|
Mohit Saxena and Michael M. Swift
Department of Computer Sciences
University of Wisconsin-Madison
Flash memory is the largest change to storage in recent history. Most research to date has focused on integrating flash as persistent storage in file systems, with little emphasis on virtual memory paging. However, the VM architecture in most of the commodity operating systems is heavily customized for using disks through software layering, request clustering, and prefetching.
We revisit the VM hierarchy in light of flash memory and identify mechanisms that inhibit utilizing its full potential. We find that software latencies for a page fault could be as high as the time taken to read a page from flash, and that swap systems are overly tuned towards the characteristics of disks.
Based on this study, we propose a new system design, FlashVM, that pages directly to flash memory, avoids unnecessary disk-based optimizations, and orders page writes to flash memory without any firmware support. With flash prices dropping exponentially and speeds improving, we argue that FlashVM can support memory intensive applications more economically than conventional DRAM-based systems.
Tape is Dead, Disk is Tape, Flash is Disk, RAM locality is King.
-Jim Gray [6]
Flash memory is aggressively following Moore's law: it is cheaper than DRAM and faster than disks. With these trends, research has focused on integrating flash devices as a replacement to disks for storage [1,24]. We assert, however, that flash also provides the underlying performance and price characteristics to back virtual memory. Specifically, its low read latency allows faster page access, and relatively longer write latency is hidden through asynchronous page write operations.
While flash-based virtual memory has been previously investigated [11,13,19], its use has always been debated. System administrators relying on anecdotal wisdom integrate flash disks as swap space to improve the responsiveness of their systems [3]. Others have advocated avoiding flash for swapping due to its limited write endurance [17]. In this paper, we investigate the truth behind these issues and revisit the VM hierarchy in light of flash memory.
Servers are often statically provisioned with enough memory to avoid swapping, but swap performance still matters for laptop and desktop systems. Workloads on these systems vary widely: running too many programs at once or working on a larger-than-normal data set can cause memory pressure and hence swapping. In both cases, swapping to flash can provide comparable performance at a lower price, or better performance if the system limits the amount of DRAM that can be installed.
Based on the price and performance characteristics of flash, we propose FlashVM, a restructured virtual memory system tuned for swapping to flash memory. FlashVM gives complete control over swapping to the VM system, rather than splitting it between the VM system and the block subsystem.
We also show how the VM hierarchy in most modern operating systems is overly tuned to the performance characteristics of disks. This has resulted from decades of disk being the only option for swapping [4,15]. Since flash media behavior differs from disks, most of these disk-focused optimizations inhibit the optimal use of these devices. For example, flash devices have large performance differences based on write patterns (sequential is much better than random), but not read patterns.
This paper revisits the Linux virtual memory hierarchy and presents opportunities to improve its performance with flash memory. First, we find that software latencies vary widely and can be as high as the read access latencies of flash memory, and thus must be streamlined. Second, we find that the Linux VM system makes no attempt to optimize write behavior. With experiments on flash and disks, we show that with the current Linux VM system, memory intensive applications can execute from 60% slower to 65% faster when compared to traditional swap disk alternatives.
NAND flash memory technology has witnessed several big changes in the recent years. Many new manufacturers have joined the race to produce faster and cheaper flash devices [23]. In this section, we give a background on the key flash characteristics that distinguish them from modern hard disks.
Solid-state disks (SSDs) integrate firmware to provide a disk-like interface, such as SATA, on top of flash storage. This firmware, the Flash Translation Layer (FTL) [9], remaps the logical block addresses to physical flash addresses. It also provides wear leveling to increase write endurance. This layer is particularly designed for compatibility with existing file systems and storage interfaces, and may not be ideal for virtual memory. Furthermore, SSDs present a persistent storage abstraction, and also store the address mapping. This is unnecessary if using flash for virtual memory, as swap files are inherently temporary and volatile.
In contrast to disks, there is a wide range of performance for flash devices available in the market today, as shown in Table 1. Inexpensive devices such as USB flash sticks or camera memories offer moderate read bandwidth but have poor random-write performance. Solid-state disks (SSD), with a standard SATA interface, provide much better performance, about 3x better than the fastest hard disks, with 100MB/s sustained transfer rates. This results from intelligent block mapping schemes, parallel I/O accesses to multiple flash chips (similar to RAID) and write buffering [12]. High-end flash drives connected with the PCI-e interconnect interface are even faster, thereby enabling terabytes of virtual memory with speeds nearer to DRAM. Thus, a flash-enabled VM system must accomodate a variety of device performance.
Unlike disks, flash storage provides fast random read access (0.1ms vs. 8ms). Write access, however, is slower and rewriting a block requires erasing it completely, which may take upto 1.5ms. As the erase block is often larger than a file system block or memory page (128kB vs. 4 kB), FTLs often use log structuring to avoid rewriting flash pages in-place [1]. The asymmetry between read and write performance encourages usages of flash to optimize for asynchronous sequential writes, while the low latency of flash allows synchronous random reads.
To analyze whether flash devices have the overwrite capacity for paging workloads, we analyze a three-day block access trace for swapping traffic on a research workstation running Linux and configured with 700MB of physical memory. We use a pseudo device driver to intercept the block I/O requests to the swap device. Our estimates indicate a write rate of 948 MB per day for a swap partition of 4 GB. With this write rate, and factoring in wear leveling, even a low-end 4 GB flash device with a limit of 100K overwrites can last over 700 years with wear-leveling to spread writes across the device. The maximum swap rate this device could support for five years is over 600 page writes per second.
Virtual memory paging has focused on swapping to disk for decades [4,15]. As a result, the performance characteristics of disks, such as seek latency, have become ingrained in its design. In particular, we find that three characteristics of disks are assumed: (1) random read access is slow, (2) disk I/O latencies are much higher than other software latencies, and (3) swap devices are integrated as disk storage also being used by file systems. In this section, we describe the virtual memory hierarchy in Linux and show how it is overly tuned to these properties of disks. Paging to disks follows a similar I/O path in other operating systems [16,21].
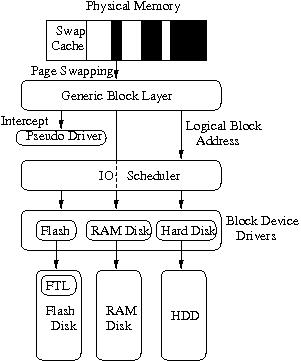
As shown in Section 3, a swapped-out page passes through multiple layers in the VM hierarchy. The swap subsystem hands pages to the Generic Block Layer, which is responsible for the conversion of pages into block I/O requests, known as bio requests in Linux terminology [2].
These bio requests are then queued up with the I/O scheduler. The I/O scheduler can reorder, merge or delay a request before passing it to the device driver. A request is delayed to merge it with other contiguous requests that arrive in the near future. This delay can range from 5-6ms [10] to minimize disk seek latencies while reading or writing. Lower in the stack, requests can be delayed or reordered again by the device driver. These additional software layers, which improve disk performance, substantially delay requests. However, flash devices do not suffer the same latencies as disks, so these delays can prove burdensome.
Based on the declining price of flash relative to DRAM and its increasing performance, we propose that future systems be configured with a large amount of dedicated flash to serve as backing store. This can be either attached directly to the system, or a reserved portion of a solid-state disk managed separately. Flash fits virtual memory behavior because (1) writes to free memory pages are asynchronous, while (2) synchronous random reads are fast, allowing frequent page faults without hurting application performance.
However, this design stresses the virtual memory hierarchy, as paging may be far more frequent than in systems today. Hence, we revisit the virtual memory hierarchy and describe the design challenges for FlashVM. We also show why simply using flash devices for extending virtual memory in existing commodity operating systems is not going to tap their full potential.
As shown in Figure 1, each swapped out page passes through many layers in the VM hierarchy. This is because the same I/O path below the generic block layer serves both the VM hierarchy and the storage stack. However, the low latency characteristics of flash devices mean that the standard I/O path adds additional software latencies for swapping.
We quantify this additional overhead by measuring the performance difference between hard and soft page faults to a RAM disk. A soft page fault need not copy data or access the I/O path; it adds a page back to the page table. In contrast, a hard page fault requires copying data from swap storage back into the memory and then adding it to the page table. Thus, the difference between the latency for the two faults, less the mandatory cost of copying the page by the RAM disk driver, gives the additional overhead.
We measure these overheads on a 2.5GHz Intel Core 2 Quad with a 512 MB RAM disk acting as a swap device. Soft page-fault latency averages 5us, and copying a 4,096 byte buffer takes 10us (when out of cache). In contrast, the average latency for a hard page fault is 196us with a significant standard deviation of 5,660us. Thus, the additional overhead associated with each hard page fault averages 181us. This overhead is largely due to a small number of long-latency page faults that contribute a high percentage of the total execution time.
The bulk of this overhead is spent for CPU scheduling and due to the additional latencies introduced by the Linux swap management subsystem to avoid the possible congestion of paging traffic. For a disk, where the minimum read latency exceeds 500us, these overheads are minor. However, this overhead is nearly the same as the raw read latency of flash memory. Thus, software overheads can double the time to swap in a page from a flash device. For FlashVM, the VM system must access flash directly, rather than pass through these generic block interfaces, to avoid this additional overhead.
As mentioned in Section 2, random writes perform poorly on flash memory. Log-structured file systems [20], or log-structuring in the FTL, improve the performance of flash disks by writing all blocks sequentially. However, the Linux VM system provides no support for swapping to sequential blocks on disk. Rather, the decision of where to swap is made independently of when to swap, leading to many random writes. Today, even for high-end SSDs that leverage log-structuring internally, there is a high disparity between the peformance of sequential and random writes (43,520 vs. 3,300 4K-IO/s). As we show below, flash devices in general may perform even worse than hard disks for random writes.
We measure the sequential bandwidth and random IO/s for synchronous and asynchronous writes (VM page writes are asynchronous in Linux). We use a 15.8 GB capacity IBM 2.5 inch SSD (Model 43W7617, SATA 1.0 interface), with a random read access latency of 0.2 ms and sustained read bandwidth of 69 MB/s. Table 2 compares the write performance of flash with ext2 and a simple log-structured file system, nilfs [14]) against a 7200 RPM disk with ext2.
At a high level, the hard disk is better at sequential access and the flash device is better at random access. However, the performance depends strongly on the file system layout and whether writes are synchronous or asynchronous. With a conventional file-system layout (ext2), the flash device performs 23 times worse than the hard disk at asynchronous random writes. However, with nilfs' log structure the flash device performs 85% better than the disk. Thus, sequential writes are critical to high performance.
In addition, synchronous writes are generally much more expensive for flash. These writes may incur high erase latencies and simultaneous cleaning overheads within the SSD. In contrast, asynchronous writes amortize these costs over a larger group of pages.
Thus, the FlashVM system should cluster writes into large sequential groups to optimize for write speed. While high-end flash translation firmware provides this clustering for file systems, they unnecessarily store the virtual-to-physical block address mapping persistently [7].
To explore these effects on real programs, we investigate the VM access patterns on unmodified Linux kernel 2.6.27 with a 4 GB swap partition on the SSD and 512 MB of physical memory. We profile the swap block-access patterns of 4 applications: a recursive Quick Sort of a large array of random integers, ImageMagick for resizing a large JPEG image, Firefox while surfing the web and streaming videos, and Adobe Reader while viewing pdf files of different sizes. We also trace the swap block accesses on a desktop machine for three consecutive days and on a VMWare virtual machine for 3 hours.
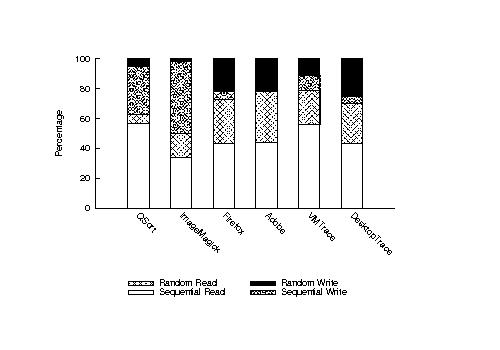
shows the access patterns of these workloads. We characterize as sequential those requests submitted to a block device that were adjacent to the previous request; otherwise we consider them random. All the access patterns are read-dominated, partially because Linux by default prefetches additional 8 pages on a page fault.
These traces illustrate two important points about the nature of swapping traffic. First, random reads are common, accounting for more than 20% of the I/O requests from the large programs and the whole-system traces. Flash disks greatly improve performance for these, and hence have the potential to dramatically improve application performance. For example, ImageMagick, with more than 10% random reads, improved execution time on flash by 65% compared to disk.
More importantly, random writes, which perform poorly on flash, are also common and at times exceed 20% of the accesses in these workloads. As shown earlier in , these perform 23 times worse than disk. They are mainly responsible for QuickSort peforming 60% slower on flash than on disk.
It follows from these results that simply applying an existing VM system to a flash device, despite better random read performance, may not improve paging performance. Rather, the VM system must be tuned for the particular characteristics of flash, in particular avoidance of random writes.
As mentioned in Section 3, Linux opportunistically prefetches 8 pages with each swapped-in page. Prefetching for disks is useful to amortize their high seek latency and to overlap I/O with other computation [22]. On the other hand, flash devices provide an order of magnitude lower read access latency and little penalty for random access. Therefore, prefetching functions embedded in the VM system must be updated for flash. We found, for example, that disabling prefetching for ImageMagick improved performance with flash by 27% and for QuickSort by 5% (which directly follows from our discussion on slow random reads in Section 3).
FlashVM is a promising alternative to existing virtual memory architectures. With flash memory getting cheaper than DRAM and faster than disks, we foresee systems populated with large quantities of flash memory rather than DRAM for satisfying memory intensive workloads. However, the variable and different performance characteristics of flash memory as compared to disks require the re-design of memory management in modern operating systems. In this paper, we list the primary design challenges for FlashVM. Finally, we show that FlashVM has the potential to provide significant performance improvements for real-world applications.