Due Friday, November 4 at 11:59pm
This assignment is designed to support your in-class understanding of how in-memory data analytics stacks and stream processing engines work. You will deploy SPARK, an in-memory big data analytics framework and one of the most popular open source projects nowadays. You will learn how to write native Spark applications and understand the factors that influence it's performance. Next, you will learn how to write streaming applications using Structured Streaming, SPARK's latest library to support development of end-to-end streaming applications. Lastly, you will deploy Apache Storm, a stream processing engine to process real tweets. As in assignment 1, you will produce a short report detailing your observations, scripts and takeaways.
After completing this assignment, you should:
We have provided a set of 5 VMs to every group; these are all hosted in CloudLab. One VM has a public IP which is accesible from the external world. All VMs have a private IP and are reachable from each other. In your setup, you should designate the VM with a public IP to act as a master/slave while the others are assigned as slaves only. In the following, when we refer to a master, we refer to either the VM designated as the master, or to a process running on the master VM.
To prepare your VMs for the big data analytics stack deployment, we have performed the following steps:
Before proceeding, please ensure all the above steps have been done on your VMs.
The following will help you deploy all the software needed and set the proper configurations required for this assignment. You need to download the following configuration archive on every VM, and place the uncompressed files in /home/ubuntu/conf. In addition, download and deploy the run.sh script in your home directory (/home/ubuntu) on every VM. The script enables you to start and stop Hadoop services and configure various environment variables. To function properly, it requires an machines file which contains the IP addresses of all the slave VMs where you plan to deploy your big data software stack, one per line. For example, if you plan to deploy slave processes on VMs with IPs 10.0.1.2, 10.0.1.3, 10.0.1.4, your machines file will look like:
10.0.1.2The run.sh script used in assignment-1 incorporates additional information required to run the SPARK stack. It defines new environment variables and new commands to start and stop your SPARK cluster.
Be sure to replaace the SPARK_MASTER_IP and SPARK_MASTER_HOST with the private IP of your master VM in run.sh.
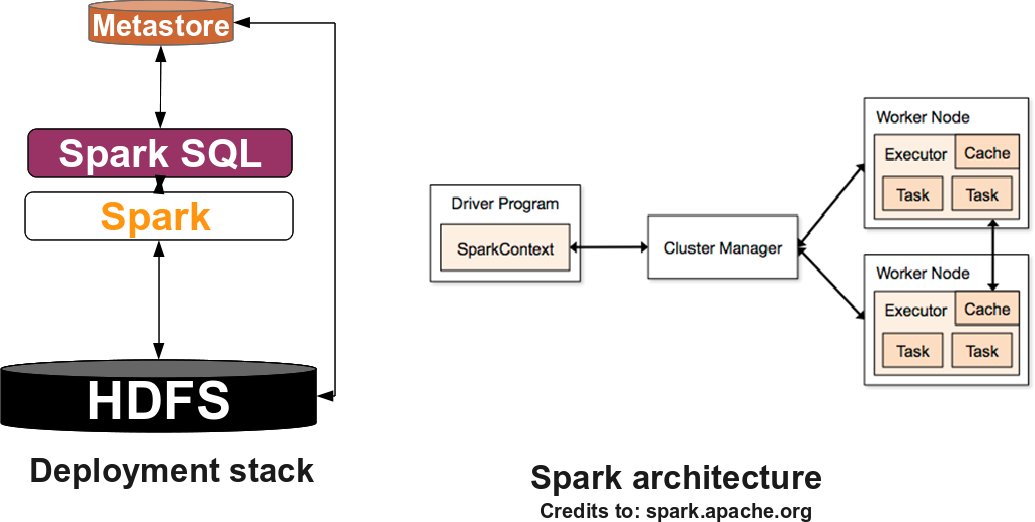
Next, we will go through deploying Hadoop and Hive (as done in the previous assignment), the Spark stack as well as the Storm stack. The following figure describes the Spark software stack you will deploy:
The first step in building your big data stack is to deploy Hadoop. Hadoop mainly consists of two parts: a distributed filesystem called HDFS and a resource management framework known as YARN. As you will learn in the class, HDFS is responsible for reliable management of the data across the distributed system, while YARN handles the allocation of available resources to existing applications.
To become familiar with the terminology, HDFS consists of a master process running on the master instance, called NameNode and a set of slave processes one running on each slave instance called DataNode. The NameNode records metadata information about every block of data in HDFS, it maintains the status of the DataNodes, and handles the queries from clients. A DataNode manages the actual data residing on the corresponding instance. Similarly, in YARN there is a master process known as ResourceManager which maintains information about the available instances/resources in the system and handles applications resource requests. A NodeManager process is running on every instance and manages the available resources, by periodically "heartbeating" to the ResourceManager to update its status.
Now that you know the terminology, download hadoop-2.6.0.tar.gz. Deploy the archive in the /home/ubuntu/software directory on every VM and untar it (tar -xzvf hadoop-2.6.0.tar.gz).
You should modify core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml in your /home/ubuntu/conf directory on every VM and replace the master_ip with the private IP of your master VM.
Before launching the Hadoop daemons, you should set the proper environment variables from the script run.sh and format the Hadoop filesystem. To enable the environment variables you need to run the command: source run.sh. To format the filesystem (which simply initializes the directory specified by the dfs.namenode.name.dir) run the command: hadoop namenode -format. Finally, you can instantiate the Hadoop daemons by running start_all in your command line on the master VM. To check that the cluster is up and running you can type jps on every VM. Each VM should run the NodeManager and DataNode processes. In addition, the master VM should run the ResourceManager, NodeManager, JobHistoryServer, ApplicationHistoryServer, Namenode, DataNode. The processesJobHistoryServer and ApplicationHistoryServer are history servers designed to persist various log files for completed jobs in HDFS. Later on, you will need these logs to extract various information to answer questions in your assignment. In addition, you can check the status of your cluster, at the following URLs: To test that your Hadoop cluster is running properly, you can run a simple MapReduce application by typing the following command on the master VM: Hive is a data warehouse infrastructure which provides data summarization, query, and analysis. To deploy Hive, you also need to deploy a metastore service which stores the metadata for tables and partitions in a relational database, and provides Hive access to this information via the metastore service API. To deploy the metastore service you need to do the following: You should modify hive-site.xml in your /home/ubuntu/conf directory on the master VM and replace the master_ip with it's IP. Finally, download and untar hive-1.2.1.tar.gz in /home/ubuntu/software on the master VM. If you type hive in the command line, you should be able to enter hive console >hive. You will use HDFS as the underlying
filesystem. To become familiar with the terminology, SPARK standalone consists of a set of daemons: a Master daemon, which is the equivalent of the ResourceManager in YARN terminology, and a set of Worker daemons, equivalent to the NodeManager processes. SPARK applications are coordinated by a SparkContext object which will connect to the Master, responsible for allocating resources across applications. Once connected, SPARK acquires Executors on every Worker node in the cluster, which are processes that run computations and store data for your applications. Finally, the application's tasks are handled to Executors for execution. You can read further about the SPARK architecture here. Now that you are familiar with the SPARK terminology, download spark-2.0.0-bin-hadoop2.6.tgz . Deploy the archive in the /home/ubuntu/software directory on every VM and untar it (tar -xzvf spark-2.0.0-bin-hadoop2.6.tgz).
Apache Hive
Apache Spark
You should modify hive-site.xml and set the hive.metastore.uris property to thrift://ip_master:9083.
Finally, you can instantiate the SPARK daemons by running start_spark on your Master VM. To check that the cluster is up and running you can check that a Master process is running on your master VM, and a Worker is running on each of your slave VMs. In addition you can check the status of your SPARK cluster, at the following URLs:
Apache Storm has its own stack, and it requires Apache Zookeeper for coordination in cluster mode. To install Apache Zookeeper you should follow the instructions here. First, you need to download zookeeper-3.4.6.tar.gz, and deploy it on every VM in /home/ubuntu/software. Next, you need to create a zoo.cfg file in /home/ubuntu/software/zookeeper-3.4.6/conf directory. You can use zoo.cfg as a template. If you do so, you need to replace the VMx_IP entries with your corresponding VMs IPs and create the required directories specified by dataDir and dataLogDir. Finally, you need to create a myid file in your dataDir and it should contain the id of every VM as following: server.1=VM1_IP:2888:3888, it means that VM1 myid's file should contain number 1.
Next, you can start Zookeeper by running zkServer.sh start on every VM. You should see a QuorumPeerMain process running on every VM. Also, if you execute zkServer.sh status on every VM, one of the VMs should be a leader, while the others are followers.
A Storm cluster is similar to a Hadoop cluster. However, in Storm you run topologies instead of "MapReduce" type jobs, which eventually processes messages forever (or until you kill it). To get familiar with the terminology and various entities involved in a Storm cluster please read here.
To deploy a Storm cluster, please read here. For this assignment, you should use apache-storm-1.0.2.tar.gz. You can use this file as a template for the storm.yaml file required. To start a Storm cluster, you need to start a nimbus process on the master VM (storm nimbus), and a supervisor process on any slave VM (storm supervisor). You may also want to start the UI to check the status of your cluster (PUBLIC_IP:8080) and the topologies which are running (storm ui).
For Part-A of this assignment, you will write a simple Spark application to compute the PageRank for a number websites and analyze the performance of your application under different scenarios. For this part, ensure that only the relevant Spark and HDFS daemons are running. You can start HDFS daemons using the start_hdfs command and Spark daemons using the start_spark command available through run.sh from your master VM. Ensure that all other daemons are stopped.
PageRank is an algorithm that is used by Google Search to rank websites in their search engine results. This algorithm iteratively updates a rank for each document by adding up contributions from documents that link to it. The algorithm can be summarized in the following steps - For detailed information regarding PageRank please read here. For the purpose of this assignment, we will be using the Berkeley-Stanford web graph and execute the algorithm for a total of 10 iterations. Each line in the dataset consists of a URL and one of it's neighbors. You are required to copy this file to HDFS. For the questions that follow, please ensure that your application's SparkContext or SparkSession object is overwriting the following properties:
Documentation about how to create a SparkContext and set various properties is available here. Question 1. Write a Scala/Python/Java Spark application that implements the PageRank algorithm without any custom partitioning (RDDs are not partitioned the same way) or RDD persistence. Your application should utilize the cluster resources to it's full capacity. Explain how did you ensure that the cluster resources are used efficiently. (Hint: Try looking at how the number of partitions of a RDD play a role in the application performance) Question 2. Modify the Spark application developed in Question 1 to implement the PageRank algorithm with appropriate custom partitioning. Is there any benefit of custom partitioning? Explain. (Hint: Do not assume that all operations on a RDD preserve the partitioning) Question 3. Extend the Spark application developed in Question 2 to leverage the flexibility to persist the appropriate RDD as in-memory objects. Is there any benefit of persisting RDDs as in-memory objects in the context of your application? Explain. With respect to Question 1-3, for your report you should: Question 4. Analyze the performance of CS-838-Assignment2-PartA-Question2 by varying the number of RDD partitions from 2 to 100 to 300. Does increasing the number of RDD partitions always help? If no, could you find a value where it has a negative impact on performance and reason about the same.
Question 5. Visually plot the lineage graph of the CS-838-Assignment2-PartA-Question3 application. Is the same lineage graph observed for all the applications developed by you? If yes/no, why? The Spark UI does provide some useful visualizations. Question 6. Visually plot the Stage-level Spark Application DAG (with the appropriate dependencies) for all the applications developed by you till the second iteration of PageRank. The Spark UI does provide some useful visualizations. Is it the same for all the applications? Id yes/no, why? What impact does the DAG have on the performance of the application? Question 7. Analyze the performance of CS-838-Assignment2-PartA-Question3 and CS-838-Assignment2-PartA-Question1 in the presence of failures. For each application, you should trigger two types of failures on a desired Worker VM when the application reaches 25% and 75% of its lifetime. The two failure scenarios you should evaluate are the following:
You should analyze the variations in application completion time. What type of failures impact performance more and which application is more reslient to failures? Explain your observations. Notes: This part of the assignment is aimed at familiarizing you with the process of developing simple streaming applications on big-data frameworks. You will use Structured Streaming (Spark's latest library to build continuous applications) for building your applications. It is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data. Structured Streaming has a new processing model that aids in developing end-to-end streaming applications. Conceptually, Structured Streaming treats all the data arriving as an unbounded input table. Each new item in the stream is like a row appended to the input table. The framework doesn't actually retain all the input, but the results will be equivalent to having all of it and running a batch job. A developer using Structured Streaming defines a query on this input table, as if it were a static table, to compute a final result table that will be written to an output sink. Spark automatically converts this batch-like query to a streaming execution plan. Before developing the streaming applications, students are recommended to read about Structured Streaming here. For this part of the assignment, you will be developing simple streaming applications that analyze the Higgs Twitter Dataset. The Higgs dataset has been built after monitoring the spreading processes on Twitter before, during and after the announcement of the discovery of a new particle with the features of the Higgs boson. Each row in this dataset is of the format <userA, userB, timestamp, interaction> where interactions can be retweets (RT), mention (MT) and reply (RE). We have split the dataset into a number of small files so that we can use the dataset to emulate streaming data. Download the split dataset onto your master VM. Question 1. One of the key features of Structured Streaming is support for window operations on event time (as opposed to arrival time). Leveraging the aforementioned feature, you are expected to write a simple application that emits the number of retweets (RT), mention (MT) and reply (RE) for an hourly window that is updated every 30 minutes based on the timestamps of the tweets. You are expected to write the output of your application onto the standard console. You need to take care of choosing the appropriate output mode while developing your application.
In order to emulate streaming data, you are required to write a simple script that would periodically (say every 5 seconds) copy one split file of the Higgs dataset to the HDFS directory your application is listening to. To be more specific, you should do the following - Question 2. Structured Streaming offers developers the flexibility is decide how often should the data be processed. Write a simple application that emits the twitter IDs of users that have been mentioned by other users every 10 seconds. You are expected to write the output of your application to HDFS. You need to take care of choosing the appropriate output mode while developing your application. You will have to emulate streaming data as you did in the previous question. Question 3. Another key feature of Structured Streaming is that it allows developers to mix static data and streaming computations. You are expected to write a simple application that takes as input the list of twitter user IDs and every 5 seconds, it emits the number of tweet actions of a user if it is present in the input list. You are expected to write the output of your application to the console. You will have to emulate streaming data as you did in the previous question. Notes: For Part-C of this assignment, you will write simple Storm applications to process tweets. For this part, ensure that only the relevant Storm daemons are running and all other daemons are stopped.
To write a Storm application you need to prepare the
development environment. First, you need to untar apache-storm-1.0.2.tar.gz
on your local machine. If you are using Eclipse please continue reading
otherwise skip the rest of this paragraph. First, you need to generate the
Eclipse related projects; in the main storm directory, you should run:
mvn eclipse:clean; mvn eclipse:eclipse
-DdownloadSources=true -DdownloadJavadocs=true. (We assume you
have installed a maven version higher than 3.0 on your local machine).
Next, you need to import your projects into Eclipse. Finally, you should
create a new classpath variable called M2_REPO which
should point to your local maven repository. The typically path is /home/your_username/.m2/repository.
Once you open the Storm projects, in apache-storm-1.0.2/examples/storm-starter, you will find
various examples of Storm applications which will help you understand how to
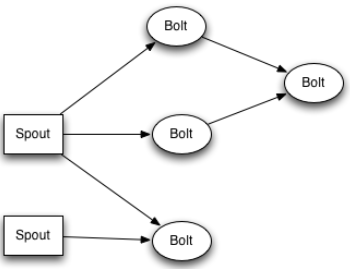
write / structure your own applications. The figure below shows an example of a typical Storm topology: The core abstraction in Storm is the We recommend you place your Storm applications in the same
location as the other Storm examples (storm-starter/src/jvm/storm/starter/PrintSampleStream.java in 0.9.5 version and storm-starter/src/jvm/org/apache/storm/starter/PrintSampleStream.java in 1.0.2 version).To rebuild the examples, you should run: mvn clean install
-DskipTests=true; mvn package -DskipTests=true in the storm-starter directory. target/storm-starter-0.9.5-jar-with-dependencies.jar will contain the "class" files of your "topologies". To run a "topology" called "CS838Assignment" in either local or cluster mode, you should execute the following command:PageRank Algorithm
Questions
Part B - Structured Streaming

Questions
Part C - Apache Storm
Prepare the development environment
Typical Storm application
For rebuilding the examples in 1.0.2 version, look at the documentation here.
In this assignment, your topologies should declare a spout which connects to the Twitter API and emits a stream of tweets. To do so, you should do the following steps:
Question 1. To answer this question, you need to extend the PrintSampleStream.java topology to collect tweets which are in English and match certain keywords (at least 10 distinct keywords) at your desire. You should collect at least 500'000 tweets which match the keywords and store them either in your local filesystem or HDFS. Your topology should be runnable both in local mode and cluster mode.
Question 2. To answer this question, you need to create a new topology which provides the following functionality: every 30 seconds, you should collect all the tweets which are in English, have certain hashtags and have the friendsCount field satisfying the condition mentioned below. For all the collected tweets in a time interval, you need to find the top 50% most common words which are not stop words (http://www.ranks.nl/stopwords). For every time interval, you should store both the tweets and the top common words in separate files either in your local filesystem or HDFS. Your topology should be runnable both in local mode and cluster mode.
Your topology should have at least three spouts:
Notes:
You should tar all the following files/folders and put it in an archive named group-x.tar.gz -
You should submit the archive by placing it in your assignment2 hand-in directory for the course: ~cs838-1/F16/assignment2/group-x.
Apart from submitting the above deliverables, you need to setup your cluster so that it can be used for grading the applications developed. More specifically, you should do the following -