Next: Downloading and Installing Up: CL-MW A Master-Slave Library Previous: License Contents
In many Master-Slave execution environments, it is an unavoidable reality that execute nodes asynchronously connect and unexpectedly disconnect from the computation. This is called slave churn. Many Master-Slave systems accept this reality and provide task scheduling algorithms such that when a slave disconnects, times out, or otherwise is deemed unusable, tasks assigned to that slave are recycled back into the task pool to be distributed out to a different slave at a later time. If the master process exits prematurely, then the slaves all die as soon as they notice, as to not consume computing resources.
Master-Slave systems may be coupled with an external batch scheduling system. The batch system can manage resource acquisitions for the slave processes and provide an environment to restart the computation in the face of machine or other environmental failure.
The master algorithm produces tasks and inserts them into CL-MW. Tasks are data packets destined for a specific task algorithm (and potentially a specific slave as well) and which are stored in the master process. Task algorithms are pieces of code in the slave which process the tasks into results which are sent back to the master process for consumption by the master algorithm. CL-MW maintains a pool of tasks running and waiting to be run. While all of the tasks can be created during the master algorithm initialization, tasks can also be added dynamically. Tasks may be dynamically added based on results from earlier tasks, or they may be dynamically added to limit memory used to store them. Tasks have meta-data associated with them that can dictate where or in what manner the task should be processed. This is known as a task policy.
An optional slave algorithm allows arbitrary computation to happen in the slave in between processing one or more task. An example of such a slave computation is downloading a database upon slave startup which is used by the task algorithms and then removing it when the slave shuts down.
A task algorithm is a piece of code written by the application author which converts tasks into results in the slave. The macro define-mw-algorithm defines a task algorithm. The parameter list of this macro is similar to defun. You specify a name and an argument list. Unlike defun, &key, &rest, and &optional arguments are currently not supported. The supplied code cannot return a set of values with values. There must only be one value that is returned. These limitations will be removed in future versions of CL-MW.
Here is an example definition of a task algorithm which echos back its argument unchanged. Note: The arguments accepted and the result returned are that which you would have done had the task algorithm been defined with defun.
![\begin{lisp}[caption=The \texttt{echo} Task Algorithm]
(define-mw-algorithm echo (val)
val)
\end{lisp}](img2.png)
The result of expanding define-mw-algorithm is a collection of functions and a macro as defined in table 1.1.
|
The functions and macro created in expansion of the echo task algorithm are grouped into three sets: the echo function itself-which is the body of the define-mw-algorithm macro, the task creation macro mw-funcall-echo, and a set of functions which allow one to manage how many pending tasks for this task algorithm are queued.
The macro mw-funcall-echo creates a new task and separates the arguments to the echo function-ultimately called with those arguments in the slave process, from the task policy associated with the task.
The signature of mw-funcall-echo is:
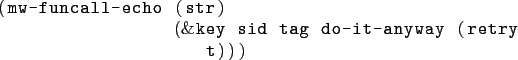
This example call of mw-funcall-echo shows the creation of a new echo task with an argument of "Hello World". All task arguments to the task algorithm must occur within the first set of parentheses and in the order specified for the specific task algorithm 's parameter list. Processing this task will result in a result structure given back to the master algorithm which contains the echoed string "Hello World".
![]()
The task policy associated with a task describes how and where
a task should be executed. The task policy for a task is defined when a
task is created via the my-funcall-* macro. Part of the
default task policy for a task to be considered unordered and to run on
any available slave. Another part of the default is that if the
task running on an arbitrary slave--which then disconnects without
providing an answer, the task is reassigned to a different slave for
processing and this can happen many times. The full default task policy is
specified on page ![]() as well as what each portion
of the policy means.
as well as what each portion
of the policy means.
Through the task policy, one may assign tasks to run on previously acquired ordered slaves. These ordered tasks will be run in the order inserted by the master algorithm. The task policy is directly responsible for a ordered task possibly becoming unrunnable. This happens when the ordered slave which is processing the task disconnects. The default task policy for ordered tasks is that any tasks being processed on the disconnected slave or queued waiting to run on the slave become unrunnable and the task structures are given back to the master algorithm.
This example call of mw-funcall-echo is the same as above with respect to the task generated and the result expected. However, when the result structure associated with this task is presented to the master algorithm, the result will have in it the associated tag of 1234. The tag of a task may be any Lisp form.
![]()
Target numbers are values recorded by CL-MW and set by the master algorithm which represent the number of pending to run tasks for a task algorithm that should be kept in memory at all times. It is useful when a task generator in the master algorithm can produce many more tasks than can fit into the master process's memory or disk on the resource where the master process is running.
An analogy to the CL-MW concept of target numbers is the temperature setting of a thermostat. If one sets a thermostat to 70°F then when the temperature falls below that, the furnace kicks in and injects heat into the room until the target number is reached. As the furnace heats up the room it may overheat it, but it generally shouldn't since the goal is to keep the temperature stable at the thermostat's setting.
In the same manner as the furnace, the master algorithm can use the target number for a task algorithm to create the required number of tasks (which could be zero if no new tasks are needed) into CL-MW until the target number is reached. The master algorithm can run millions or billions of tasks through without having to have all of them in existence at once. The tasks may be lazily generated as needed.
The target numbers themselves have no behavior on how CL-MW processes the tasks or enforces restricting the number of created tasks. All target numbers do are provide a means so that the master algorithm can police itself when creating tasks. The master is free to create more tasks than specified in a target number without restriction (other than running out of memory or other resources in the process).
Continuing the example of the echo task algorithm, here is a description of the
signatures and meaning of this set of generated functions:
(mw-set-target-number-for-echo value) Function
A target number of echo tasks the master algorithm would like to keep in CL-MW. Initially 0.
(mw-get-target-number-for-echo) Function
Return the number of in memory tasks that exist for this task algorithm.
(mw-pending-tasks-for-echo) Function
Return the number of tasks (both currently running and pending to run) for this task algorithm that are currently known about by CL-MW.
(mw-upto-target-number-echo) Function
A number of tasks which must be created by the master algorithm in order to reach the target number for this task algorithm. This function could return zero if the return value of mw-get-target-number-for-echo is equal to or less than the return value of mw-pending-tasks-for-echo.
If an application author wishes to manage only the total
number of created tasks in memory independent of which task algorithm
they represent, then they can use the general target number
API as defined in section 5.2 on
page ![]() . The number of tasks
up to the general target number is the general target number
minus all pending tasks from any task algorithm.
. The number of tasks
up to the general target number is the general target number
minus all pending tasks from any task algorithm.
The macro define-mw-master defines the master algorithm for a CL-MW application. There is only be one master algorithm per application. The master algorithm is responsible for:
The parameter list of this macro is:
![]()
where argv is a variable-arbitrarily named and available in the body, which will be bound to the command line argument list. Any arguments destined to the CL-MW library will have been removed from the list before the master algorithm is invoked. The arguments not stripped out are left in the order specified on the command line. The return value of the master algorithm must be an integer in the range of 0 and 255 (inclusive) and this value becomes the Unix return value for the master process. If the return value is any other Lisp form other than an integer between 0 and 255, the returned result will be 255.
Driving the CL-MW master event loop is one of the main functions
of the master algorithm. The master algorithm accomplishes this by calling the function
mw-master-loop (or a variant of this function-see
page ![]() ). This function blocks and performs
network I/O to all slaves or any other background work in the CL-MW
library. This function returns with a set of values that specify what
is available for the master algorithm to process (such as new results, arrival
or disconnection of ordered slaves, etc) only when there is some
event for the master algorithm to process.
). This function blocks and performs
network I/O to all slaves or any other background work in the CL-MW
library. This function returns with a set of values that specify what
is available for the master algorithm to process (such as new results, arrival
or disconnection of ordered slaves, etc) only when there is some
event for the master algorithm to process.
The master algorithm can use the function mw-allocate-slaves to categorize connecting slaves into the groups: :ordered, :intermingle, and :unordered. A connecting slave is first used to satisfy the needs of the group :ordered, then :intermingle. If enough slaves connect as to satisfy the needs for both the :ordered and :intermingle groups, then they are placed into the :unordered group. Initially the :ordered and :intermingle groups need 0 slaves and all slaves will default to being placed in the :unordered group.
The :ordered group means that the slave will only run ordered tasks dedicated to that slave. The :intermingle group means that a slave may run unordered tasks in addition to ordered tasks dedicated to that slave but the ordered tasks are given priority over any unordered tasks which could run on that slave. Slaves in the :unordered group only run unordered tasks.
When :intermingle or :ordered slaves are needed and new slaves placed into
those groups, the mw-master-loop notifies the master algorithm (or
variant-see page ![]() ) that there are
ordered slaves ready for use. This notification happens with one of
the values returned by mw-master-loop. The CL-MW application
author can use the function
) that there are
ordered slaves ready for use. This notification happens with one of
the values returned by mw-master-loop. The CL-MW application
author can use the function
mw-get-connected-ordered-slaves to
retrieve the list of connected slaves.
The function mw-get-connected-ordered-slaves returns a list
of
SLAVE-IDs which can be used as the :sid field with the
macro mw-funcall-*. If no ready ordered slaves are available,
then NIL is returned. Connected ordered slaves accumulate in that
list until the master algorithm uses
mw-get-connected-ordered-slave
to retrieve them. If at any time ordered slaves disconnect, the
function mw-master-loop will notify the master algorithm of the change
via one of its returned values. The master algorithm can use the function
mw-get-disconnected-ordered-slaves to learn the SLAVE-IDs
of the disconnected ordered slaves. A slave may be in both lists at
once if it connected and then disconnected before the master algorithm was able
to retrieve either of the lists. There is no notification when an
:unordered slave connects or disconnects.
The master algorithm can free a slave from the :ordered or :intermingle groups be using mw-deallocate-slaves and mw-free-slave. These will move ordered slaves to the :unordered group but only after they have completed processing any assigned :ordered tasks. Note: When a freed ordered slave finishes processing the tasks assigned, it will move to the :unordered group even though there may actually be more tasks destined for that slave. In this case, the tasks will follow the task policy dictated by the master algorithm when it created the task.
The membership token-an arbitrary string, is a token known between the master and the slave. It must match for the master to accept the slave and have it perform work. This is not a security measure. This keeps the master and slave processes synchronized in heavy churn situations where many masters and slaves from different computations could be going up and down quickly. The major risk in high master churn situations is port reuse of the master process. A port may have master 1 bind to it, write a resource file, die, then later master 2 from a different computation binds to the port, meanwhile a slave using the original master 1 resource file tries to connect to master 1 but actually connects to master 2. Membership tokens must be unique across CL-MW application master processes running concurrently on one machine. Unless otherwise specified with the --mw-resource-file filename command line option, the membership token will default to "default-member-id".
The slave algorithm is defined with define-mw-slave. The parameter list of this macro is similar to define-mw-master. This macro must return an integer from 0 to 255 inclusive. This portion of a CL-MW application is optional and may be left out entirely in an application.
![]()
The body of a slave algorithm is usually a simple call to mw-slave-loop-simple. mw-slave-loop-simple will wait for tasks to arrive from the master, process them, send the results back, and will repeat until the master sends a shutdown command. mw-slave-loop-simple returns 0 if the shutdown was explicitly requested by the master and happened normally or 255 otherwise.
There are other slave looping function variants which allow the
slave loop function to return after a single, or group, of tasks
is finished. These variants are used when the slave needs to set up
or tear down some files while it is working or otherwise manipulate
the environment around it in-between processing tasks. Please see
page ![]() for these other variants.
for these other variants.
If no slave algorithm is specified in a CL-MW application, then this default slave algorithm is automatically defined and used.
![\begin{lisp}[caption=Default Slave Algorithm]
(define-mw-slave (argv)
(mw-slave-loop-simple))
\end{lisp}](img8.png)
A CL-MW application can be executed in two ways: interactively at a REPL or as a dumped binary from the command line. When running in the REPL, there should be a REPL for the master process and one each for the slave processes. It is not recommended to start different threads where one is the master and the rest are slaves. From the REPL, the CL-MW entry point is the function mw-initialize which takes a list of strings that represent the command line arguments of the application. Running in the REPL is useful for debugging or incremental development.
The recommended means of doing production runs with a CL-MW application is via a dumped binary created with the CL-MW function mw-dump-exec. When this function is called, the entire Lisp image will be written into a binary and the Lisp image will exit and any shared libraries which mw-dump-exec finds as being local to the installation to SBCL or any used CL libraries will be written to the current working directory. The entry point will be an implementation specific function which does some bookkeeping and then invokes mw-initialize with the command line arguments supplied. In this form, the binary acts like any other client/server application and you can easily run as many as you need. If for some reason the process gets an uncaught signal or other terminating error, a stack trace created by SBCL's runtime will be emitted from the program to facilitate debugging.
CL-MW has a collection of settings which are adjusted via command line
options as described on page ![]() .
.
The underlying network implementation of CL-MW is nonblocking and fully asynchronous. A connection to a client is handled by a packet buffer that is split into two pieces: a read buffer and a write buffer. The initial size of each buffer is controllable. The read buffer can grow to a specified maximum size before the connection is cut to the other side on account of the packet being too big. The write buffer size is advisory at this time and only limit how much can be written at one time instead of how large the write buffer actually can be. This will be addressed in a future revision of CL-MW.
The master process will internally group tasks into a whole network packet and subsequently tell the slave how many results to group into the network packet back to the master. The grouping of tasks and results amortizes the cost of sending data over TCP and increases network utilization efficiency-at the cost of memory, of network communication. It is up to the application author to understand enough of their task and result size requirements to pick good groupings so grouped tasks or results don't overflow the packet buffer sizes. Understanding the scale of how many slaves will be connecting to the master process will determine how big to make the initial network buffer sizes and to what they should be capped as they grow.
Peter Keller 2010-11-02