| Back to the beginning of the page | Back to the CS838 class schedule |
| Back to the beginning of the page | Back to the CS838 class schedule |
| Back to the beginning of the page | Back to the CS838 class schedule |
Lemma
The lower bounds on the time and transmission complexity of four basic collective communication operations in all-port full-duplex SF noncombining Qn in constant-time model are given in the following table.Proof
comm. operation # of rounds # of transmissions OAB n 2n-1 AAB [(2n-1)/n] 2n(2n-1) OAS [(2n-1)/n] n2n-1 AAS 2n-1 n22n-1
| Back to the beginning of the page | Back to the CS838 class schedule |
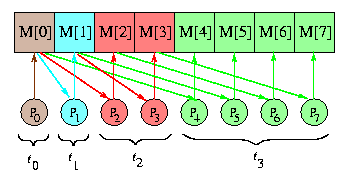
On the other hand, optimal OAB algorithms are harder to find for 1-port SF networks. The
CAPTION: EREW PRAM one-to-all broadcast with 8 processors.
Obviously, EREW PRAM is constrained in the same way as an 1-port network. In the first step, the source writes the data into a shared memory cell. The standard optimal algorithm then just doubles the number of copies of the data in the shared memory in every step, as implied by Figure . As a result, the number of informed processors doubles, too. Therefore, the number of steps matches the trivial lower bound [log p].
It is noteworthy that exactly the same doubling algorithm works for 1-port complete network.
Hypercube
Interestingly enough, the hypercube allows exactly the same optimal broadcast algorithm, since its symmetric and binary recursive topology fits perfectly to this communication scheme.
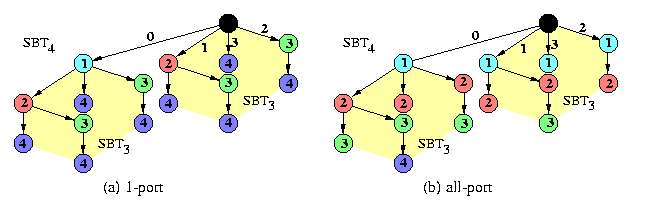
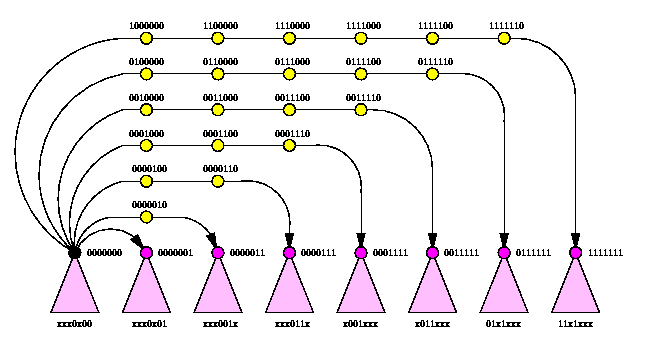
CAPTION: Spanning binomial trees in 1-port and all-port Q4.
The corresponding spanning tree of Qn is called n-level spanning binomial tree, SBTn. In fact, it is isomorphic to the D&C tree of Qn explained in Section #7. Figure illustrates the recursive structure of SBTn: SBT0 is a single node and SBTn is constructed from two SBTn-1's by linking their roots with a new edge and by making either of them the new root. Since the hypercube is both vertex and edge symmetric, we can place the root of a SBT in any hypercube node and use the hypercube dimensions in any order.
|
if the packet arrived via channel of direction i, where 0<= i<= n-1, |
|
then forward it in direction i further (if possible) and simultaneously send it |
| to all neighbors in directions j=i+1,..., n-1 upward and downward (if they exist) |
|
if the packet arrived via channel in dimension i, where 0<= i<= n-1, |
|
then |
|
{ if you are not the last node in direction i, then forward it in direction i further; |
|
for j=i+1,..., n-1 do_sequentially |
|
{ if you are not the first node in dimension j, then forward it in direction j-; |
|
if you are not the last node in dimension j, then forward it in direction j+; |
| } |
CAPTION: Dimension-order OAB tree in 1-port store-and-forward M(3,3,4).
The farthest-first approach provides tight time optimality, except for the case when the first dimension has odd size and the source is exactly in the middle of it. We can conclude that
tOAB(M(...))<=(ts+td+mtm)diam(M(...)).
| Back to the beginning of the page | Back to the CS838 class schedule |
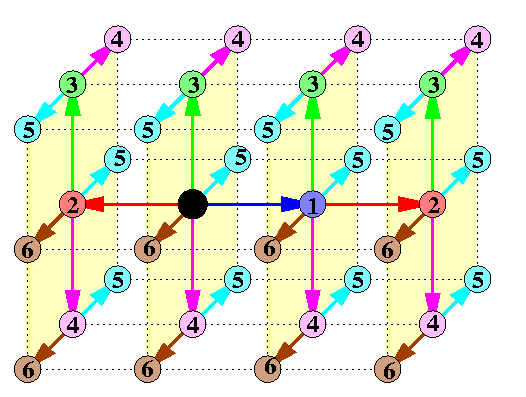
CAPTION: 2-round OAB in all-port WH Q4
DTA is really approximately twice faster on real machines than the standard SBT algorithm, but it is optimal only for n<= 6. An algorithm which is optimal up to a small multiplicative constant for n>= 7 is called Ho-Kao algorithm (HKA) and it is based on the following idea: divide recursively Qn into sufficiently small subcubes of nearly equal size and apply DTA inside these subcubes. HKA assumes e-cube routing with checking the bits left-to-right and uses ascending dimension-simple paths: Given a sequence of dimension numbers 0<= i1 < ... < id<= n-1, d<= n-1, an ascending dimension-simple path is any path u0,...,ud of nodes in Qn such that uj is obtained from uj-1 by complementing bit ij. It follows that all d paths u0-> uj are pairwise node-disjoint if e-cube WH routing is used, so that u0 can send d packets to all these destinations simultaneously. HKA constructs an ascending dimension-simple path u0,...,un such that Qn can be partitioned into n+1 disjoint subcubes Si, of equal or nearly equal size, such that subcube Si contains ui. Figure demonstrates the idea for n=7.
CAPTION: Time optimal OAB algorithm in all-port WH Q7.
One-port WH Meshes
For one-port WH meshes, there exists a simple optimal OAB algorithm. The copies of the packet are disseminated dimension by dimension (cartesian product property), but this time, every node must participate in broadcasting in one dimension the whole time, until all nodes in respective linear paths are informed, since the basic procedure is the recursive doubling instead of trivial SF pipelining. The linear paths are recursively split into halves and in each new half, a new source is chosen. Since WH switching is distance insensitive, this provides always the logarithmic number of rounds. A closer look reveals that it is basically a
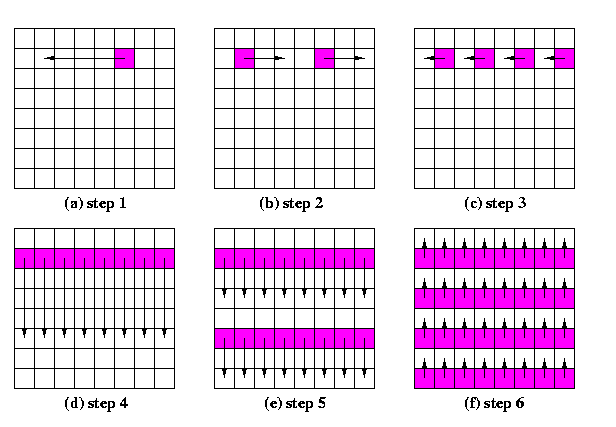
CAPTION: A generic OAB scheme for one-port WH meshes
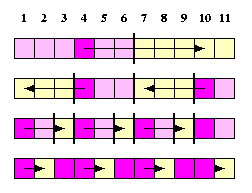
CAPTION: Recursive doubling if the size of the mesh is not a power of two.
One-port WH tori
Optimal-time OAB algorithm uses again recursive doubling, dimension-by-dimension, but due to vertex-symmetry, it is much simpler. The reason is obvious from Figure showing 1D-torus.
TOAB(T(z))=\sumi=1[log z](ts+[\frac{z}{2i}] td+mtm)=(ts+mtm)[log z] + td(z-1).
Compare this with the complexity for the SF model: TOAB(T(z))=(ts+td+mtm)[\frac{z}{2}].
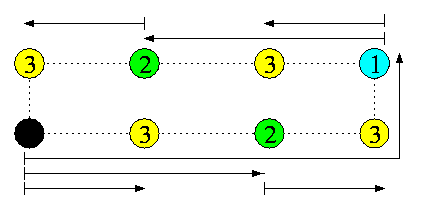
CAPTION: An optimal OAB in 1-port wormhole 1D-torus T(8) using recursive doubling.
All-port WH meshes and tori
The lower bound on the number of rounds of OAB in n-dimensional WH all-port mesh or torus with N nodes is log2n+1N. To match this lower bound, every node, once involved in the broadcasting, must find in every round from the moment it was informed 2n uninformed nodes and deliver them the packet so that all these paths are arc-disjoint. This turned out to be a difficult problem and it has been addressed by the research community for about last 5 years as a challenging open problem. This effort seems to converge to solutions, the latest solutions provide nearly optimal results. We will mention here just some simpler discoveries made during this research quest.
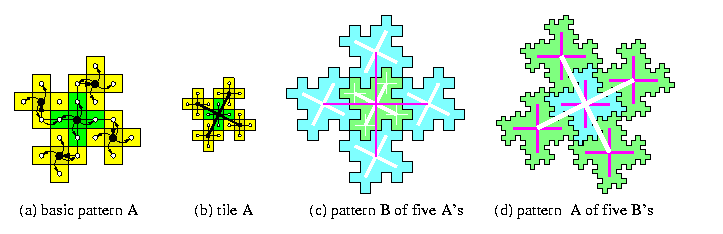
CAPTION: Tiling of torus T(5k,5k)
Definition
A set of dominating nodes D in a direct network G is a subset of nodes of G such that every node in G isThe notion of dominating sets could be useful for SF networks, but it can generalized for WH networks to exploit the distance-insensitivity of routing.
- either in D
- or is a neighbor of at least one node in D
Definition
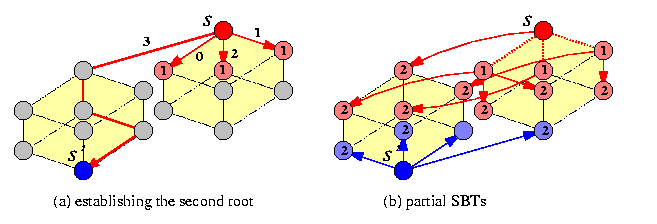
Consider an all-port WH direct network G with node set V, a routing algorithms R, and two subsets of nodes D2\subset D1\subseteq V. The set D2 is said to be an extended dominating set (EDS) of D1 if and only if there exists a set of link-disjoint paths under R such that every node in D1-D2 is reachable along one such path from some node in D2.Figure illustrates both concepts.
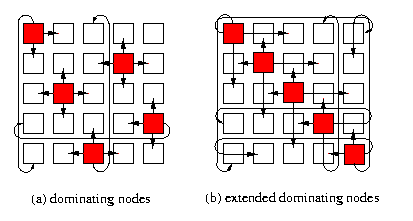
CAPTION: 5-node dominating set and extended dominating set in T(5,5)
The method works well for meshes M(4k,4k) and the basic idea is to build recursively a hierarchy of extended dominating nodes, where level-i EDNs are informed from all EDNs of levels j < i. Figure illustrates the construction of EDNs in mesh M(16,16) with XY routing. In the first two rounds, the source informs 4 level-3 EDNs. In round 3, these 4 nodes inform 12 level-2 EDNs. In round 4, every level-1 EDN receives one packet from either level-2 or level-3 EDN. After round 4, every uninformed node is dominated by at least one informed node so that in one more round, all nodes are informed.
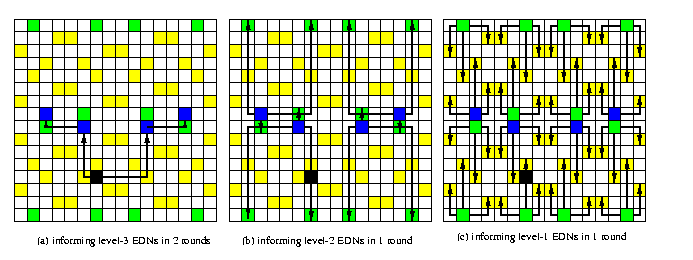
CAPTION: OAB in M(16,16) based on 3-level EDN hierarchy
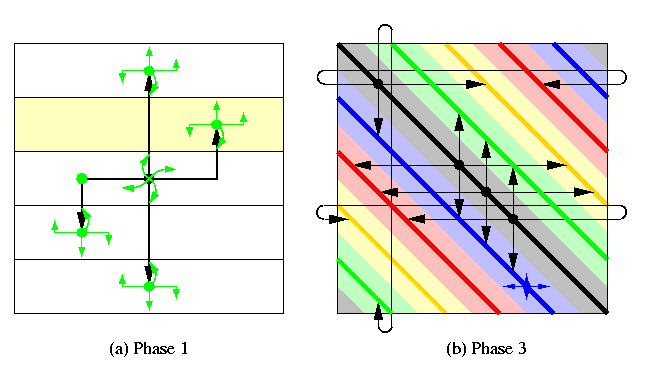
CAPTION: Dilated-diagonal-based OAB in a square torus.
Figure illustrates the recursive construction in phases 1 and 3.
| Back to the beginning of the page | Back to the CS838 class schedule |