From Label Maps to Label Strokes:
Image Parsing from Sparsely Labeled Training Data
University of Wisconsin – Madison
Abstract
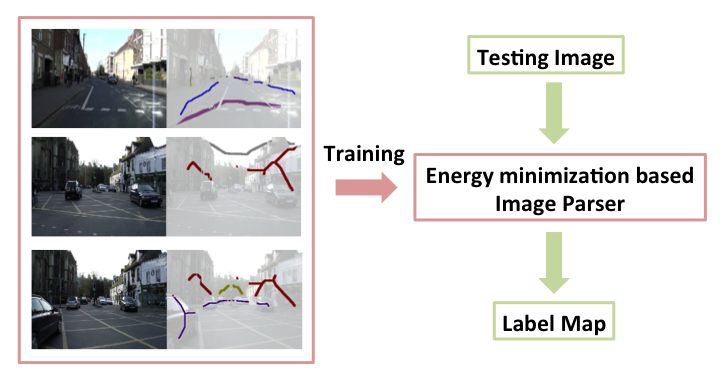
This paper proposes a novel image parsing framework to solve the semantic pixel labeling problem from only label strokes. The input to our framework is a set of training images, each of which has zero, one, or multiple semantic label strokes; the output of our framework is a trained image parser, which can be applied to new testing images without any user interaction.
Our framework is based on a network of voters, each of which aggregates both a self voting vector and a neighborhood context. The voters are parameterized using sparse convex coding. We learn the parameters by minimizing a regularized energy function that propagates label information in the (labeled and unlabeled) training data while taking into account of context interaction. A backward composition algorithm is proposed for efficient gradient computation. Our framework is capable of handling label strokes and is scalable to a code book of millions of bases. Our experiment results show the effectiveness of our framework on both synthetic examples and real world datasets.
Publication
Shengqi Zhu, Yiqing Yang, Li Zhang. From Label Maps to Label Strokes: Semantic Segmentation for Street Scenes from Incomplete Training Data, IEEE Workshop on Computer Vision for Converging Perspectives, December, 2013. [PDF 1.2 MB][Slides 27MB]
Acknowledgements
This work is supported in part by NSF EFRI-BSBA-0937847, NSF IIS-0845916, IIS-0916441, a Sloan Research Fellowship, a Packard Fellowship for Science and Engineering, and a gift donation from Adobe Systems Inc.
Supplementary Video
Both training and testing treat video frames as independent images; temporal inter-frame motion is not used in the current work so that our method can be applied to single images.
Download [Training Result 10.1 MB] [Testing Result 6.9 MB]
| Label stroke missing rate k. (Not all regions need to have a stroke) | ||||||||
| k=0% | k=20% | k=40% | k=60% | |||||
| Training | Testing | Training | Testing | Training | Testing | Training | Testing | |
| Building | 88% | 87% | 88% | 87% | 87% | 86% | 87% | 87% |
| Car | 53% | 28% | 51% | 28% | 57% | 28% | 52% | 27% |
| Road | 95% | 95% | 95% | 95% | 95% | 96% | 94% | 95% |
| Sidewalk | 55% | 35% | 53% | 33% | 60% | 34% | 57% | 36% |
| Sky | 94% | 88% | 94% | 88% | 95% | 89% | 95% | 90% |
| Tree | 68% | 56% | 66% | 55% | 67% | 56% | 62% | 52% |
| Overall | 84% | 75% | 83% | 75% | 84% | 75% | 83% | 75% |
Future Work
Small objects do not work well yet, and need more research effort. We hope that this framework would make it easier to collect training data to process ``big'' visual data.