Tensorize, Factorize and Regularize: Robust Visual Relationship Learning
[github]
[paper]
[poster]
Abstract. Visual relationships provide higher-level information of objects and their relations in an
image - this enables a semantic understanding of the scene and helps downstream applications. Given a set of localized
objects in some training data, visual relationship detection seeks to detect the most likely "relationship" between objects
in a given image. While the specific objects may be well represented in training data, their relationships may still
be infrequent. The empirical distribution obtained from seeing these relationships in a dataset does not model the
underlying distribution well — a serious issue for most learning methods. In this work, we start from a simple multi-relational
learning model, which in principle, offers a rich formalization for deriving a strong prior for learning visual relationships.
While the inference problem for deriving the regularizer is challenging, our main technical contribution is to show how adapting
recent results in numerical linear algebra lead to efficient algorithms for a factorization scheme that yields highly informative priors.
The factorization provides sample size bounds for inference (under mild conditions) for the underlying [[object, predicate, object]]
relationship learning task on its own and surprisingly outperforms (in some cases) existing methods even without utilizing
visual features. Then, when integrated with an end to-end architecture for visual relationship detection leveraging image data,
we substantially improve the state-of-the-art.
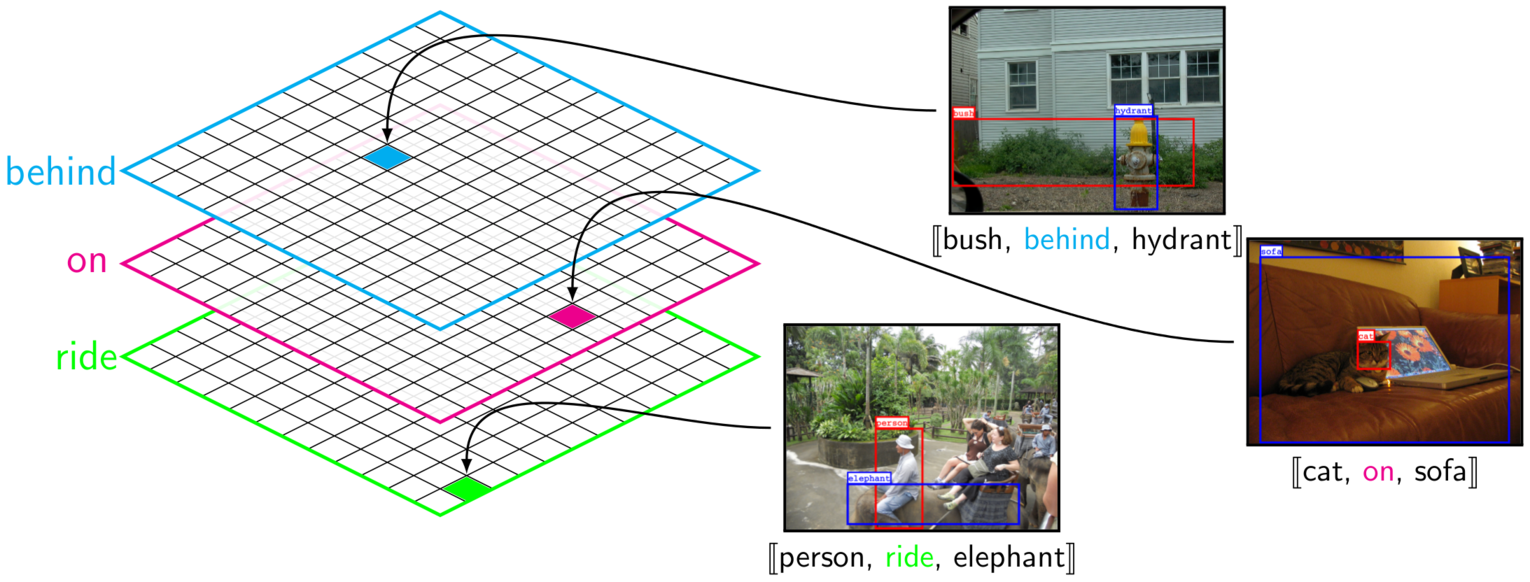 Figure: Multi-relationsl tensor X (of size n x n x m) given n object categories and m possible predicates.
The value at X(i,j,k) is the number of [[i'th object, k'th predicate, j'th object]] instances observed in the training set.
Due to the sparse nature of the relationship instances, only ~1% of the tensor constructed from our training set has non-zero entries.
Figure: Multi-relationsl tensor X (of size n x n x m) given n object categories and m possible predicates.
The value at X(i,j,k) is the number of [[i'th object, k'th predicate, j'th object]] instances observed in the training set.
Due to the sparse nature of the relationship instances, only ~1% of the tensor constructed from our training set has non-zero entries.
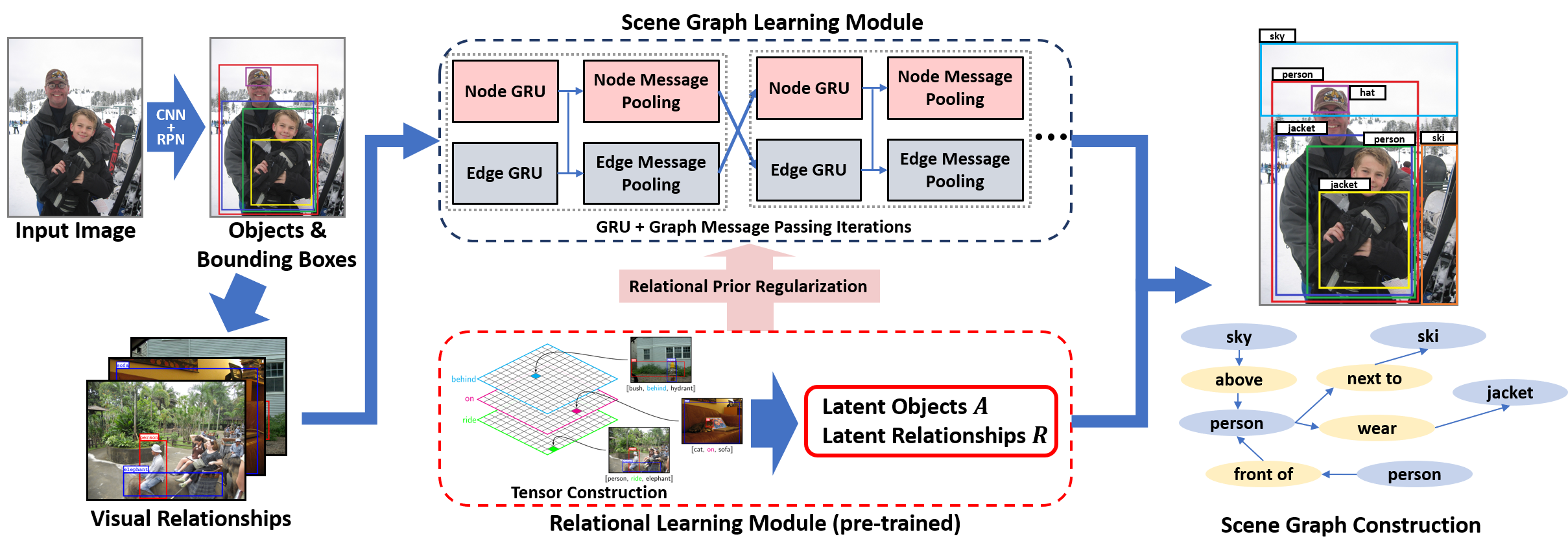 Figure: An end-to-end scene graph detection pipeline. In training, (left) given an image, its initial object bounding boxes and relationships are detected.
Then, (top middle) its objects and relationships are estimated via scene graph learning module (Xu et al.). Our tensor-based relational module (top bottom)
provides a visual relationship prediction as a dense relational prior to refine the relationship estimation which also regulates the learning process of the scene
graph module. In testing, (right) the scene graph of an image is constructed based on both modules.
Figure: An end-to-end scene graph detection pipeline. In training, (left) given an image, its initial object bounding boxes and relationships are detected.
Then, (top middle) its objects and relationships are estimated via scene graph learning module (Xu et al.). Our tensor-based relational module (top bottom)
provides a visual relationship prediction as a dense relational prior to refine the relationship estimation which also regulates the learning process of the scene
graph module. In testing, (right) the scene graph of an image is constructed based on both modules.

 References:
[1] Seong Jae Hwang, Sathya N. Ravi, Zirui Tao, Hyunwoo J. Kim, Maxwell D. Collins, Vikas Singh,
"Tensorize, Factorize and Regularize: Robust Visual Relationship Learning",
Computer Vision and Pattern Recognition (CVPR), 2018.
Acknowledgment:
SJH was supported by a University of Wisconsin CIBM fellowship (5T15LM007359-14). We acknowledge support
from NIH R01 AG040396 (VS),
NSF CCF 1320755 (VS),
NSF CAREER award 1252725 (VS),
UW ADRC AG033514,
UW ICTR 1UL1RR025011,
Waisman Core grant P30 HD003352-45 and
UW CPCP AI117924 (SNR).
References:
[1] Seong Jae Hwang, Sathya N. Ravi, Zirui Tao, Hyunwoo J. Kim, Maxwell D. Collins, Vikas Singh,
"Tensorize, Factorize and Regularize: Robust Visual Relationship Learning",
Computer Vision and Pattern Recognition (CVPR), 2018.
Acknowledgment:
SJH was supported by a University of Wisconsin CIBM fellowship (5T15LM007359-14). We acknowledge support
from NIH R01 AG040396 (VS),
NSF CCF 1320755 (VS),
NSF CAREER award 1252725 (VS),
UW ADRC AG033514,
UW ICTR 1UL1RR025011,
Waisman Core grant P30 HD003352-45 and
UW CPCP AI117924 (SNR).