MOS: Towards Scaling Out-of-distribution Detection for Large Semantic Space
Detecting out-of-distribution (OOD) inputs is a central challenge for safely deploying machine learning models in the real world. Existing solutions are mainly driven by small datasets, with low resolution and very few class labels (e.g., CIFAR). As a result, OOD detection for large-scale image classification tasks remains largely unexplored. In this post, we bridge this critical gap by proposing a group-based OOD detection framework, along with a novel OOD scoring function termed MOS. Our method scales substantially better for high-dimensional class space than previous approaches. We evaluate models trained on ImageNet against four carefully curated OOD datasets, spanning diverse semantics. MOS establishes state-of-the-art performance, reducing the average FPR95 by 14.33% while achieving 6x speedup in inference compared to the previous best method.
Out-of-distribution (OOD) detection has become a central challenge in safely deploying machine learning models in the open world, where the test data may be distributionally different from the training data. A plethora of literature has emerged in addressing the problem of OOD detection. However, existing solutions are mainly driven by small, low-resolution datasets such as CIFAR and MNIST. Deployed systems like autonomous vehicles often operate on images that have far greater resolution and perceive environments with far more categories. As a result, a critical research gap exists in developing and evaluating OOD detection algorithms for large-scale image classification tasks.
While one may be eager to conclude that solutions for small datasets should transfer to a large-scale setting, we argue that this is far from the truth. The main challenges posed in OOD detection stem from the fact that it is impossible to comprehensively define and anticipate anomalous data in advance, resulting in a large space of uncertainty. As the number of semantic classes increases, the plethora of ways that OOD data may occur increases correspondingly.
To demonstrate, we first explore the effectiveness of a common baseline approach for OOD detection, MSP, on a large-scale image classification dataset, ImageNet. We investigate the effect of label space size on the OOD detection performance. In particular, we use a ResNetv2-101 architecture trained on different subsets of ImageNet with varying numbers of classes $C$. We evaluate on four diverse OOD datasets, which we curated and will describe in the next section. As shown in Figure 1, the performance (FPR95) degrades rapidly from 17.34% to 76.94% as the number of in-distribution classes increases from 50 to 1,000. This phenomenon begs the following question: how can we design an OOD detection algorithm that scales effectively for classification with large semantic space?

Motivated by this, we take an important step to bridge this gap and propose a group-based OOD detection framework that is effective for large-scale image classification. We will:
-
provide a new benchmark for large-scale OOD detection evaluation, containing diverse OOD datasets from four real-world high-resolution image databases.
-
propose a group-based OOD detection framework, along with a novel OOD scoring function MOS, that scales substantially better for large label space.
-
demonstrate MOS achieves superior OOD detection performance in large semantic space and compare the performance trend of both MOS and baseline approaches as the number of classes increases.
Check out our CVPR’21 oral paper and code!
A New OOD Detection Benchmark in Large Semantic Space
In the prior literature, evaluations for OOD detection were constrained within small-scale low-resolution benchmarks, such as CIFAR and MNIST. We provide a new benchmark for OOD detection evaluation in large semantic space, targeting on a real-world setting.
-
In-distribution Dataset We use ImageNet-1k as the in-distribution dataset, which covers a wide range of real-world objects. ImageNet-1k has at least 10 times more labels compared to CIFAR datasets used in prior literature. In addition, the image resolution is also significantly higher than CIFAR (32$\times$32) and MNIST (28$\times$28).
-
Out-of-distribution Datasets We consider a diverse collection of OOD test datasets, spanning various domains including fine-grained images, scene images, and textural images. We carefully curate the OOD evaluation benchmarks to make sure concepts in these datasets do not overlap with ImageNet-1k. Below we describe the construction of each evaluation dataset in detail.
-
iNaturalist is a fine-grained dataset containing 859,000 images across more than 5,000 species of plants and animals. All images are resized to have a max dimension of 800 pixels. We manually select 110 plant classes not present in ImageNet-1k, and randomly sample 10,000 images for these 110 classes.
-
SUN is a scene database of 397 categories and 130,519 images with sizes larger than 200$\times$200. SUN and ImageNet-1k have overlapping categories. Therefore, we carefully select 50 nature-related concepts that are unique in SUN, such as forest and iceberg. We randomly sample 10,000 images for these 50 classes.
-
Places is another scene dataset with similar concept coverage as SUN. All images in this dataset have been resized to have a minimum dimension of 512. We manually select 50 categories from this dataset that are not present in ImageNet-1k and then randomly sample 10,000 images for these 50 categories.
-
Textures consists of 5,640 images of textural patterns, with sizes ranging between 300$\times$300 and 640$\times$640. We use the entire dataset for evaluation.
-
Samples of each OOD dataset are provided in Figure 2. The concepts chosen for each OOD dataset can be found in our paper. Here are the links to download the curated datasets (after deduplication and sampling) used in our work: iNaturalist, SUN, Places, Textures (original website).

MOS: A Group-based OOD Detection Technique
Method Overview: A Conceptual Example As aforementioned, OOD detection performance can suffer notably from the increasing number of in-distribution classes. To mitigate this issue, our key idea is to decompose the large semantic space into smaller groups with similar concepts, which allows simplifying the decision boundary and reducing the uncertainty space between in- vs. out-of-distribution data. We illustrate our idea with a toy example in Figure 3, where the in-distribution data consists of class-conditional Gaussians. Without grouping (left), the decision boundary between in- vs. OOD data is determined by all classes and becomes increasingly complex as the number of classes grows. In contrast, with grouping (right), the decision boundary for OOD detection can be significantly simplified, as shown by the dotted curves.

In other words, by way of grouping, the OOD detector only needs to make a small number of relatively simple estimations about whether an image belongs to this group, as opposed to making a large number of hard decisions about whether an image belongs to this class. An image will be classified as OOD if it belongs to none of the groups. We proceed with describing the training mechanism that achieves our novel conceptual idea.
Group-based Learning We divide the total number of $C$ categories into $K$ groups, $\mathcal{G}_1, \mathcal{G}_2, …, \mathcal{G}_K$. We calculate the standard group-wise softmax for each group $\mathcal{G}_k$:
where $f_c^k (\mathbf{x})$ and $p_c^k (\mathbf{x})$ denote the output logit and the softmax probability for class $c$ in group $\mathcal{G}_k$, respectively.
Standard group softmax is insufficient as it can only discriminate classes within the group, but cannot estimate the OOD uncertainty between inside vs. outside the group. To this end, a new category others is introduced to every group, as shown in Figure 2. The model can predict others if the input $\mathbf{x}$ does not belong to this group. In other words, the others category allows explicitly learning the decision boundary between inside vs. outside the group, as illustrated by the dashed curves surrounding classes C1/C2/C3 in Figure 3.
OOD Detection with MOS For a classification model trained with the group softmax loss, we propose a novel OOD scoring function, Minimum Others Score (MOS), that allows effective differentiation between in- vs. out-of-distribution data. Our key observation is that category others carries useful information for how likely an image is OOD with respect to each group.
As shown in Figure 2, an OOD input will be mapped to others with high confidence in all groups, whereas an in-distribution input will have a low score on category others in the group it belongs to. Therefore, the lowest others score among all groups is crucial for distinguishing between in- vs. out-of-distribution data. This leads to the following OOD scoring function, termed as Minimum Others Score:
Note that we negate the sign to align with the conventional notion that $S_\text{MOS}(\mathbf{x})$ is higher for in-distribution data and lower for out-of-distribution.
MOS Establishes SOTA performance in Large-scale OOD Detection
We report the OOD detection performance of MOS vs. baseline approaches in Figure 4. We first compare with approaches driven by small datasets, including MSP, ODIN, Mahalanobis, as well as Energy. All these methods rely on networks trained with flat softmax. Under the same network backbone (BiT-S-R101x1), MOS outperforms the best baseline Energy by 31.06% in FPR95. It is also worth noting that fine-tuning with group softmax maintains competitive classification accuracy (75.16%) on in-distribution data compared with its flat softmax counterpart (75.20%).
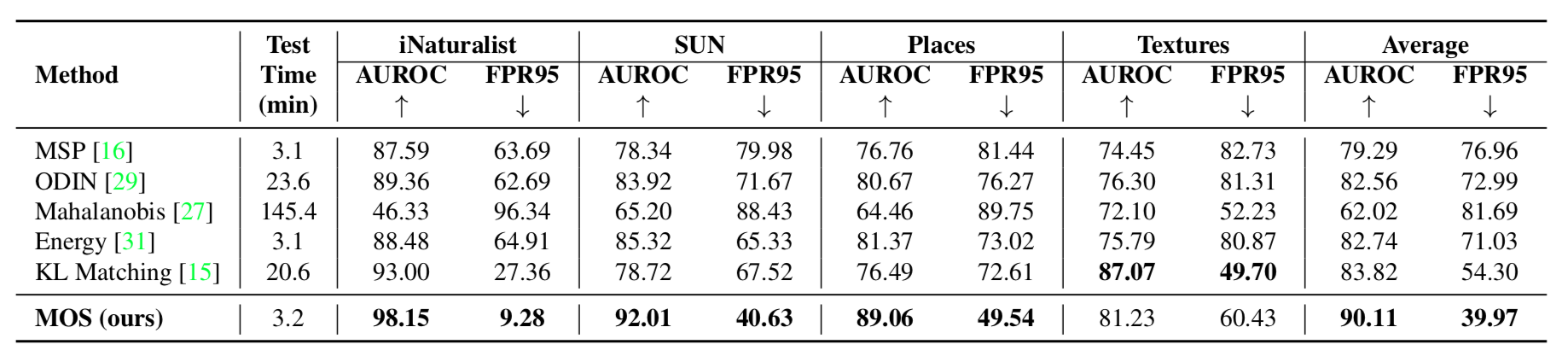
We also compare our method with KL Matching, a competitive baseline evaluated on large-scale image classification. MOS reduces FPR95 by 14.33% compared to KL matching. Note that for each input, KL matching needs to calculate its KL divergence to all class centers. Therefore, the running time of KL matching increases linearly with the number of in-distribution categories, which can be computationally expensive for a very large label space. As shown in Figure 4, our method achieves a 6x speedup compared to KL matching.

In Figure 5, we show the OOD detection performance as we increase the number of in-distribution classes $C \in$ {50, 200, 300, 400, 500, 600, 700, 800, 900, 1000} on ImageNet-1k. Importantly, we observe that MOS (in blue) exhibits more stabilized performance as $C$ increases, compared to MSP (in gray). For example, on the iNaturalist OOD dataset, FPR95 rises from 21.02% to 63.36% using MSP, whilst MOS degrades by only 4.76%. This trend signifies that MOS is an effective approach for scaling OOD detection towards a large semantic space.
Summary
In this post, we propose a group-based OOD detection framework, along with a novel OOD scoring function, MOS, that effectively scales the OOD detection to a real-world setting with a large label space. We also provide four diverse OOD evaluation datasets that allow future research to evaluate OOD detection methods in a large-scale setting. Extensive experiments show our group-based framework can significantly improve the performance of OOD detection in this large semantic space compared to existing approaches. We hope our research can raise more attention to expand the view of OOD detection from small benchmarks to a large-scale real-world setting.