![]()
![]()
一個數位圖書館及博物館的設計與建構,跟他所收藏的物品及書籍有非常
密切的關係,因為館藏物決定了這個圖書及博物館的風格與特色。但不論在哪
種類型的數位圖書及博物館中,都會有影像的資料,但每種類型的數位圖書及
博物館對於影像處理的需求,因著圖書及博物館的特色而各異。首先我們就看
看,在一般的數位圖書及博物館中,有哪些影像的資料。
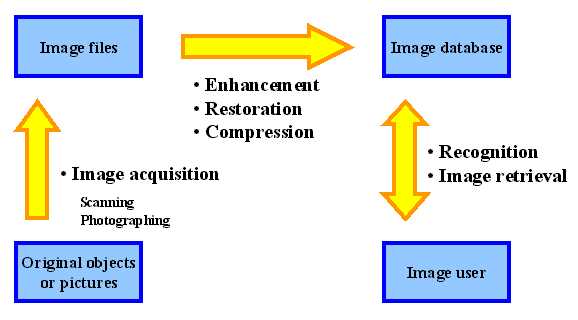
◎What image data does a digital library have?在一個數位圖書館中,有哪些影像的資料呢?大致而言有以下幾種資料:
一般的數位圖書及博物館,主要以前三項為主。樣台大的數位圖書及博物館,
就是以古文書,些許的圖片及照片為主,再加上一些地圖的資料。但也有一些
數位圖書館,是專門針對某些領域的影像處理而設置的,如:
Alexandria Digital Library
at UCSB Santa Barbara,就是以一些地理的資
料為主,故有許多的地圖、飛機的高空照片﹍等,故其在影像處理的需求上,
就較一般的數位圖書及博物館有一些差異,正因為影像的資料量大,故非常需
要影像搜尋及擷取的功能。另外像是: Informedia Digital Video Library
at Carnegie Mellon University,是一
個以影片為主的數位圖書館,他們對於影像處理的需求,有是有其獨到的地方
。在這篇報告中,將會對 Alexandria Digital Library 的影像搜尋,及
Informedia Digital Video
Library 的影像檢索作詳細的說明。以下,就先
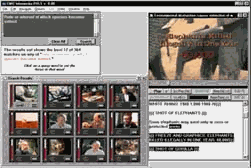
來認識一下這幾個數位圖書館的概況。 ◎Informedia Digital Video Library
|
|
 |
By 陳必衷 Bee-Chung Chen, CSIE NTU Taiwan [To Homepage] [Back]