CS766 Course Project
Motion Detection and Gesture
Recognition
in a Constrained Setting
Min
Zhong, Wanli Yang
{zhong, ywl} @cs.wisc.edu
Computer Science Department
UW-Madison
December 12th,
2000
Problem Formulation and Proposed solution
It is often useful to identify occurrences of certain gestures in a video for behavioral studies, for example, in studying presentation style in a classroom setting or performer style on a theater stage. There are two components that are crucial to the success of a gesture detector: one is the ease of specifying the target gesture, and the other is the accuracy of the match. In this project, we present an approach to resolve these two problems in a constrained setting.
Since such behavior studies often occur in a fixed setting, we optimize our search to focus on the case where there is a central character and an audience in the foreground. We also assume the video is taken by a static camera focusing on the main character and that we are mainly interested in the upper body motions. In this project, we use taped lecture videos as input source.
We believe it is important to allow the user to formulate the desired gesture without requiring one to be an artist or to search for an occurrence of the gesture in the source video. This means that the gesture template does not need to be in scale with the input video and that its pose needs only to convey the general intent, not the specific character resemblance. It is also important that the detector be accurate as well as prompt in returning the answers.
The proposed approach efficiently matches upper body gestures in videos or image sequences given a simple sketch drawing of the pose. The main challenges are the high noise environment (audience motion affects the identification of the main character motion) and the small area of interest (the input video consist of long shots from the back of the room).
The design is modularized into two main components. First the main character is isolated from each frame, and then gesture matching is performed against the template. We illustrate our ideas with a few examples.
1.Bounding box Finder
Input: Video sequence http://www.cs.wisc.edu/~zhong/cs766/imgs/lecture.MPG.
2200 frames, 320x240.
Output: Video sequence http://www.cs.wisc.edu/~zhong/cs766/imgs/lectBox.MPG.
200 frames, 320 x 240. This is a sampled subsequence to illustrate an application for the main character isolation process. It begins sampling at frame 200 of the original and is sampled at every 5 frames.
2. A Gesture Matching example
Input:
The original input video as in example 1 and a black and white upper body gesture sketch (320 x 240), left in Fig 1.
|
Template(320x240) |
(Template cropped to show detail) |
frame1872 (320x240) classified as a match |

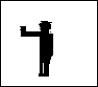

Figure 1 A gesture template (left image used in matching)
Output: Video sequence http://www.cs.wisc.edu/~zhong/cs766/imgs/match_ptlt.MPG. This is a collection of the 11 frames that were identified as matches. Details explained in later sections.
3. Another Gesture Matching example, template of a different size
Input:
-The original input video used in example 2.
-The template sketch in example 2 shrunk (256x192), left in Fig 2.
- Same matching threshold as in the previous example.
|
Template(256x192) |
frame 451 (320x240) classified as match |
frame 786 (320x240) falsely classified as match |



{kind=link}
{kind=link}
Figure 2 A small gesture template (left image used in matching)
Output: Video sequence http://www.cs.wisc.edu/~zhong/cs766/imgs/match_ptltSm.MPG.
This is a collection of the 29 frames that were identified as matches. There are 2 mismatches out of the 29. Details explained in later sections.