Motivation for Dataflow Analysis
A compiler can perform some optimizations based only on local information. For example, consider the following code:
x = a + b; x = 5 * 2;It is easy for an optimizer to recognize that:
Some optimizations, however, require more "global" information. For example, consider the following code:
a = 1; b = 2; c = 3; if (...) x = a + 5; else x = b + 4; c = x + 1;In this example, the initial assignment to c (at line 3) is useless, and the expression x + 1 can be simplified to 7, but it is less obvious how a compiler can discover these facts since they cannot be discovered by looking only at one or two consecutive statements. A more global analysis is needed so that the compiler knows at each point in the program:
1. k = 2;
2. if (...) {
3. a = k + 2;
4. x = 5;
5. } else {
6. a = k * 2;
7. x = 8;
8. }
9. k = a;
10. while (...) {
11. b = 2;
12. x = a + k;
13. y = a * b;
14. k++;
15. }
16. print(a+x);
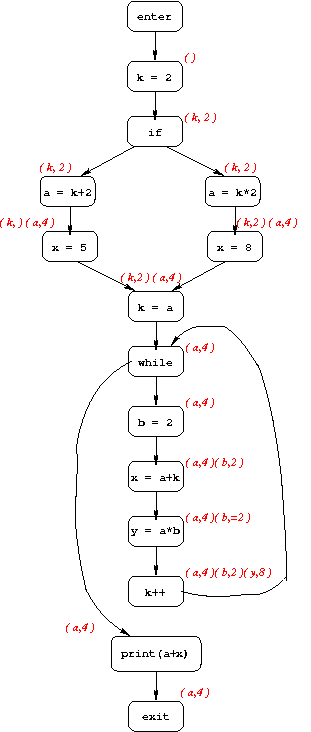
Constant Propagation
The goal of constant propagation is to determine where in the program variables are guaranteed to have constant values. More specifically, the information computed for each CFG node n is a set of pairs, each of the form (variable, value). If we have the pair (x, v) at node n, that means that x is guaranteed to have value v whenever n is reached during program execution.
Below is the CFG for the example program, annotated with constant-propagation information.
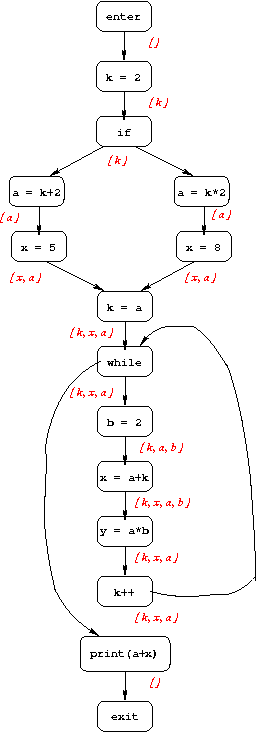
Live-Variable Analysis
The goal of live-variable analysis is to determine which variables are "live" at each point in the program; a variable is live if its current value might be used before being overwritten. The information computed for each CFG node is the set of variables that are live immediately after that node. Below is the CFG for the example program, annotated with live variable information.
Draw the CFG for the following program, and annotate it with the constant-propagation and live-variable information that holds before each node.
N = 10;
k = 1;
prod = 1;
MAX = 9999;
while (k <= N) {
read(num);
if (MAX/num < prod) {
print("cannot compute prod");
break;
}
prod = prod * num;
k++;
}
print(prod);
Before thinking about how to define a dataflow problem, note that there are two kinds of problems:
Another way that many common dataflow problems can be categorized is as may problems or must problems. The solution to a "may" problem provides information about what may be true at each program point (e.g., for live-variables analysis, a variable is considered live after node n if its value may be used before being overwritten, while for constant propagation, the pair (x, v) holds before node n if x must have the value v at that point).
Now let's think about how to define a dataflow problem so that it's clear what the (best) solution should be. When we do dataflow analysis "by hand", we look at the CFG and think about:
This intuition leads to the following definition. An instance of a dataflow problem includes:
For constant propagation, an individual dataflow fact is a set of pairs of the form (var, val), so the domain of dataflow facts is the set of all such sets of pairs (the power set). For live-variable analysis, it is the power set of the set of variables in the program.
For both constant propagation and live-variable analysis, the "init" fact is the empty set (no variable starts with a constant value, and no variables are live at the end of the program).
For constant propagation, the combining operation ⌈⌉ is set intersection. This is because if a node n has two predecessors, p1 and p2, then variable x has value v before node n iff it has value v after both p1 and p2. For live-variable analysis, ⌈⌉ is set union: if a node n has two successors, s1 and s2, then the value of x after n may be used before being overwritten iff that holds either before s1 or before s2. In general, for "may" dataflow problems, ⌈⌉ will be some union-like operator, while it will be an intersection-like operator for "must" problems.
For constant propagation, the dataflow function associated with a CFG node that does not assign to any variable (e.g., a predicate) is the identity function. For a node n that assigns to a variable x, there are two possibilities:
For live-variable analysis, the dataflow function for each node n has the form: fn(S) = (S - KILLn) union GENn, where KILLn is the set of variables defined at node n, and GENn is the set of variables used at node n. In other words, for a node that does not assign to any variable, the variables that are live before n are those that are live after n plus those that are used at n; for a node that assigns to variable x, the variables that are live before n are those that are live after n except x, plus those that are used at n (including x if it is used at n as well as being defined there).
An equivalent way of formulating the dataflow functions for live-variable analysis is: fn(S) = (S intersect NOT-KILLn) union GENn, where NOT-KILLn is the set of variables not defined at node n. The advantage of this formulation is that it permits the dataflow facts to be represented using bit vectors, and the dataflow functions to be implemented using simple bit-vector operations (and or).
It turns out that a number of interesting dataflow problems have dataflow functions of this same form, where GENn and KILLn are sets whose definition depends only on n, and the combining operator ⌈⌉ is either union or intersection. These problems are called GEN/KILL problems, or bit-vector problems.
Consider using dataflow analysis to determine which variables might be used before being initialized; i.e., to determine, for each point in the program, for which variables there is a path to that point on which the variable was never defined. Define the "may-be-uninitialized" dataflow problem by specifying:
If you did not define the may-be-uninitialized problem as a GEN/KILL problem, go back and do that now (i.e., say what the GEN and KILL sets should be for each kind of CFG node, and whether ⌈⌉ should be union or intersection).
Hint: There are a couple of different versions of the may-be-uninitialized problem. The GEN/KILL version can be understood as really tracking the property ``might never have been assigned to.'' Thus, an assignment ``y = x;'' takes y out of the might-never-have-been-assigned-to set (i.e., the KILL set for ``y = x;'' is {y}). However, once y has been assigned to along a given path, no statement can cause y to again have ``might-never-have-been-assigned-to'' status. What does the foregoing observation say about the GEN set for ``y = x;''?
If your original solution was not a GEN/KILL problem, you may have solved a different version of the may-be-unitialized problem, which can be understood as tracking the property ``may contain junk,'' where the uninitialized variables are the sources of junk. Thus, for ``y = x;'', if x may-contain junk before, then y may-contain-junk after. Moreover, if ``y = x;'' is followed by ``z = y;'', then z may-contain-junk after the second statement. However, this version of the may-be-uninitialized problem is not a GEN/KILL problem, and the dataflow functions have to be specified with more complicated functions then the dataflow functions for the GEN/KILL version.
Note that the second version identifies all places in the program to which ``junk'' may propagate, but the first version identifies the first instances of uninitialized variables (which may be more useful to a programmer trying to figure out what to correct in the program). That is, in the fragment ``y = x; z = y;'' the GEN/KILL analysis will say that x is may-be-uninitialized in the first statement, but will not say that y is may-be-uninitialized in the second statement. However, in any execution of the program, the second statement is just propagating the uninitialized value of x to variable z.
A solution to an instance of a dataflow problem is a dataflow fact for each node of the given CFG. But what does it mean for a solution to be correct, and if there is more than one correct solution, how can we judge whether one is better than another?
Ideally, we would like the information at a node to reflect what might
happen on all possible paths to that node. This ideal solution is
called the meet over all paths (MOP) solution, and is
discussed below. Unfortunately, it is not always possible to compute
the MOP solution; we must sometimes settle for a solution that
provides less precise information.
The MOP solution (for a forward problem) for each CFG node n is
defined as follows:
For instance, in our running example program there are two paths from
the start of the program to line 9 (the assignment k = a):
Combining the information from both paths, we see that the MOP
solution for node 9 is: k=2 and a=4.
It is worth noting that even the MOP solution can be overly
conservative (i.e., may include too much information for a "may"
problem, and too little information for a "must" problem), because not
all paths in the CFG are executable. For example, a program may
include a predicate that always evaluates to false (e.g., a
programmer may include a test as a debugging device -- if the program
is correct, then the test will always fail, but if the program
contains an error then the test might succeed, reporting that error).
Another way that non-executable paths can arise is when two predicates
on the path are not independent (e.g., whenever the first evaluates to
true then so does the second). These situations are
illustrated below.
Unfortunately, since most programs include loops, they also have
infinitely many paths, and thus it is not possible to compute the MOP
solution to a dataflow problem by computing information for every path
and combining that information. Fortunately, there are other ways to
solve dataflow problems (given certain reasonable assumptions about
the dataflow functions associated with the CFG nodes). As we shall
see, if those functions are distributive, then the solution
that we compute is identical to the MOP solution. If the functions
are monotonic, then the solution may not be identical to the
MOP solution, but is a conservative approximation.
The alternative to computing the MOP solution directly, is to solve a
system of equations that essentially specify that local information
must be consistent with the dataflow functions. In particular, we
associate two dataflow facts with each node n:
One question is whether, in general, our system of equations will have
a unique solution. The answer is that, in the presence of loops,
there may be multiple solutions. For example, consider the simple
program whose CFG is given below:
The equations for constant propagation are as follows (where
⌈⌉ is the intersection combining operator):
The solution we want is solution 4, which includes the most constant
information. In general, for a "must" problem the desired solution
will be the one with the largest sets, while for a "may" problem the desired
solution will be the one with the smallest sets.
Using the simple CFG given above, write the equations for
live-variable analysis, as well as the greatest and least solutions.
Which is the desired solution, and why?
Many different algorithms have been designed for solving a dataflow
problem's system of equations. Most can be classified as either
iterative algorithms or elimination algorithms.
These two classes of algorithms are discussed in the next two
sections.
Most of the iterative algorithms are variations on the following
algorithm (this version is for forward problems).
It uses a new value T (called "top"). T has the property
that, for all dataflow facts d, T ⌈⌉ d = d.
Also, for all dataflow functions, fn(T) = T.
(When we consider the lattice model for dataflow analysis we will see
that this initial value is the top element of the lattice.)
Run this iterative algorithm on the simple CFG given above (the one with
a loop) to solve the constant propagation problem.
Run the algorithm again on the example CFG from the
examples section of the notes.
This algorithm works regardless of the order in which nodes are
removed from the worklist. However, that order can affect the
efficiency of the algorithm. A number of variations have been
developed that involve different ways of choosing that order.
When we consider the lattice model, we will revisit the question of
complexity.
The "Meet Over All Paths" Solution

Solving a Dataflow Problem by Solving a Set of Equations
These n.befores and n.afters are the variables of our equations,
which are defined as follows (two equations for each node n):
In addition, we have one equation for the enter node:
where p1,
p2, etc are n's predecessors in the CFG (and ⌈⌉ is the
combining operator for this dataflow problem).
These equations make intuitive sense: the dataflow
information that holds before node n executes is the combination of
the information that holds after each of n's predecessors executes,
and the information that holds after n executes is the result of
applying n's dataflow function to the information that holds before n
executes.
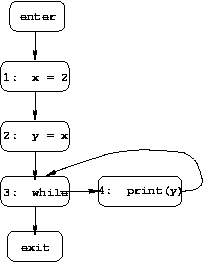
enter.after = empty set
Because of the cycle in the example CFG, the equations for
3.before, 3.after, 4.before, and
4.after are mutually recursive, which leads to the
four solutions shown below (differing on those four values).
1.before = enter.after
1.after = 1.before - (x, *) union (x, 2)
2.before = 1.after
2.after = if (x, c) is in 2.before then 2.before - (y, *) union (y, c), else 2.before - (y, *)
3.before = ⌈⌉(2.after, 4.after )
3.after = 3.before
4.before = 3.after
4.after = 4.before
Iterative Algorithms
Set enter.after = init. Set all other n.after to T.
Initialize a worklist to contain all CFG nodes except enter
and exit.
While the worklist is not empty:
Remove a node n from the worklist.
Compute n.before by combining all p.after such that p
is a predecessor of n in the CFG.
Compute
tmp = fn ( n.before )
If (tmp != n.after) then
Set n.after = tmp
Put all of n's successors on the worklist