The first computers were built for military purposes during World War II, and the first commercial computers were built during the 50's. They were huge (often filling a large room with tons of equipment), expensive (millions of dollars, back when that was a lot of money), unreliable, and slow (about the power of today's $1.98 pocket calculator). Originally, there was no distinction between programmer, operator, and end-user (the person who wants something done). A physicist who wanted to calculate the trajectory of a missile would sign up for an hour on the computer. When his time came, he would come into the room, feed in his program from punched cards or paper tape, watch the lights flash, maybe do a little debugging, get a print-out, and leave.
The first card in the deck was a bootstrap loader. The user/operator/programmer would push a button that caused the card reader to read that card, load its contents into the first 80 locations in memory, and jump to the start of memory, executing the instructions on that card. Those instructions read in the rest of the cards, which contained the instructions to perform all the calculations desired: what we would now call the "application program".
This set-up was a lousy way to debug a program, but more importantly, it was a waste of the fabulously expensive computer's time. Then someone came up with the idea of batch processing. User/programmers would punch their jobs on decks of cards, which they would submit to a professional operator. The operator would combind the decks into batches. He would precede the batch with a batch executive (another deck of cards). This program would read the remaining programs into memory, one at a time, and run them. The operator would take the printout from the printer, tear off the part associated with each job, wrap it around the asociated deck, and put it in an output bin for the user to pick up. The main benefit of this approach was that it minimized the wasteful down time between jobs. However, it did not solve the growing I/O bottleneck.
Card readers and printers got faster, but since they are mechanical devices, there were limits to how fast they could go. Meanwhile the central processing unit (CPU) kept getting faster and was spending more and more time idly waiting for the next card to be read in or the next line of output to be printed. The next advance was to replace the card reader and printer with magnetic tape drives, which were much faster. A separate, smaller, slower (and persumably cheaper) peripheral computer would copy batches of input decks onto tape and transcribe output tapes to print. The situation was better, but there were still problems. Even magnetic tapes drives were not fast enough to keep the mainframe CPU busy, and the peripheral computers, while cheaper than the mainframe, were still not cheap (perhaps hundreds of thousands of dollars).
Then someone came up with a brilliant idea. The card reader and printer were hooked up to the mainframe (along with the tape drives) and the mainframe CPU was reprogrammed to swtich rapidly among several tasks. First it would tell the card reader to start reading the next card of the next input batch. While it was waiting for that operation to finish, it would go and work for a while on another job that had been read into "core" (main memory) earlier. When enough time had gone by for that card be read in, the CPU would temporarily set aside the main computation, start transfering the data from that card to one of the tape units (say tape 1), start the card reader reading the next card, and return to the main computation. It would continue this way, servicing the card reader and tape drive when they needed attention and spending the rest of its time on the main computation. Whenever it finished working on one job in the main computation, the CPU would read another job from an input tape that had been prepared earlier (tape 2). When it finished reading in and exceuting all the jobs from tape 2, it would swap tapes 1 and 2. It would then start executing the jobs from tape 1, while the input "process" was filling up tape 2 with more jobs from the card reader. Of course, while all this was going on, a similar process was copying output from yet another tape to the printer. This amazing juggling act was called Simultaneous Peripheral Operations On Line, or SPOOL for short.
The hardware that enabled SPOOLing is called direct memory access, or DMA. It allows the card reader to copy data directly from cards to core and the tape drive to copy data from core to tape, while the expensive CPU was doing something else. The software that enabled SPOOLing is called multiprogramming. The CPU switches from one activity, or "process" to another so quickly that it appears to be doing several things at once.
In the 1960's, multiprogramming was extended to ever more ambitious forms. The first extension was to allow more than one job to execute at a time. Hardware developments supporting this extension included decreasing cost of core memory (replaced during this period by semi-conductor random-access memory (RAM)), and introduction of direct-access storage devices (called DASD - pronounced "dazdy" - by IBM and "disks" by everyone else). With larger main memory, multiple jobs could be kept in core at once, and with input spooled to disk rather than tape, each job could get directly at its part of the input. With more jobs in memory at once, it became less likely that they would all be simultaneously blocked waiting for I/O, leaving the expensive CPU idle.
Another break-through idea from the 60's based on multiprogramming was timesharing, which involves running multiple interactive jobs, switching the CPU rapidly among them so that each interactive user feels as if he has the whole computer to himself. Timesharing let the programmer back into the computer room - or at least a virtual computer room. It allowed the development of interactive programming, making programmers much more productive. Perhaps more importantly, it supported new applications such as airline reservation and banking systems that allowed 100s or even 1000s of agents or tellers to access the same computer "simultaneously". Visionaries talked about an "computing utility" by analogy with the water and electric utilities, which would delived low-cost computing power to the masses. Of course, it didn't quite work out that way. The cost of computers dropped faster than almost anyone expected, leading to mini computers in the '70s and personal computers (PCs) in the 80's. It was only in the 90's that the idea was revived, in the form of an information utility otherwise known as the information superhighway or the World-Wide Web.
Today, computers are used for a wide range of applications, including personal
interactive use (word-processing, games, desktop publishing, web browing,
email), real-time systems (patient care, factories, missiles), embedded systems
(cash registers, wrist watches, tosters), and
transaction processing (banking, reservations, e-commerce).
What is an OS For?
What is a "resource"? Something that costs money!
Why share?
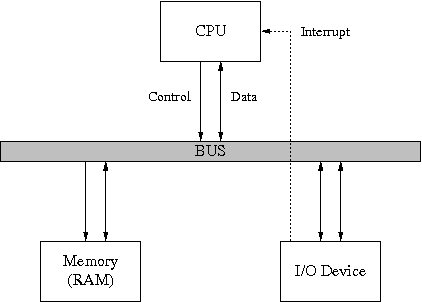
The CPU has a "PC" register1 pointing to next instruction to execute. It repeatedly executes the fetch-execute cycle:
Memory responds to "load" and "store" requests from the CPU, one at a time.
An I/O device usually looks like a chunk of memory to the CPU. The CPU sets options and starts I/O by sending "store" requests to a particular address. It gets back status and small amounts of data by issuing "load" requests. With Direct Memory Access (DMA), a device may transfer large amounts of data directly to/from memory by doing loads and stores just like a CPU. The device interruptes the CPU to indicate when it is done.
I/O devices are millions or even billions of times slower than CPU.
for (;;) {
start disk device
do 100,000 instructions of other useful computation
wait for disk to finish
}
These programs were terrible program to write and worse to debug.
And each time a faster disk came out, the program had to be completely
rewritten!
Then somebody thought up the idea of multi-tasking.
Process 1:
for (;;) {
start I/O
wait for it to finish
use the data for something
}
Process 2:
for (;;) {
do some useful computation
}
The operating system takes care of switching back and forth between process 1
and process 2 as "appropriate".
(Question: which process should have higher priority?)
The hardware feature that enabled this trick was the interrupt.
1In this course PC stands for program counter, not personal computer or politically correct