Comprehensive Image Captioning via Scene Graph Decomposition
Yiwu Zhong1, Liwei Wang2, Jianshu Chen2, Dong Yu2, Yin Li1
1University of Wisconsin-Madison, USA
2Tencent AI Lab, Bellevue, USA
ECCV 2020, Glasgow, UK
We address the challenging problem of image captioning by revisiting the representation of image scene graph. The core of our method is the decomposition of a scene graph into a set of sub-graphs, with each sub-graph capturing a semantic component of the input image. We design a deep model to select important sub-graphs, and to decode each selected sub-graph into a single target sentence. By using sub-graphs, our model is able to attend to different components of the image. Our method thus accounts for accurate, diverse, grounded and controllable captioning at the same time. We present extensive experiments to demonstrate the benefits of our comprehensive captioning model. Our method establishes new state-of-the-art results in caption diversity, grounding, and controllability, and also compares favorably to latest methods in caption quality.
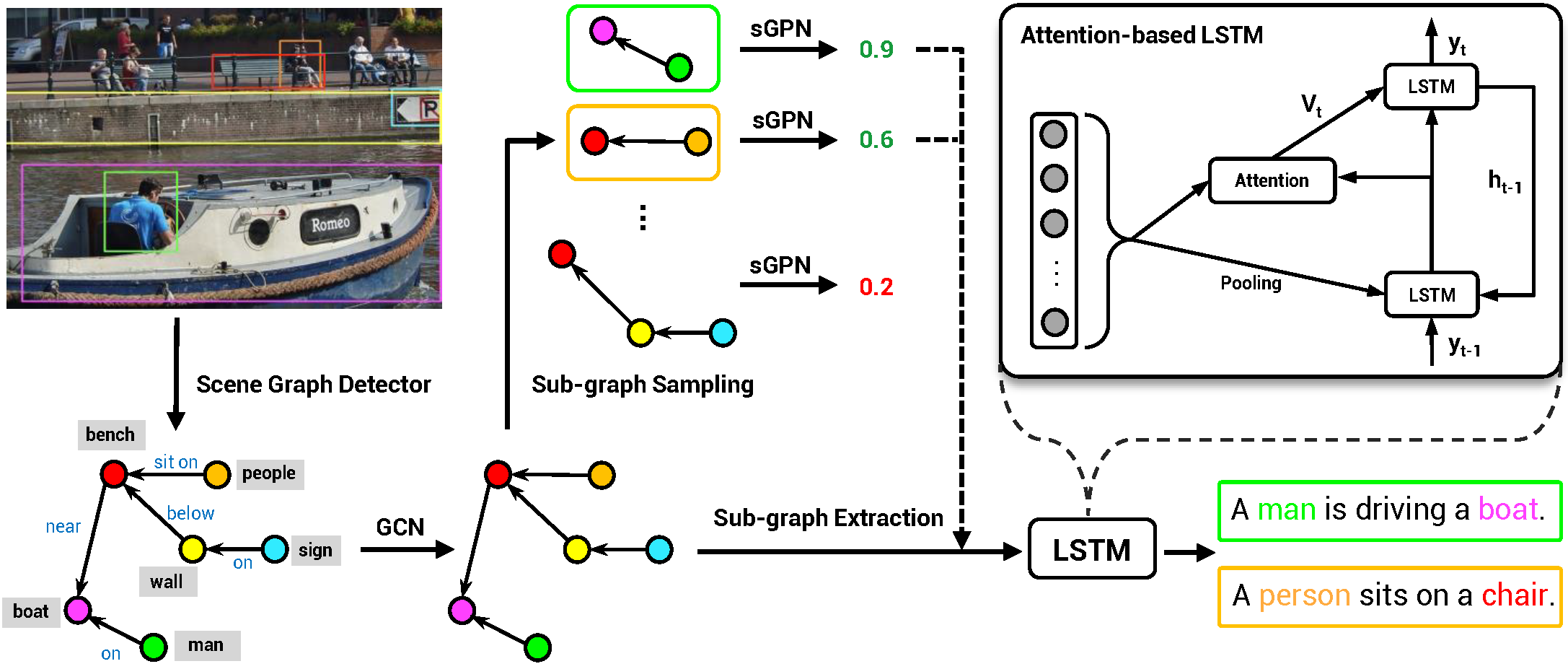
Given an input image, our method starts with an extracted scene graph, including object regions and relationships between the objects. Our model further decomposes the scene graph into a set of sub-graphs. We design a sub-graph proposal network (sGPN) that learns to identify meaningful sub-graphs. These sub-graphs are further decoded by the attention-based LSTM for generating sentences and grounding sentence tokens into sub-graph nodes (image regions). By leveraging sub-graphs, our model enables accurate, diverse, grounded and controllable image captioning.
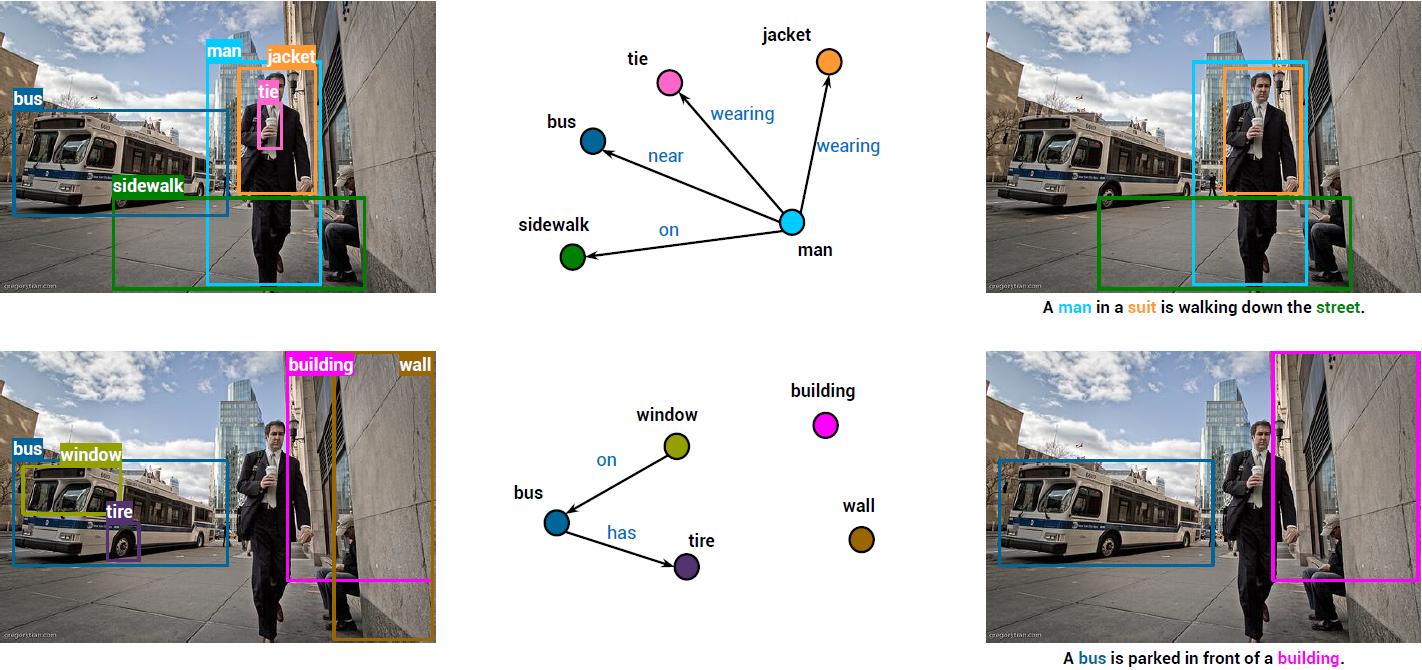
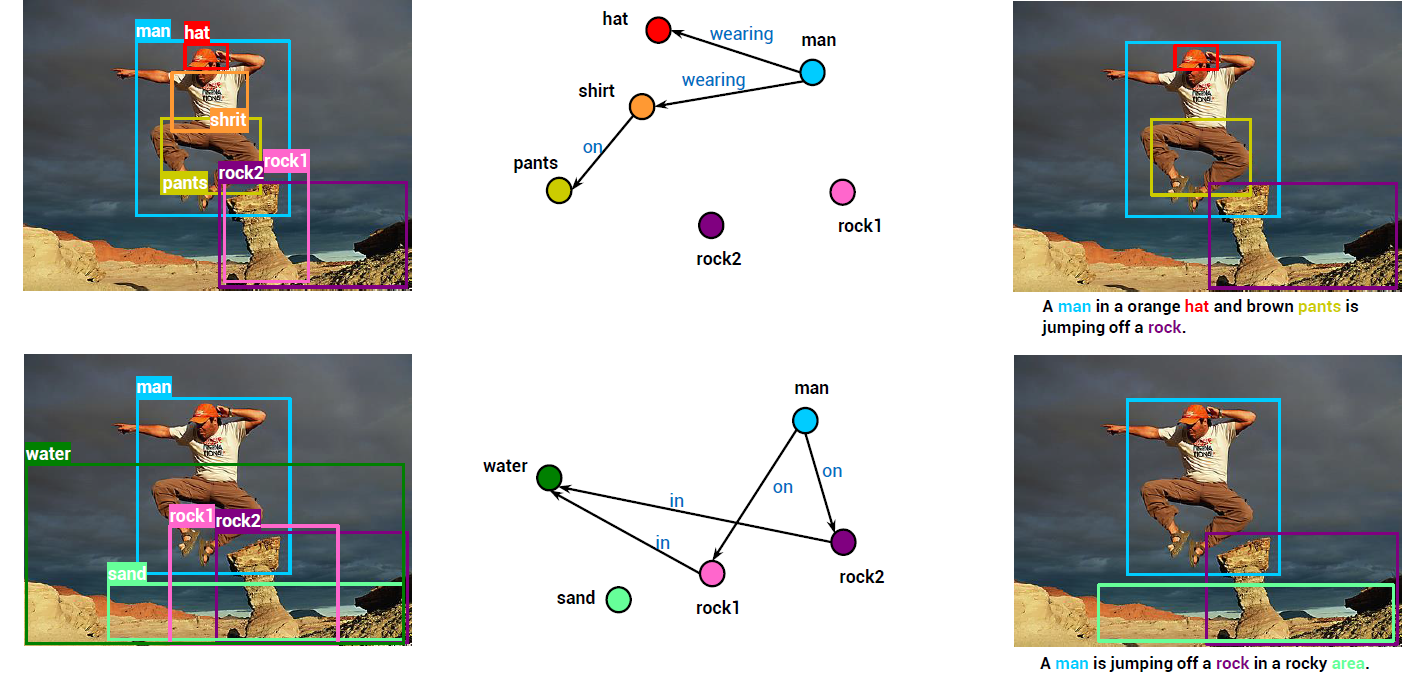
Diverse and grounded captioning results on Flickr30k Entities test set. Each row presents the result from a single sub-graph. From left to right: input image and detected objects associated with the sub-graph, sub-graph nodes and edges used to decode the sentences, and the generated sentence grounded into image regions. Decoded nouns and their corresponding grounding regions are shown in the same color.
This work was partially developed when the first author was an intern at Tencent AI Lab, Bellevue, USA, and further completed at UW-Madison. YZ and YL acknowledge the support by the UW-Madison Office of the Vice Chancellor for Research and Graduate Education with funding from the Wisconsin Alumni Research Foundation.