Section#15: Introduction to parallel sorting on mesh-based topologies
(CS838: Topics in parallel computing, CS1221, Tue, Mar 23, 1999, 8:00-9:15 a.m.)
The contents
- Introduction to comparison-based sorting
- Sorting networks
- Direct sorting
- Oblivious sorting and 0-1 lemma
- Mesh-based oblivious sorting
- Even-odd transposition sorting on 1-D meshes
- ShearSort on 2-D meshes
- Lower bound on 2-D mesh snakelike sorting
- Lexicographic sorting on 3-D meshes
Introduction to comparison-based sorting
In Sections 15--18, we will discuss parallel deterministic sorting algorithms based on the compare-and-exchange (CE) operation. N will always denote the length of input data sequence. Sorting is one of fundamental problems in computer science. The lower bound on the number of CE operations to sort N elements is \Omega(Nlog N). Several optimal sequential algorithms are known, such as QuickSort or HeapSort.
A vast number of parallel sorting algorithms have been described in the literature and the state-of-the-art is briefly the following:
- there exist time- and cost-optimal PRAM parallel sorting algorithms. The most fundamental is called Cole's Merge sort. It sorts N numbers in EREW PRAM memory using N processors in time O(log N). This will be covered in Section 18.
- There exist asymptotically optimal mesh-sorting algorithms. For example, N=n2 numbers can be sorted on N-node 2-D mesh M(n,n) in time kn, where k is a constant between 2 and 3. This is optimal up to a multiplicative constant, since the number of sorting steps is bounded by the diameter of M(n,n), which is 2n-2. One such algorithm will be described in Section 16.
- The most important and useful parallel sorting algorithm for sorting N numbers on N-node hypercubic networks is Batcher's Merge Sort which needs O(log2N) steps. This will be covered in Section 17.
- There exist deterministic parallel algorithms for sorting N numbers on N-node hypercubic networks in O(log N(loglog N)) CE steps, but the hidden constant is very large.
- The only asymptotically cost-optimal parallel sorting algorithm is based on so called expander graphs, but these algorithms are very complicated and the hidden constants are too large so that for practical applications, the asymptotically non-optimal algorithms perform better. These two last groups of algorithms will not be covered in this course.
Parallel CE sorting algorithms are either PRAM or distributed memory ones. The latter can be implemented either as sorting networks or directly by imposing ordering on the nodes of an interconnection network and by sorting the numbers in the order complying to the numbering of nodes. This is easy if the topology allows hamiltonian path.
Sorting networks
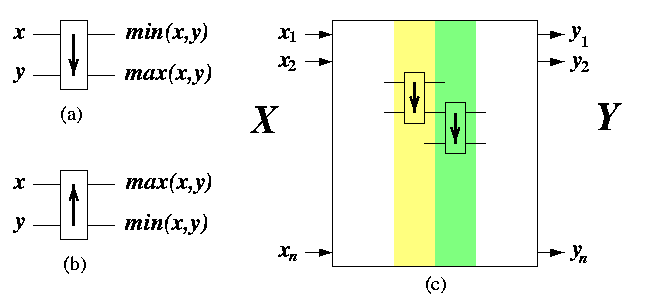
CAPTION: Architecture of comparison-exchange sorting networks. (a) The default type of comparator (b) The second type of comparator. (c) Sorting network composed from columns of basic comparators.
Sorting networks consist of comparators, which are in fact hardware implementations of the CE operation. A comparator has two inputs and two outputs. Depending on the sense of ordering, comparators can be of two kinds, see Figure (a),(b). By default, we will assume case (a). A sorting network is an end-to-end network composed of columns of comparators (see Figure (c)). It is similar to a multistage interconnection network, except that the building block is a comparator rather than a 2× 2 switch. Unsorted input sequence X=x1,...,xN placed on input wires of the leftmost column of comparators passes through the network so that it becomes sorted output sequence (ascending, descending, bitonic) Y=y1,...,yN on output wires on the rightmost column.
The way how columns of comparators are interconnected determines the sorting algorithm. We will assume static networks with fixed interconnection of comparators. Then, each sorting network is a HW implementation of a sorting algorithm whose behavior is data-insensitive: the order in which the CE operations are applied to pairs of input elements does not depend on their input values. The sorting algorithm induced by the sorting network is called oblivious. Hence, an oblivious sorting algorithm performs the same steps for randomly generated input data as for completely sorted data. Terms ``oblivious sorting algorithm'' and ``sorting network'' can be considered synonymous.
The number of parallel CE steps of an oblivious sorting algorithm is given by the depth of its sorting network. Input wires of a network have depth 0. If a comparator in the network has input wires of depth d1 and d2, then its output wires have depth max(d1,d2)+1. The depth of a sorting network is the maximum over the depths of output wires.
If N is greater than the number K of input wires of the sorting network, then we assume that the input data set is split into N/K subsequences, which are then sorted. Comparators are equipped with buffers for N/K numbers and instead of CE operation, perform Compare-and-Split (CS) operation: two input sequences are merged and split again to lower and upper half. This takes O(N/K) steps.
Direct sorting
Given a network of p=N processing nodes, each with one input number. We can impose a total ordering on nodes by numbering them P1,...,PN. Then the sorting problem is equivalent to finding a unique permutation of input data such that Pi holds smaller number than Pi+1, using only exchanges of numbers between logically adjacent nodes (see Figure ). This kind of sorting is called direct network sorting.
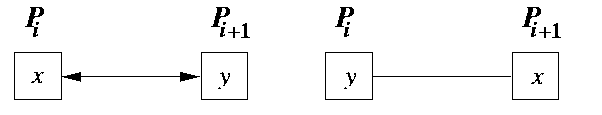
CAPTION: The effect of a compare-and-exchange operation in direct networks, if x > y.
While designing a direct sorting algorithm, we must address the following 3 issues:
- A suitable linear node indexing P1,...,PN. A network topology always allows various nodes indexing schemes, but those preserving adjacency are usually preferable. It is trivial if the graph has a hamiltonian path. If it is not, we know from Section #6 that there is always an indexing such that the distance between logical neighbors is at most 3. The choice of indexing scheme has impact on the complexity of sorting for given topology. Figure shows several indexing schemes suitable for meshes. The last one, denoted by zyx, applies to 3-D meshes and is called lexicographic. A 3-D point (x1,y1,z1) precedes point (x2,y2,z2) if z1y1x1 < z2y2x2, where ziyixi is viewed as a 3-digit number. Lexicographic indexing can be defined for any dimensionality.
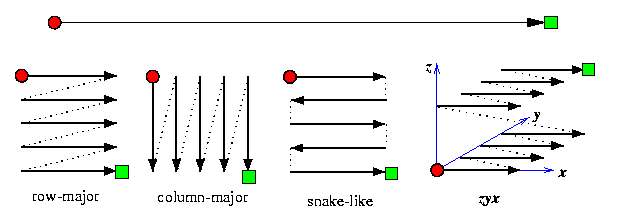
CAPTION: Various schemes for linear indexing of mesh nodes.
- Having a node indexing, we must find perfect node matchings compliant with the indexing. Or more specifically, perfect matchings which will provide the final ordering compliant with the node indexing. One perfect matching consists of [ p/2] disjoint pairs. We will again consider only oblivious direct sorting algorithms, i.e., matchings are given irrespectively to input data values.
- scalability: If p < N, then again one node owns N/p numbers and instead of CE operations, the neighbors perform CS operations. More specifically, an oblivious sorting algorithm then consists of two parts:
- each node sorts its N/p numbers in O((N/p)log(N/p)) steps,
- all nodes perform the direct sorting algorithm using CS operations instead of CE.
The CS operation between 2 nodes, say Pi and Pj, i < j, can be implemented in 2 ways.
- (1) Pi and Pj exchange their sorted subsequences, (2) then each of them merges its subsequence with the one received from its partner into a sorted sequence of double length. (3) Pi keeps the first half of it and throws away the second one, whereas Pj does the opposite.
- (1) Pi sends its subsequence to Pj, (2) Pj does the merging and (3) returns the first half of the result to Pi.
For a network with duplex links, the first method is clearly faster even if the number of computational steps is double, but asymptotically, both are equivalent.
Since CE and CS sorting differs just in the granularity of the basic step of sorting, we will for the sake of simplicity always assume than p=N. In practice, however, we have always p<< N, so we will always investigate scalability. It should be noted here that sorting algorithms have extremely large isoefficiency functions.
Oblivious sorting and 0-1 lemma
Oblivious sorting algorithms are easy to design and analyze due to so called 0-1 Sorting Lemma. It says that if a sorting network works correctly for any input sequence of 0's and 1's, then it works correctly on any input taken from any linearly ordered set, for example integers or reals. It is extremely useful for proving correctness and/or complexity of oblivious sorting algorithms. To prove it, we need an auxiliary result.
Lemma
Let f be a monotonically increasing function on a linearly ordered set S, i.e.,
for all x,y in S; x<= y iff f(y)<= f(y).
If a comparator network transforms an input sequence X=x1,...,xn of elements from S into an output sequence Y=y1,...,yn, then it transforms the input sequence f(X)=f(x1),...,f(xn) into the output sequence f(Y)=f(y1),...,f(yn).
Proof
(By induction on the depth of the network.)
- A single comparator is oblivious to f.
- Consider a comparator with input values x and y.
- Then its upper output will be min(x,y) and lower output max(x,y).
- If we apply inputs f(x) and f(y), we will get min(f(x),f(y)) on the upper output and max(f(x),f(y)) on the lower output.
- Since f is monotonically increasing, x<= y implies f(x)<= f(y).
- But this implies that min(f(x),f(y))=f(min(x,y)) and max(f(x),f(y))=f(max(x,y)).

CAPTION: Proof that one comparator is oblivious to any monotonically increasing function f.
Hence, we have shown that
for x,y in S, a comparator exchanges f(x) and f(y) iff it exchanges x and y.
-
Induction step. Using induction on the depth of the network, we can prove even a stronger statement than is the lemma:
If a wire in the network carries value xi when the input sequence is X, then it carries value f(xi) when the input is f(X).
- Basis of induction (trivial): If an input wire at depth 0 carries xi, then it carries f(xi) after applying f(X) to the network.
- The induction step:
- Assume that the induction hypothesis holds for all wires of depth d-1, d>= 1.
- Take any wire of depth d. It is an output wire of a comparator whose input wires are at depth strictly less than d.
- By induction hypothesis, if these input wires carry xi and xj when the input sequence X is applied, then they must carry f(xi) and f(xj) when f(X) is applied.
- Since the comparator is oblivious to f, its output wires will carry f(min(xi,yj)) and f(max(xi,yj)).
- But the same output wires carried min(xi,yj) and max(xi,yj) when the input sequence X was applied.
Lemma
(The 0-1 Sorting Lemma.)
If a comparison network with N inputs sorts all 2N possible sequences of 0's and 1's correctly, then it sorts all input sequences of arbitrary numbers correctly.
Proof
(By contradiction.)
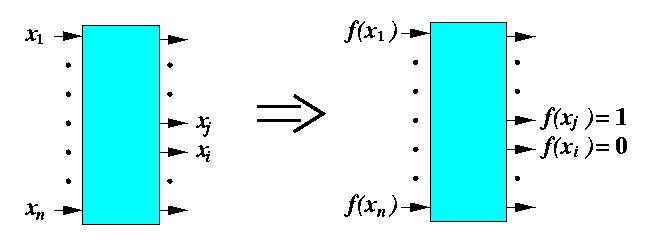
CAPTION: A failure to sort X leads to a failure to sort a binary sequence.
Mesh-based oblivious sorting
Even-odd transposition sorting on 1-D meshes
This algorithm is also called parallel bubble-sort. It takes precisely N steps to sort N numbers on M(N), which is optimal due to the diameter argument. The cost of the algorithm is therefore O(N2). The idea is obvious: alternate CE operations between odd-even and even-odd adjacent pairs of nodes. Let x1,..,xN be a sequence of numbers to be sorted rightward in ascending order.
|
for j=1...[ N/2] do_sequentially
begin
for i=1,3,..,2[ N/2]-1 do_in_parallel
if xi > xi+1 then CE(xi,xi+1);
for i=2,4,..,2[ (N-1)/2] do_in_parallel
if xi > xi+1 then CE(xi,xi+1);
end
Lemma
Even-odd transposition algorithm sorts N numbers on M(N) in N steps.
Proof
Using 0-1 Sorting Lemma, assume an input sequence of k 1's and N-k 0's, for any 1<= k<= N-1, arbitrarily scrambled. By induction on k, we can show that the algorithm will move the k 1's into positions N-k+1,..,N within N steps.
- The rightmost 1 has only 0's on its right hand, so it starts moving to the right at latest in the second step and keeps moving without interruption until it reaches its final position.
- The second rightmost element starts moving at latest in the third step, and proceeds similarly.
- Finally, the k-th rightmost 1 starts moving in (k+1)-th step to reach position N-k+1.
- Therefore, in the worst case, the total number of steps is k+(N-k)=N.
Consider an even-odd transposition sort of N > p numbers on p processors. Since p nodes must perform sequentially p CS operations with N/p numbers and one such operation takes \Theta(N/p) CE operations in each processor and communication latency of an exchange of N/p numbers between adjacent nodes is also \Theta(N/p), the total parallel time is
T(N,p)=\Theta((N/p)log(N/p))+\Theta(N).
Hence,
- the parallel time is \Omega(N),
- the parallel time is O(N) only if p=\Omega(log N),
- E(N,p)=O(1) only if p=O(log N).
The scalability of even-odd transposition sort is therefore very poor, since to keep a constant efficiency, input data size must grow exponentially with the number of processors.
ShearSort on 2-D meshes
The simplest 2-D mesh sorting algorithm is called ShearSort and it is based on the even-odd transposition. It works for any 2-D mesh. Consider M(n,m), n rows and m columns.
for i=1,..., 2log n+1 do_sequentially
if (i is odd)
then SORT_ALL_ROWS_SNAKELIKE ( Figure, Phase 1,3,5)
else SORT_ALL_COLUMNS ( Figure, Phase 2,4)
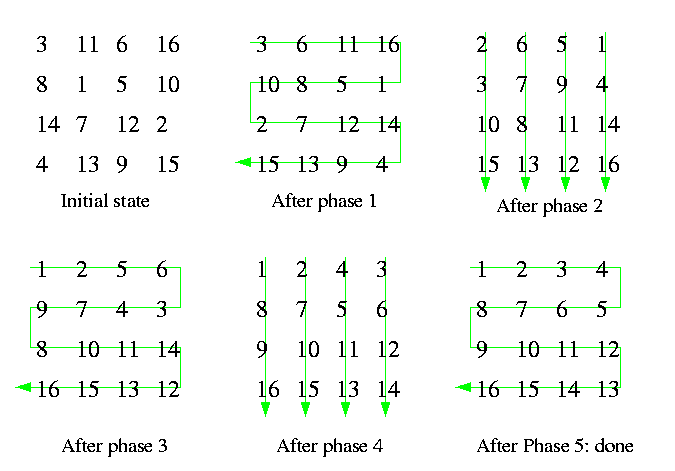
CAPTION: Five phases of ShearSort on M(4,4).
Shearsort on M(n,m) consists of 2log n+1 phases. In odd-numbered phases, individual rows are sorted alternately rightward and leftward. In even-numbered phases, individual columns are sorted downward. In both cases, we can use even-odd transposition sorting. Figure shows five phases of ShearSort on M(4,4).
Lemma
ShearSort needs [log n]+1 row phases and [log n] column phases to sort nm numbers on M(n,m) in a snakelike order.One row (column) phase takes \Theta(n) (\Theta(m), respectively) computational and communication steps.
Proof
(By 0-1 Sorting Lemma.)
- Assume any zero-one n× m matrix. It may contain rows of three kinds.
- all-one rows containing only 1's,
- all-zero rows containing only 0's,
- dirty rows containing both 0's and 1's.
- Initially, the input matrix can contain n dirty rows in the worst case.
- The final matrix sorted snakelike contains at most one dirty row.
- Proposition: One row and one column phase reduce the number of dirty rows to at least one half.
|
|
Proof. By a simple case analysis. Consider all dirty rows after one row phase. One half of them is sorted rightward, whereas the other half reversely. If we consider pairs of leftward and rightward rows, there can exist pairs of at most three different types, as shown on Figure .
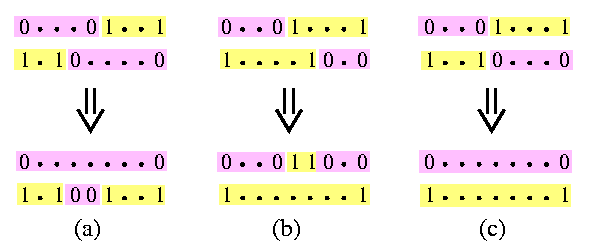
CAPTION: Three kinds of pairs of dirty rows.
After applying one column phase, one dirty row disappears in cases (a) and (b), and both dirty rows disappear in case (c).
Hence, after 2log n phases, at most one dirty row remains and one more row sort completes sorting.
It is noteworthy that if the rows were sorted in a row-major order instead of in a snakelike order, then the algorithm will not sort.
Unfortunately, ShearSort is not optimal. Improvements based on decreasing number of dirty rows help only a little. In Section #16, we will describe an asymptotically optimal 2-D mesh sorting algorithm.
Lower bound on 2-D mesh snakelike sorting
The trivial lower bound on parallel sorting on a 2-D mesh M(n,n) is 2n-2, the diameter of the mesh. If the snakelike order is required, the lower bound on the number of CE steps for oblivious sorting on a 2-D mesh is greater than the trivial diameter-based one.
Lemma
Any oblivious snakelike sorting on mesh M(n,n) requires at least 3n-2\sqrt(n)-4 CE steps.
Proof
(Constructive.) Let N=n2. Assume any snakelike-order sorting algorithm A.
Lexicographic sorting on 3-D meshes
Consider the problem of sorting n3 numbers on M(n,n,n) in lexicographic zyx-order. Surprisingly, there is an algorithm which needs just five (!) phases, where one phase sorts numbers within 2-D planes. It works as follows.
Phase 1. | sort all xz-planes in zx-order;
Phase 2. | sort all yz-planes in zy-order;
Phase 3. | sort all xy-planes in yx-order snakelike (in direction y);
Phase 4. | perform one odd-even and one even-odd transposition within all columns in parallel;
Phase 5. | sort all xy-planes in yx-order.
Proof
(by 0-1 Sorting Lemma) Consider any input sequence of 0's and 1's.
- After Phase 1, in every xz-plane, there is at most one dirty row and therefore:
- any two yz-planes can differ in at most n 0's,
- and all n yz-planes contain in their dirty rows at most n2 elements.
- Therefore, after Phase 2, all dirty rows can span at most 2 xy-plane.
- If the dirty xy-plane is just one, we can go directly to Phase 5 and we are done,
- If there are 2 dirty xy-planes, Phases 3 and 4 eliminate at least one of them and Phase 5 completes the sorting.
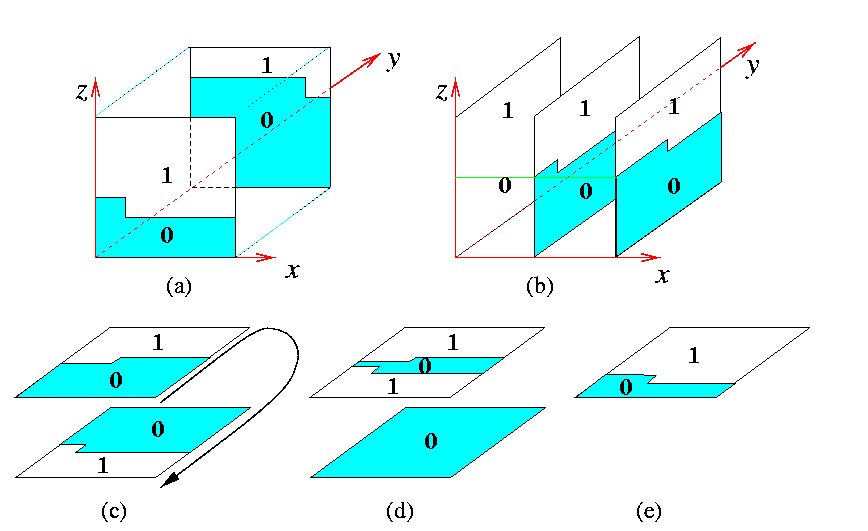
CAPTION: 3-D mesh lexicographic sorting.
| |