated fetch bandwidth only if a higher priority thread cannot make use of it. This policy has the danger of losing the benefits of SMT if the highest priority thread takes up all of the fetch bandwidth.
Fraction priority, on the other hand, attempts to keep a desired imbalance of instructions in the machine. The number of instructions that have been fetched but not yet executed are kept in per-thread counters. The counters are examined every cycle in a manner similar to the usual ICOUNT strategy. The thread with a count farthest from its priority-weighted fraction of the machine is given highest fetch priority that cycle.
For example, if three threads (T0, T1 and T2) have priorities of four, five, and one, respectively, the desired imbalance is 4/ (4+5+1) = 0.4 for T0, 5/ (4+5+1) = 0.5 for T1, and 1 / (4+5+1) = 0.1 for T2. If the instruction counts are currently 25, 20, and 5 respectively, the current imbalance is 25/ (25+20+5) = 0.5 for T0, 20/ (25+20+5) = 0.4 for T1, and 5/(25+20+5) = 0.1 for T2. The difference between the desired and current imbalances are 0.4-0.5 = -0.1 for T0, 0.5-0.4 = 0.1 for T1, and 0.1 – 0.1 = 0 for T2. Based upon these numbers, T1 will have highest fetch priority this cycle, T2 will have second highest priority, and T0 will be third.
The hardware implementation of fraction priority would certainly involve some approximations and compromises in the arithmetic, but these could be made such that performance characteristics are near the ideal. Much of the complexity mentioned here will exist in fetch policies of SMT processors that do not implement priority thus the additional hardware complexity is not extreme.
2.2 Issue Bandwidth
In order to divide issue bandwidth, it is possible to consider issue stage analogs of the fetch mechanisms mentioned above. This would not, however, take advantage of the extra information available at this later stage in the pipeline. In addition, the worries concerning losing the benefits of SMT are less relevant when choosing instructions to issue than when choosing instructions to fetch. This is true because we are simply arbitrating among ready-to-issue instructions, issuing from lower priority threads if a higher priority thread has no instructions to issue in a particular cycle.
The mechanism we implement for this paper is countdown-to-rendezvous. Each thread is assigned a count equal to the number of instructions before the next synchronization point. For every instruction issued from a particular thread, we decrement the thread’s count. To determine a thread’s priority, we sort these count values. The thread with the highest count has highest priority. This mechanism always issues instructions from threads farthest from a synchronization point first.
There are at least two significant difficulties with this mechanism. First, it would be difficult to determine the count values accurately. Second, there is considerable complexity in such a circuit implementation. The latter problem is hard to analyze without closely exploring an implementation, and is irrelevant unless the performance justifies the mechanism’s consideration. The former problem will be detailed in the next section.
3.0 Priority Setting Mechanisms
If it proves worthwhile to implement priority in SMT processors, one difficult task will be to determine the priority assignment that should be given to each of the several threads. Since this question is moot if the potential for performance improvement does not exist, we did not focus on an exploration of various schemes. Instead, in the following two sections, only the schemes for setting priority which were used when conducting experiments for this project are explored.
3.1 Setting Fetch Priority
In our first scheme, the programmer must set the priority. The mechanism requires utilizing a special re-defined assembly language instruction. This solution requires the programmer to have intimate knowledge of the execution characteristics of each of the threads. We used feedback from the simulator as a guide in the setting of this value.
3.2 Setting Issue Priority
For the issue stage scheme, priority is set based on the dynamic number of instructions used to reach the lock during the previous iteration of the critical loops of each thread. While one could envision a purely hardware structure to do this, we re-defined an assembly language instruction that created a "checkpoint" when executed. The subsequent executions of these instructions used the information from the checkpoint to calculate the ‘countdown-to-rendezvous’ value for the thread.
This mechanism assumes that the number of dynamic instructions of the critical loops is close to constant from iteration to iteration. This turned out to be true for the benchmark we studied. More sophisticated code would make use of such a mechanism much more difficult. For the experiments conducted for this project, this sufficed.
4.0 Experimental Setup
4.1 Simulator
The simulator chosen for this experiment was SMTSIM [11] from University of California, San Diego (UCSD). This simulator had several advantages over the other CPU simulators. It directly runs Alpha executables. It also implements the ICOUNT 2.8 fetch mechanism [8] that we felt would supply enough instructions to keep the issue queue sufficiently well fed. This mechanism chooses two threads that appear to be making the most progress. Up to eight instructions are fetched from these threads during each cycle.
Our simulator had 2-way set associative I cache, D cache, L2 unified cache and L3 unified cache (see Table 1). The I cache, D cache and L2 cache each have eight separate banks. Although our simulator is eight-wide issue and can support up to eight simultaneous threads, two issue slots are reserved for floating point operations. Thus, with our benchmark, which uses only the integer units, we cannot hope to achieve the full utilization. Our most optimistic goal would be to fill six of the eight slots for a utilization of 75%. We are also limited when the issue and fetch queues fill (see Table 2) and it is possible to issue only up to four load/store instructions per cycle.
|
I cache size |
D cache size |
L2 cache size |
L3 cache size |
|
64 KB |
64 KB |
1 MB |
4 MB |
Table 1. Simulator cache sizes for SMTSIM. All caches are 2-way set associative.
|
Issue queue size |
Fetch queue size |
|
32 |
32 |
Table 2. Queue sizes for SMTSIM.
4.2 Benchmark
For our benchmark, we wrote seven threads that were intended to represent the work of seven tasks in a video teleconference. Rather than implement a complete video teleconference, we felt it was more important to implement a benchmark that could be repeated reliably. Each thread runs a kernel of code whose behaviors contained the most exercised code in the thread. All of these threads are spawned by the same main process and share the same virtual memory addresses. There is a common pool of packet buffers, organized into 8 queues. Each packet contains a header of sixteen bytes and a payload of 480 bytes. Seven of the queues are first-in-first-out (FIFO) feeding the packets to each of the seven threads. All inter-thread communication is done through an enqueue function, which places a pointer to a packet into that thread’s input queue. The eighth queue is the free space queue, organized last-in-first-out (LIFO) to maximize the likelihood of reusing a packet already in cache.
Each thread is an infinite loop. It dequeues a packet, does its work and (optionally) enqueues packets to other threads. A thread will block if its input queue is empty or if it tries to enqueue a packet to a subsequent thread whose queue is full (see Figure 3).
Figure 3. Our benchmark consists of seven threads that interact as shown above. Not shown is the main thread initialization that primes the input queue for speaker. The threads are represented by ovals and rectangles are the queues between them. The arrows follow the flow of packets.
Thread 1 - Speaker. In a real system, this thread would receive incoming video teleconferencing packets and tag them according to their conference. In the benchmark, this thread simply manufactures a fake incoming packet each time it successfully dequeues any packet. Unlike a real system, these packets are constructed so that all of the packets will use all of the threads.
For our benchmark, the main process starts the entire test by sending ten packets to the speaker’s queue. Once the speaker receives a packet, it writes the entire packet, so the D-Cache footprint is 1 packet. Each packet is placed into the input queue for short cut.
Thread 2 - ShortCut. The vast majority of packets received by a video teleconference are video and audio packets. ShortCut identifies these very common packets and diverts them directly to the replication and redistribution engine. Packets that initiate connections, close connections, or negotiate for speeds require much more complex parsing and dispatching, so ShortCut in a real system would dispatch those rare packets to a variety of routines we did not write. Rarely used processes can run in user-mode. The fast path typically runs in kernel address space. In a dedicated video conference system, ShortCut is often part of the interrupt handler for the incoming packet.
For our benchmark, shortcut reads only a few words of the header, so his D-Cache footprint is negligible. Shortcut is a very inexpensive thread, so his incoming queue is typically empty and the packet is still in level 1 of the D-Cache when shortcut reads it. Each packet is placed into the input queue for check CRC.
Thread 3 – Check CRC. This thread implements a CRC-16 algorithm. Incoming packets are checked for completeness before wasting time replicating them to the listeners. Systems built in user-mode on top of a traditional TCP/IP stack often skip this step, on the presumption that TCP/IP will not deliver an incorrect UDP datagram. In a dedicated video conferencing system, a full TCP/IP stack would be unaffordable overkill. Even in a dedicated system, the CRC Check is sometimes skipped.
For our benchmark, check CRC reads the entire packet, calculating the CRC-16 in registers. Data should typically still be in the Level 1 D-Cache. Since it is not the critical path, its CPU usage typically fits into slots that would otherwise have been idle. Each packet is placed into the input queue for decrypt.
Thread 4 -- Decrypt. Decryption and Encryption were added to the benchmark on the assumption that the customer would like to prevent unauthorized access. Other (not implemented) features of the teleconference system would authenticate users. Valid participants receive a public key unique to this conference for use in encrypting their packets. Since humans can enter and leave the conversation, this code would typically contain complications to tolerate the use of an old key during the transition to a new key. Regular key changes limit the exposure to session hijacking. Decrypt and Encrypt use TEA[12], the Tiny Encryption Algorithm invented by David Wheeler . TEA is a Feistel stream cipher that is compact to code and relatively fast in software.
For our benchmark, decrypt allocates an output packet, reads the input packet, writes the output packet, frees the input packet, and enqueues the output packet for subsequent processing. Although the decryption is done mostly in registers, each session has a key in RAM that is 4 words long. The session key might miss in the D-Cache. It may get D-Cache misses if the output packet has been in the free space queue for long enough.
Thread 5 -- Replicate. The Replicate thread makes N-1 copies of the packet, where N is the number of listeners in the conference. To conserve cache and minimize packet allocation, the input packet is re-used for the final listener simply by overwriting the destination address. In our experiments, replicating to five listeners unbalanced the work among the threads, so we cut this thread back to a fixed replication fan-out of two.
Replicate allocates 1 new packet for a replica, reads the old packet and writes the new packet. Other operations on the packets are minimal. Replicate produces multiple output packets for each input packet it receives. Therefore, all subsequent threads run more often.
Thread 6 -- Encrypt. Each out-bound packet is encrypted using the public key of the listener. The encryption process is identical to the decryption processes, except that each individual listener has a session key.
Encrypt consumes almost exactly the same resources as decrypt, except that it runs more often (typical fan-out for a video teleconference is four listeners) and there are correspondingly more keys in RAM. Encrypt sends each packet to the input queue for repackage.
Thread 7 - Repackage. In a real system, flow control and error recovery have to take place somewhere. In our benchmark, these miscellaneous tasks are lumped together at the end in repackage. Outbound packets need to have a valid CRC-16 to ensure that the packet will not be discarded by the listener. We did not do an additional CRC-16 in our benchmark. To keep the benchmark running, repackage enqueues one packet to Speaker for each packet that goes to the last listener in the conversation. This simulates a new packet coming in from the speaker without using timers. Our fear was that random arrivals would either come in too fast or too slow. This would cause our benchmark to bog down in input overload or drain out and have no input. Repackage frees N-1 packets for each original packet, and reads a small portion of the header of each packet.
4.3 Inter-thread communications
The SMTSIM simulator implements non-standard (and undocumented) synchronization mechanisms. An SMT_LOCK instruction attempts to obtain a lock on a mutex pointer. If no other thread holds this mutex, the lock succeeds. If another thread currently holds the lock, the calling thread is quiesced. This means all instructions in the pipeline belonging to the thread are squashed, and the thread no longer participates in arbitration for the fetch unit.
An SMT_UNLOCK instruction causes the calling thread to relinquish its lock on the mutex. This will wake up one thread that is waiting on the mutex (if there is any). The newly awoken thread is then given the requested lock.
The SMT_CREATE instruction spawns a new thread. An argument to the instruction is the address of a function that serves as a starting point for execution. All registers of the parent thread are copied into the child thread’s state without any charge of CPU time. While it is unclear whether this is possible in real hardware, the performance impact to our experiments is negligible since we create six threads and then never execute the instruction again.
The SMT_TERMINATE instruction frees a thread. Since our experiment has non-terminating threads, this mechanism was not used at this time.
Through communication with Dean Tullsen, we had a general idea of how to use these instructions. Nonetheless, the interface to the application had to be ported to be compatible with GCC as well as the multiflow compiler used at UCSD. In particular, some pre-defined temporary registers used by code generated by GCC needed to be set appropriately within the simulator (in particular, those relating to the stack and global pointers.) These adjustments were determined by painstakingly tracing through disassembled Alpha binaries.
4.4 Bug Fixes and Extensions
The simulator only supports a subset of the Alpha instruction set. Of particular difficulty was lack of support for some common 21264 instructions that should have mapped to MOVE instructions in earlier architectures. This included the AMASK instruction and a couple of prefetch primitives. To enable execution of C library calls, we emulated the correct 21064 implementation of these instructions.
One important bug fix concerned the MSKQH instruction. This instruction uses value (bits 0-2)*8) of one of the source operands to left shift an architected byte mask. The destination is then written with appropriate bytes of the source operand set to zero. Instead of implementing the shift as a left shift, the simulator used a right shift of (8 – value (bits 0-2))*8. In addition, the byte mask was not the architected byte mask but one that "theoretically" would implement the same behavior. When value (bits 2-0) was equal to zero, however, a right shift of 64 was attempted. Since the Alpha implementation of shift only uses the lower 6 bits of the specified shift value, this right shift was actually a shift of zero. Since the byte mask used was not the correct one, bytes in the destination register were cleared that should not have been. This would usually result in a segmentation fault somewhere later in the code (unfortunately, often much later.) Since the MSKQH instruction can be used in generating addresses, it was not uncommon.
After a great deal of tracing through disassembled code, both within the simulator and outside the simulator, we identified and fixed this bug. We believe similar bugs exist in the emulation of several other instructions as well. We plan to inform the Dean Tullsen of this finding.
Even after this fix, some library calls, such as printf, caused core dumps. With the project deadline fast approaching, we abandoned the effort of fixing the simulator, deciding to avoid those library calls that faulted. We re-defined some NOP’s to perform some critical library calls (such as print routines) within the simulator itself. This substantially reduced our flexibility in designing benchmarks.
4.5 Simulation Implementation of Priority Mechanisms
Two instructions were added to support the fetch and issue priority hardware mechanisms: SMT_PRIORITY and SMT_CHECKPOINT. The SMT_PRIORITY instruction takes an integer as an argument that indicates the priority level for that thread. This is used in the strict priority and fraction priority fetch mechanisms. For SMT_CHECKPOINT, the first execution of the instruction resets a hardware counter indicating the number of instructions committed for that thread. On subsequent executions of the instruction, the value of the counter is used as the countdown when arbitrating for issue bandwidth.
5.0 Results
The performance statistics obtained running the benchmark application for 100 million instructions is shown in Figure 4. It is clear from the results that ICOUNT 2.8 performs well and is difficult to improve upon. No improvement is evident using countdown-to-rendezvous, while a 2% improvement is obtained using fraction priority. The strict priority fetch mechanism behaved as poorly as our intuition would have guessed, performing 21% worse than ICOUNT.
|
Fetch Based |
Issue-based |
Combination |
||||||
|
I-Count |
Strict Priority |
Fraction Priority |
Countdown |
Countdown w/ Fraction |
||||
|
IPC |
3.583 |
2.822 |
3.648 |
3.612 |
3.651 |
|||
|
CPU Utilization |
44.78 |
35.27 |
46.5 |
45.15 |
4563 |
|||
|
Total fetched |
47.46 |
35.94 |
48.08 |
47.82 |
48.31 |
|||
|
Flushed after failed lock |
0.2 |
0.1 |
0.1 |
0.2 |
0.1 |
|||
|
After 100,000,000 instructions |
||||||||
Figure 4 – Simulation Results
A potential reason for our relatively poor performance is imbalance among the various stages in the network application. The IPC for each thread (using ICOUNT 2.8) is shown in Figure 5. While the purpose of the advanced fetch policies was to improve upon performance in situations where there is an unequal amount of work to do before a lock, disparities this large are likely to make any such optimizations ineffective.
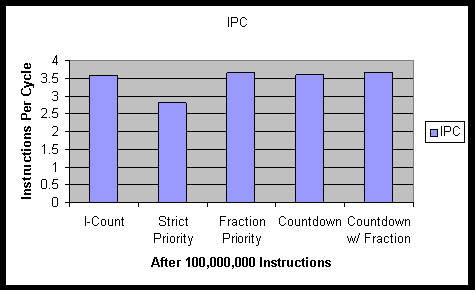
Figure 5 – IPC per thread after 100,000,000 instructions.
Threads 4 and 6 were decrypt and encrypt.
It is also difficult to improve performance through priorities if the stages with the most work cannot exploit any more ILP than they would with ICOUNT 2.8. When threads are executing virtually unrestrained by processor resources, this is likely to be the case.
6.0 Conclusions
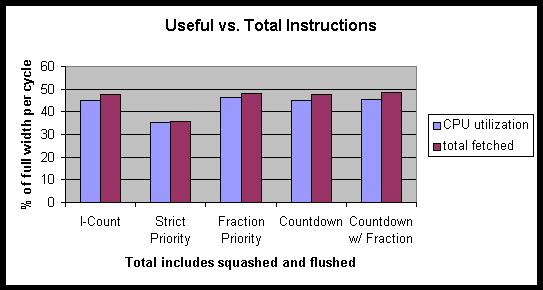
Figure 7 – Difference between instructions fetched and instructions retired successfully
We have obtained preliminary results for several novel fetch and issue strategies in the quest to increase the throughput of explicitly parallel code. Our results were not encouraging for any of these mechanisms especially considering the significant additional hardware or software costs.
The one technique that showed some small amount of promise, fraction priority, is probably the least expensive to implement in hardware. Exploration of a more general class of applications is necessary to decide if even this smaller cost is worthwhile, especially since some programmer effort was required to set the priorities for each thread.
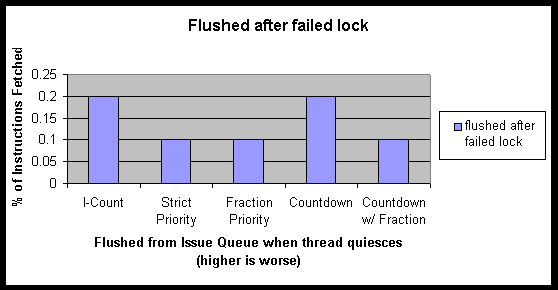
Figure 8 – Wasted instruction fetches due to blocking
It is interesting to note the ways in which instructions were wasted. Figure 8 shows that each of the different priority schemes lost very few (0.1 % of all instruction fetches to 0.2% of all instruction fetches) to flushes that happen when a lock blocks the thread.
7.0 Future Work
References
--------------------------
[1] Almedia & Cao. Measuring Proxy Performance with the Wisconsin Proxy Benchmark. Proceedings of the 3rd International WWW Caching Workshop TF-Cache Meeting,
http://wwwcache.ja.net/events/workshop/27/cao-wpb.ps
[2] Almedia, J., Dabu, M., Manikutty, A., and Cao, P. Providing Differentiated Quality-of-Service in Web Hosting Services. Proceedings of the 1st workshop on Internet Server Performance, June 1998,
http://www.cs.wisc.edu/~cao/WISP98/final-versions/jussara.ps
[3] Banga, G., Druschel, P., Mogul, J. C., Better operating system features for faster network servers, Proceedings of the 1st workshop on Internet Server Performance, June 1998,
http://www.cs.rice.edu/~gaurav/papers/wisp98.ps
[4] Mogul, J.C., Operating system support for busy internet servers, Proceedings of the Fifth Workshop on Hot Topics in Operating Systems (HotOS-V), Orcas Island, WA, May 1995.
http://www.research.digital.com/wrl/techreports/abstracts/TN-49.html
[5] Tomlinson, G., Major, D., Lee, R.
High-Capacity Internet Middleware: Internet Cache System Architectural Overview, Proceedings of the 2nd workshop on Internet Server Performance, ACM SIGMetrics, May 1999,http://www.cc.gatech.edu/fac/Ellen.Zegura/wisp99/papers/tomlinson.pdf
[6] Tullsen, D., Lo, J., Eggers, S., Levy, H., Supporting Fine-Grained Synchronization on a Simultaneous Multithreading Processor, Proceedings of the 5th International Symposium on High Performance Computer Architecture, January, 1999,
http://www.cs.washington.edu/research/smt/papers/hpca.ps
[7] Lo, J., Eggers, S., Emer, J., Levy, H., Lo, J., Stamm, R., Exploiting Choice: Instruction Fetch and Issue on an Implementable Simultaneous Multithreading Processor, Proceedings of the 23rd Annual International Symposium on Computer Architecture, Philadelphia, PA, May 1996,
http://www.cs.washington.edu/research/smt/papers/ISCA96.ps
[8] Tullsen, D., Lo, J., Eggers, S., Emer, J., Levy, H., Lo, J., Stamm, R., Tullsen, D., Simultaneous Multithreading: A Platform for Next-generation Processors, IEEE Micro, September/October 1997
http://www.cs.washington.edu/research/smt/papers/ieee_micro.pdf
[9] SimpleScalar Tools Homepage, http://www.cs.wisc.edu/~mscalar/simplescalar.html
[10] Huang, J., The SImulator for Multithreaded Computer Architecture,
http://www.cs.umn.edu/Research/Agassiz/Tools/SIMCA/simca.html
[11] Tullsen, D., The SMT Simulator MultiThreading Simulator,
http://www-cse.ucsd.edu/users/tullsen/smtsim.html
[12] Wheeler, D., Tiny Encryption Algorithm,
http://www2.ecst.csuchico.edu/~atman/Crypto/code/tea-encryption.alg.html
[13] Bradford, Jeffrey P., Abraham, Seth, "Efficient Synchronization for Multithreaded Processors", Workshop on Multithreaded Execution Architecture and Compilation, January 1998.