Pill Image Recognition
Eddie Chavez & Michael Yanagisawa
PROBLEM SUMMARY + MOTIVATION
One challenge that patients and pharmacists face today is that it can be hard to identify a given pill. While most of a patient’s pills should be in labeled bottles, sometimes pills get separated or lost, and the patient no longer knows what a given pill is. Taking the wrong pill in these scenarios can be costly, even fatal, so there is a clinical need to identify the pill correctly.
As a side note – there are services today that allow you to input a pill’s color, shape, and imprint (the words printed onto the pill), and output the medication (e.g. Drug.com’s Pill Identifier [1]). However, this extra bit of effort may dissuade patients from correctly identifying their medications.
Our project goal is to take in a pill image and match it to a medication. More precisely, our end product will aim to take a set of pill images and output a national drug code (NDC), the unique identifier of a medication in the US.
This new application has a few potential real-life use cases:
We do want to point out that this problem is important, but also not new. In 2016, the National Library of Medicine held a pill image recognition [2]. The results from the winners of this challenge [3] will help motivate our team to both (a) try to meet or exceed the results from other groups, and (b) identify pill images that were particularly troublesome to identify as a potential area to pursue further.
APPROACH
As part of the class, we planned to use computer vision and machine learning to tackle this project.
Initial approach
Intuitively, the way that we humans identify pills is by breaking down the pill into its core features:
In fact, Drug.com’s PIll Identifier [1] does just that. All that a user has to input is the color, imprint, and shape, and the program returns what the medication is.
Pill Identifier from Drugs.com – one example of a simple UI that allows you to look up an NDC manually
Our initial approach was to use this “intuitive” approach: use computer vision and machine learning to break down a pill image into its key features (color, imprint, shape). Our plan was to use convolutional neural networks to classify these images, which can handle multiclass image classification tasks such as this one. We could then pass this color/imprint/shape combination into another API to recover the NDC.
Example of what we hoped our initial approach to output
Pivot to Convolutional Networks
As we dug more into the literature, we found work done by Wong et al. [6] that used convolutional networks to identify pills. As part of their background section, they shared prior research that attempted to extract the color (using hue, saturation, value color profiles), shape (using invariant shape features), and imprint (using methods like modified stroke width transform and SIFT). The authors state:
We argue that manually designed features work well in a controlled environment but would yield poor performance in unconstrained settings such as with images captured by mobile devices. More precisely, manually designed features require one to have strong domain knowledge when crafting the features.
In other words, the “intuitive approach” – breaking a pill image down into imprint, color, and shape – was not promising. Instead, the authors then showed that a convolutional network approach was effective. Using the top 400 medications, they had a 95% top-1 accuracy rate, higher than features with random forest (89%).
Thus, our initial plan of using computer vision to “see” the features of the pills seemed like the wrong path for us to go down. Midway through the project, we shifted our approach to instead use convolutional networks, using the rich library of pill images provided by the National Library of Medicine [5].
Example of image-NDC combination in the training set
Discussion of the Convolutional Network Approach
While the convolutional network approach has better performance, it requires significantly more effort to prepare the training data. Because we are classifying an input image into a single NDC, the output model can only classify NDCs that it has seen in the training database, meaning that training data needs to contain every NDC in order for the model to be complete.
This has clear downsides when compared to our initial approach. Challenge number one is collecting labeled image-NDC pairs for every NDC. Challenge number two is model maintenance: if new NDCs are introduced or NDCs are removed, then the model may need to be updated as well.
IMPLEMENTATION
Data Sources
The National Library of Medicine maintains a database of NDC properties (e.g. imprint, color, shape) [4]. We should be able to extract this data to map imprint, color, and shape to a single NDC.
The National Library of Medicine also maintains a database of reference pill images [5]. This repository of 4,000 reference pill images and 133,000 consumer-grade pill images will be a key source of training and testing data. The training images were divided into 8 training instances and 6 test instances per pill.
Example training pill images
We evaluated consumer-grade photos, presumably shot by a phone camera. Some examples are below:
Implementation Challenges
As with almost all machine learning problems, one of the largest implementation challenges involved collecting and cleaning the data before we fed it into the convolutional network.
From our huge database of images [5], one of the biggest challenges was extracting the images and labeling them with the correct NDC. The crosswalk of drug identifier (NDC) to the 133K+ images are accessible in [8], and the images can be retrieved from https://data.lhncbc.nlm.nih.gov/public/Pills/<pillURL>. These images tend to be large, and so downloading these files has been a tedious task.
In order to be able to feed the neural network training data, we were able to write a Python script that automatically downloads and sorts the labeled images from the NLM website. This approach has the potential to provide us with many more than than the 400 drugs captured by Wong et al. [6], hopefully would make our model significantly stronger than any prior work.
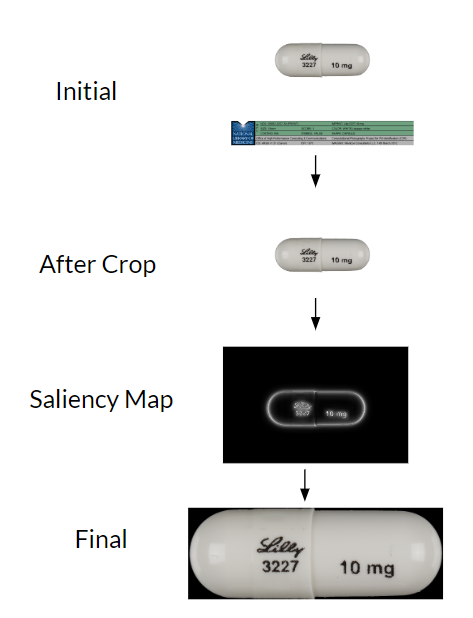
One other hurdle we faced with the pill image dataset is that the images included a lot of extra information in addition to just the pill. To solve this, we took a similar approach to Wong et al. [6] – we used saliency detection to identify the pill in the image. By taking this extra step, we hoped to reduce the impact that the background had on the trained model.
Details of some of the pre-processing steps that were taken
RESULTS
Model Refinement
For our first iteration/prototype of our pill identifier we used a training set that consisted of three different pills to start out small. For each of the pills we had 7 training images, and 3 evaluation images. For the training instances we used higher-fidelity reference photos, and for the evaluation (testing) instances we used photos that were more representative of what might appear in an application setting (photos taken from a mobile camera).
Initially, we decided to select a more lightweight model named SSD MobileNet v2 320x320 from TensorFlow’s Object Detection Model Zoo [7] that compresses images to 320x320, thereby achieving a faster, more lightweight model, but also lower mAP (Mean Average Precision) than larger models. Since our ideal platform for this application would be a mobile device we figured this trade-off might be necessary. Using 2000 training steps, we were able to achieve a precision of 68.7%, and a recall of 70%. Considering the small training set size, the results were promising, but we had a lot of room for optimization. In hindsight, we should have likely done a more thorough prototype with at least 10 pills, as a ternary classification is significantly easier than a 100-400x classification task which we were ultimately aiming for with our deep learning model.
One thing we learned from the first iteration of the model was that due to the fine-grained nature of pill identification, (particularly with the imprint feature) we couldn’t afford much image compression. In our second iteration of the neural network, we used Tensorflow’s SSD ResNet101 FPN 1024x1024 (RetinaNet101), which has a greater mAP (39.5 vs. 23.4 for the model used in training). This model compresses the image less than the SSD MobileNet v2 320x320 model, which should achieve our goal of retaining more of the pill details in the trained model. We decided to use 100 NDCs for our model, and below are summary statistics of the features of the pills.
With this model, we were able to get an average precision of 91.40%, and average recall of 92.64%.
As a baseline, we reference precision identified by Wong et al. [6]. Manually-crafted features with k-nearest neighbors had a precision of 70.65%, manually crafted features with Random Forest has a precision of 89.00%, and CNNs by Wong et al. [6] were able to accomplish a precision of ~95.35%.
The code that we used can be found on github: https://github.com/educhav/pills-cs-639
DISCUSSION
What we learned
One difficulty we had during our project was deciding which approach we were going to take to train the machine learning model. Our initial approach was intuitive to a human – break down the image into its components, and then piece those components together to get the final medication. The approach we ended up taking was a more classical machine learning approach – give the model a set of pill images and NDCs, and have the model handle the classification.
One takeaway from this part of the project was that machine learning implementations demand machine learning approaches. In retrospect, our initial approach was all-too-human; we should have taken a more classical machine learning approach from the start.
Two takeaways from the deep learning approach are to improve our data collection practices and to reconsider our target use for this system. In Wong’s approach they collected data with a cell-phone camera at different perspectives of each pill. We could not emulate these steps as they did not publish their data set, nor could we get a hold of a pharmacy contact. In terms of reconsidering the target use of our system, we should select evaluation instances that closely resemble our standards in terms of image quality for our application. Raising the standards for image quality through the use of another computer vision system could greatly improve our model accuracy.
FUTURE DIRECTION
Because this project was only part of the one-semester Computer Vision course, there are a lot of interesting directions that this project could continue to grow in the future. Below, we provide some areas that we would’ve loved to tackle if we had more time!
Preliminary computer vision system as a potential solution
As mentioned above in our takeaways, I believe our model could have performed better had some of the evaluation instances not been as distant or had reasonable lighting. If we were to make an application out of this model, we could add a preliminary computer vision system to ensure only quality photos are being sent to the model, therefore leading to better inference. There are many examples of these kinds of preliminary computer vision systems being used in mobile apps, such as Instagram filters, check deposits, and document scanners. For example, in Instagram, it will wait for you to get within shot of the camera with good lighting before applying the filter. In the same way, we could wait for our users to capture a photo of the pill with good lighting and focus.
Train the model on more training instances for each NDC
One of the steps that we could not emulate from Wong et. Al [6] was their data collection practices. They captured images of pills from different angles, and further used data augmentation to create new instances from existing images. Unfortunately they did not publicize this data set, so we were stuck with rather 2-dimensional lab-grade photos from the NLM. We believe that emulating the steps from Wong et. Al [6] would have led to a significantly better performing model as our preprocessing methods and CNN architecture were sound.
Train the model on more pill NDCs
If we had more time, one of our first steps would be to collect more pill image-NDC combinations to expose the model to a larger swath of medications. Given time constraints, we were only able to train 100 NDCs. Increasing this training data set would allow the model to “know” a larger variety of medications.
Approach 100% clinical accuracy
If this model were ever to be used in a clinical setting, it would need to approach 100% clinical accuracy. In our opinion, this is the biggest barrier to this type of machine learning approach from being more widely-adopted. In order to do this, we would need to find a threshold for the model’s confidence in order to ensure that images we cannot classify well are flagged for human review.
We would also aim to challenge the model to not classify a pill image that is similar to an NDC it has seen, but not quite exact. For example, if the training data has a pill that is blue with “ABC” on it, how will the model handle a blue pill with “DEF” on it, if it was never trained on this second pill? Similarly, how would the model react if it only saw the backside of the pill (i.e. no words on it)? In both cases, we would want the model to return “no match found.”
Test model robustness with real-life scenarios
Our test data consists largely of images with homogenous backgrounds – clear pictures of the pill on a white or neutral background. In real life, the images will likely be captured on a mobile phone; the images will be blurry, and on non-neutral backgrounds. There may also be more than one pill in a given image. Overcoming these obstacles would help make the model ready for patient use.
Capture pill image data from real pharmacies
Some pharmacies capture pictures of the pill image as it is being dispensed as part of regular pharmacy workflow. We have also reached out to a pharmacy contact to see if this data is readily available. If so, this additional “real-life” pill data could help make our model even stronger.
Consider how the model should handle NDC updates
On occasion, an NDC is retired (i.e. the manufacturer no longer produces the pill). The NDC is sometimes then re-activated, with a different pill image – different medication, pill color, shape, and imprint. We would have to consider how the model should/could react in these corner case scenarios.
REFERENCES
[1] Drug.com’s Pill Identifier – https://www.drugs.com/imprints.php
[2] National Library of Medicine’s Pill Image Recognition Challenge (archived by wayback) – https://wayback.archive-it.org/org-350/20181219213346/https://pir.nlm.nih.gov/challenge/index.html
[3] The National Library of Medicine Pill Image Recognition Challenge: An Initial Report – https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5973812/
[4] National Library of Medicine. Rx Norm API: getNDCProperties. – https://lhncbc.nlm.nih.gov/RxNav/APIs/api-RxNorm.getNDCProperties.html
[5] National Library of Medicine: Download Pill Image Data – https://www.nlm.nih.gov/databases/download/pill_image.html
[7] models/tf2_detection_zoo.md at master · tensorflow/models (github.com)
[8] https://data.lhncbc.nlm.nih.gov/public/Pills/ALLXML/directory_of_images.txt