Lecture
19: BSTs
lookup(k)
1.
if the tree is empty, return false
2.
if given key is at the root, return true
3.
if the given key is less than the value in
the root,
return
lookup on the left subtree
4.
if the given key is greater than the value
in the root,
return
lookup on the right subtree
want
a recursive method with two parameters:
key & root
thus, use an
auxiliary method
public Boolean lookup(Comparable k) {
return lookup(root,k); // lookup is overloaded
}
private static Boolean lookup(Bnode n, Comparable k) {
if (n == null) return false; // base case
if (n.key.equals(k)) return true;
// base case
if (k.compareTo(n.key) < 0) return lookup(n.left,
k);
else return lookup(n.right, k);
}
Simulate
together:
lookup(3)
lookup(4)
6 3 4 155 2![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() lookup(9)
lookup(9)
sound
effects:
empty
(null): bird; look left: slide up
value found: bell;
look right: slide down
Runtime
efficiency for lookup
·
always follows a path from the root down
·
worst case:
goes all the way to a leaf
thus,
worst case time is proportional to height of the tree
how
is the height related to N = # keys
in the tree?
·
depends on the shape of the tree
o
best case:
tree is balanced
all
non-leaf nodes have 2 children
all
leaves are at depth = height =
O(log N)
o
worst case:
tree is linear
all
non-leaf nodes have just one child
height
is O(N)
Summary
·
worst case time for lookup: O(h),
h = height of tree
·
worst of the worst: height is O(N), N =
# nodes in tree
·
for approx. balanced tree: h ~ log N
Note: log N is much better than N for large N
N: 32 64
128 … 1024
1,000,000
log
N: 5 6
7 … 10
20
insert(k)
·
a new value is always inserted as a leaf
·
must choose position to respect BST
ordering
algorithm:
1.
if BST is empty, make the new value be at
the root
2.
else,
·
find node that will be the parent of the
new node
(using "binary search")
parent
either has key ³
new key & null left pointer
or key < new key
& null right pointer
·
create new node and make it the appropriate
child of the parent
public void insert(
Comparable k ) throws DupException{
if (root == null) root = new Bnode(key,
null, null);
else insert(root, key);
}
private static void insert( Bnode
T, Comparable k)
throws DuplicateException{
//
precondition: T !=
null
if (k.equals(T.key))
throw new DuplicateException();
if (k.compareTo(T.key)<0) { // k
< T.key
if(T.left == null) T.left = new Bnode(k,null,null);
else insert(T.left, k); // T.left is not
null
}
else { //k > T.key
// do the
same thing with the right subtree
}
}
simulate
with: initial name & 4 further names
BST t = new BST();
t.insert(“Mary”);
root t “Mary” left key right
![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
(four randomly
selected students each insert their
names)
Note: for random values, tree stays approximately
balanced
Runtime
efficiency for insert:
·
similar to lookup
follow
a path from root to leaf, O(h)
worst
case: O(N)
approximately
balanced tree: O(log N)
You
try:
draw
the BSTs produced by the following sequences of
inserts
1.
5 3 7 6 2 1
2.
1 2 3 4 5 6 7
3.
4 3 5 2 6 1 7
Solutions:
1. 5 3 7
6 2 1
![]()
![]() 5
5
![]()
![]()
![]() 3 7
3 7
![]() 2 4 6
2 4 6
1
2. 1 2
3 4 5
6 7
![]() 1
1
![]() 2
2
![]() 3
3
![]() 4
4
![]() 5
5
![]() 6
6
7
3. 4 3
5 2 6
1 7
![]()
![]() 4
4
![]()
![]() 3 5
3 5
![]() 2 6
2 6
![]() 1
7
1
7
BSTs: delete(k)
·
find the node n to be deleted
·
different actions depending on how many
children n has
case
1: n
has no children (n is a leaf) – set ptr to n to null
e.g., delete(3) on
following tree:
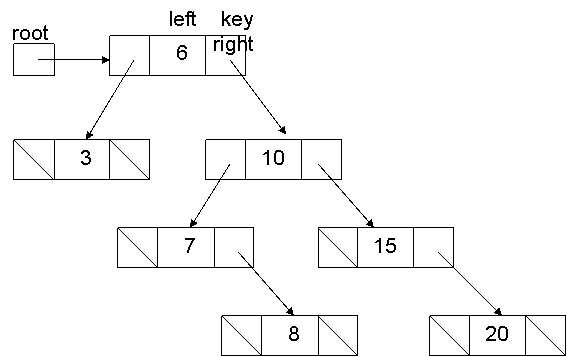
case
2: n
has one child
-
replace pointer to n with pointer to c
e.g., delete
(15) on the above tree
case
3: n
has two children – e.g., delete(10)
·
can't replace ptr
to n with pointer to both of n's kids
·
instead, replace key in n
with
a value from a node further down in tree
which value?
either the largest
value in the left subtree
or the smallest
value in the right subtree
then,
recursively delete that node from the subtree
simulate:
find
the largest value in the left subtree of 10
start at root
of left subtree, go right, right, right…
replace
the key to be deleted with that value
delete
the value from the left subtree
You try:
·
find a partner
·
build a BST:
alternate
telling partner a word to insert (10 times)
·
destroy the BST:
alternate
telling partner what word to delete
time for delete(k):
·
find the node to be deleted:
follow
a path from root to that node
·
if has 2 children, find largest key in L subtree
continue
down path toward a leaf
·
recursively delete k
follow
same path as in finding largest key
thus,
in the worst case,
a
path from root to a leaf is followed twice
i.e.,
worst-case time is O(h), where h is height of tree
Summary
·
use BSTs to store
Comparable keys (and assoc. data)
·
lookup, insert, delete are easy to
implement
·
all operations have worst case time O(h)
o
worst case h =
N, where N =
number of nodes
o
average case h =
log(N)
·
log(N) is much better than N,
so
on average, the operations are very efficient
(will see this on programming assignment 4)