GPGPU-Sim Manual, Version 1.0
Authors and Version
Authors: Wilson W. L. Fung, Ali Bakhoda and Tor M. Aamodt.
This is version 1.0 of the GPGPU-Sim Manual. It corresponds to GPGPU-Sim version 2.1.1 b.
Introduction
This document describes GPGPU-Sim, a cycle-accurate performance simulator for many-core accelerators (such as Graphics Processor Unit) architectures. It is intended to guide users through the steps to setup and run CUDA/OpenCL applications on GPGPU-Sim. It is also provides documentation on how to use and extend GPGPU-Sim, including:
- Explanations of various simulation configuration options
- Description of the performance statistics GPGPU-Sim reports
- Overview of the software architecture of GPGPU-Sim as a starting point for the user to extend GPGPU-Sim
This is by no means an exhaustive and comprehensive reference for GPGPU-Sim. If your questions are not clearly explained by this document, please sign up for the google groups page for Q&A (see gpgpu-sim.org).
See Building GPGPU-Sim and Running GPGPU-Sim below to get started.
Copyright and Citations
Please see the copyright notice in the file COPYRIGHT distributed with this release. This version of GPGPU-Sim is for non-commercial use only.
If you use this simulator in your research please cite:
Ali Bakhoda, George Yuan, Wilson W. L. Fung, Henry Wong, Tor M. Aamodt, Analyzing CUDA Workloads Using a Detailed GPU Simulator, in IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Boston, MA, April 19-21, 2009.
Contributions and History
GPGPU-Sim was created at the University of British Columbia by Tor M. Aamodt, Wilson W. L. Fung, Ali Bakhoda, George Yuan along with contributions by Ivan Sham, Henry Wong, Henry Tran, and others. The GPGPU-Sim visualization tool (AerialVison) distributed with GPGPU-Sim version 2.1.1b was developed primarily by Aaron Ariel along with contributions from Wilson Fung, Andrew Turner, and Tor Aamodt.
GPGPU-Sim models the features of a modern graphics processor that are relevant to non-graphics applications. The first version of GPGPU-Sim was used in a MICRO'07 paper and follow-on ACM TACO paper on dynamic warp formation. That version of GPGPU-Sim used the SimpleScalar PISA instruction set for functional simulation (only), and various auxiliary configuration files specifying kernel locations to provide a programming model close to CUDA. Creating benchmarks for the original GPGPU-Sim simulator was a very time consuming process. This motivated the development of an interface for directly running CUDA applications to leverage the growing number of applications being developed to use CUDA. The 2.1.1b release of GPGPU-Sim also support OpenCL.
The interconnection network is simulated using the booksim simulator developed by Bill Dally's research group at Stanford.
The previous versions of GPGPU-Sim (as of version 2.1.0b) used a few portions of SimpleScalar functional simulation code: support for memory spaces and command line option processing. This code has been entirely replaced in the 2.1.1b release of GPGPU-Sim.
To produce output that is compatible with the output from running the same CUDA program on the GPU, we have implemented several PTX instructions using the CUDA Math library (part of the CUDA toolkit). Code to inferface with the CUDA Math library is contained in cuda-math.h, which also includes several structures derived from vector_types.h (one of the CUDA header files).
System Requirement
The GPGPU-Sim simulator itself does not require a physical GPU. It does require the CUDA toolkit. Currently using OpenCL requires the NVIDIA OpenCL driver, which in turn appears to require a physical GPU.
Features and CUDA Version Support
CUDA version and features supported:
- GPGPU-Sim Version 2.1.1b
- CUDA version 2.3 (or older) or PTX version 1.4
- Added support for OpenCL (requires OpenCL driver from NVIDIA)
- Added performance visualizer tool
- Added manual documenting usage of the simulator (see doc directory)
- Added configuration file for Quadro FX5800 (see configs directory)
- Simultaneous release of benchmarks from ISPASS 2009 paper (separate download)
- Improved shared memory bank conflict modeling
- Improved default mapping of local memory accesses to global address space
- Added interconnect concentration modeling (to approximate effect of a TPC)
- Added support for GPU-to-GPU memory copies (same GPU), timing not modeled
- SimpleScalar code removed.
- PTX support for vector operands in mov instruction
- Bug fixes (see CHANGES)
- GPGPU-Sim Version 2.1.0b
- CUDA version 2.2 (or older) or PTX version 1.4
- Added support for parsing and functionally simulating up to CUDA 2.2 generated PTX
- Dynamically linking with precompiled CUDA/OpenCL program (require CUDA version 2.1 or newer)
- Added dynamic warp formation timing model (see MICRO'07, ACM TACO'09 papers)
- Updated gpgpusim.config and mesh in benchmark subdirectories to be similar to ISPASS 2009 paper baseline configurations
- Added OpenGL interoperability support
- Added support for parsing embedded PTX files without requiring recompilation (suggested by Gregory Diamos)
- Improved support for texture filtering (linear mode for 2D, closer agreement to hardware for 2D point sampling where sample points are close to texel boundaries)
- Benchmark examples updated to version from CUDA 2.2 SDK (NOTE: these will not compile with earlier CUDA installations. However, GPGPU-Sim should still work with applications written for older verions of CUDA.)
- Bug fixes (see CHANGES)
- GPGPU-Sim Version 2.0
- CUDA version 1.1 (or older) or PTX version 1.1
- Pending support for features in CUDA version 2.2 and 2.3:
- membar (block until all outstanding memory operations have finished)
- pmevent (trigger performance counter event)
- fma (fused multiply-add, with infinite intermediate precision)
- CUDARTAPI calls not supported:
extern __host__ cudaError_t CUDARTAPI cudaHostAlloc(void **pHost, size_t bytes, unsigned int flags); extern __host__ cudaError_t CUDARTAPI cudaHostGetDevicePointer(void **pDevice, void *pHost, unsigned int flags); extern __host__ cudaError_t CUDARTAPI cudaSetValidDevices(int *device_arr, int len); extern __host__ cudaError_t CUDARTAPI cudaSetDeviceFlags( int flags ); extern __host__ cudaError_t CUDARTAPI cudaFuncGetAttributes(struct cudaFuncAttributes *attr, const char *func); extern __host__ cudaError_t CUDARTAPI cudaEventCreateWithFlags(cudaEvent_t *event, int flags); extern __host__ cudaError_t CUDARTAPI cudaDriverGetVersion(int *driverVersion); extern __host__ cudaError_t CUDARTAPI cudaRuntimeGetVersion(int *runtimeVersion);
AerialVision Performance Visualizer
As of GPGPU-Sim version 2.1.1b, a python based performance visualizer is distributed with GPGPU-Sim. This tool makes it much easier to identify performance bottlenecks at the hardware and software level. The visualizer is in the "visualizer" subdirectory. Please consult the documentation for the visualizer in the doc directory for more details.
Memory Copy
We functionally support Host-to-Device, Device-to-Host, and Device-to-Device memory copy via cudaMemcpy(), but we do not simulate the latency of these operations.
Multi-GPU Simulation
Currently, we do not support simulating more than one GPU at a time.
Building GPGPU-Sim
GPGPU-Sim was developed on Linux SuSe (this release was tested with SuSe version 11.1) and has been used on several other Linux platforms (both 32-bit and 64-bit systems). In principle, GPGPU-Sim should work with any linux distro as long as the following software dependencies are satisfied.
Software Dependencies
GPGPU-Sim requires the following software modules:
- An installation of CUDA which you need to download from NVIDIA's website.
- To use OpenCL: An installation of NVIDIA OpenCL drivers from NVIDIA's OpenCL Page.
- GNU Compiler Collection (i.e. gcc) 4.0 or newer
- gcc 4.3 recommended for CUDA 2.x
- gcc 4.1 recommended for CUDA 1.1
- bison (version 2.3 recommended)
- flex (version 2.5.33 recommended)
- zlib
- The benchmarks from the ISPASS 2009 paper (distributed separately) have additional dependencies.
Supported OS
GPGPU-Sim Version 2.1.0b has been tested (by our active user community) on the following OS:
- SUSE Linux 10.2 (32-bit and 64-bit)
- Fedora Core 5
- Ubuntu 8.04 LTS
- Ubuntu 8.10
- 'make bench' can generate the this error: "Multiple targets found in ../../commom/common.mk"
- Ubuntu 9.04
- GPGPU-Sim 2.1.1b has received some limited testing on this platform.
OS tried by our users and currently not working:
- MAC OSX:
- One may want to play with the PATH and DYLD_LIBRARY_PATH environment variables to get the CUDA toolkit working.
- Cygwin:
- CUDA on Windows uses Microsoft C Compiler as their backend compiler, whereas GPGPU-Sim on Cygwin will be using gcc. To get GPGPU-Sim working on Cygwin, one may need to get CUDA to use gcc instead.
Compiling GPGPU-Sim
- Step 1: Ensure you have gcc, make, zlib, bison and flex installed on your system. For CUDA 2.x we used gcc version 4.3.2, for CUDA 1.1 we used gcc version 4.1.3. We used bison version 2.3, and flex version 2.5.33.
- Step 2: Download and install the CUDA Toolkit and CUDA SDK code samples from NVIDIA's website: http://www.nvidia.com/cuda. If you want to run OpenCL on the simulator, download and install NVIDIA's OpenCL driver from http://developer.nvidia.com/object/opencl-download.html. Update your PATH and LD_LIBRARY_PATH as indicated by the install scripts.
- Step 3: Build libcutil.a. The install script for the CUDA SDK does not do this step automatically. If you installed the CUDA Toolkit in a nonstandard location you will first need to set CUDA_INSTALL_PATH to the location you installed the CUDA toolkit (including the trailing "/cuda"). Then, change to the C/common subdirectory of your CUDA SDK installation (or common subdirectory on older CUDA SDK versions) and type "make".
- Step 4: Set environment variables (e.g., your .bashrc file if you use bash as your shell).
- (a) Set GPGPUSIM_ROOT to point to the directory containing this README file.
- (b) Set CUDAHOME to point to your CUDA installation directory
- (c) Set NVIDIA_CUDA_SDK_LOCATION to point to the location of the CUDA SDK
- (d) Add $CUDAHOME/bin and $GPGPUSIM_ROOT/bin to your PATH
- (e) Add $GPGPUSIM_ROOT/lib/ to your LD_LIBRARY_PATH and remove $CUDAHOME/lib or $CUDAHOME/lib64 from LD_LIBRARY_PATH
- (f) If using OpenCL, set NVOPENCL_LIBDIR to the installation directory of libOpenCL.so distributed with the NVIDIA OpenCL driver. On SuSe 11.1 64-bit NVIDIA's libOpenCL.so is installed in /usr/lib64/.
- Step 5: Type "make" in this directory. This will build the simulator with optimizations enabled so the simulator runs faster. If you want to run the simulator in gdb to debug it, then build it using "make DEBUG=1" instead.
- Run a CUDA built with a recent version of CUDA (or an OpenCL application) and the device code should now run on the simulator instead of your graphics card. To be able to run the application on your graphics card again, remove $GPGPUSIM_ROOT/lib from your LD_LIBRARY_PATH. See also Statically (Compile Time) Linking GPGPU-Sim.
- NOTES: Step 5 will build the libraries that contain GPGPU-Sim. These libraries can be linked to a CUDA application dynamically or at compile time, creating an executable that runs the CUDA application on GPGPU-Sim rather than a GPU.
- The following shared libraries are used with prebuilt CUDA/OpenCL applications generated with a recent version of CUDA (2.1 or newer). See Dynamically Linking with GPGPU-Sim for more details.
- lib/libcudart.so - For prebuilt CUDA applications
- lib/libOpenCL.so - For prebuild OpenCL applications
- The following files are created to be used when building an application with statically linked libraries. See Statically (Compile Time) Linking GPGPU-Sim for more details.
- src/libgpgpusim.a - Performance simulator module of GPGPU-Sim
- src/cuda-sim/libgpgpu_ptx_sim.a - Functional simulator module of GPGPU-Sim
- src/intersim/libintersim.a - Interconnection simulator module of GPGPU-Sim (derived from Book-Sim)
- lib/libcuda.a - CUDA API stub library that interface GPGPU-Sim with a CUDA application
- The following shared libraries are used with prebuilt CUDA/OpenCL applications generated with a recent version of CUDA (2.1 or newer). See Dynamically Linking with GPGPU-Sim for more details.
Porting a CUDA/OpenCL application to run on GPGPU-Sim
GPGPU-Sim compiles itself into a stub library that emulates the CUDA API. It can be statically linked to the CUDA application as libcuda.a, or it can be dynamically linked as libcudart.so. Similarly, GPGPU-Sim interfaces with OpenCL benchmarks via libOpenCL.so (and dynamic linking).
For both cases, you will need a GPGPU-Sim configuration file (gpgpusim.config) and a interconnection configuration file in the current directory for GPGPU-Sim to run.
Dynamically Linking with GPGPU-Sim
This approach works with prebuilt applications generated with CUDA 2.1 or newer. Note that some applications make references to external CUDA libraries and these may not provide embedded PTX source (in which case the application will not be able to run on GPGPU-Sim).
- Compile GPGPU-Sim following steps in Compiling GPGPU-Sim
- Add <GPGPU-Sim Top Level Directory>/lib to LD_LIBRARY_PATH:
export LD_LIBRARY_PATH=<GPGPU-Sim Top Level Directory>/lib:$LD_LIBRARY_PATH
- GPGPU-Sim Top Level Directory is the directory where you have GPGPU-Sim installed on your system
- Now execute your CUDA application, and GPGPU-Sim should be evoked in place of the Hardware GPU. You can double check by using ldd:
ldd <your CUDA application executable>
Statically (Compile Time) Linking GPGPU-Sim
The preferred approach to porting new applications is to preface LD_LIBRARY_PATH to GPGPUSIM_ROOT/lib GPGPU-Sim which avoids the need for recompilation of your CUDA application. See Dynamically Linking with GPGPU-Sim if you want to use this method (recommended).
Using commom/common.mk provided by GPGPU-Sim
For compatibility with earlier releases we still provide a makefile (common/common.mk) that works similarly to the common.mk in CUDA SDK. If your CUDA application is using the same compiling infrastructure as the benchmarks in CUDA SDK, here are the steps to get it running on GPGPU-Sim:
- Copy directory containing the benchmark into the 'benchmark' directory in GPGPU-Sim
- In the Makefile of the benchmark directory, change '../../common/common.mk' to '../common/common.mk'
- Type "make" as usual in your application directory
You can also use the commom/common.mk without copying your benchmark into the 'benchmark' directory as long as you set GPGPUSIM_ROOT to point to where GPGPU-Sim is located.
Modify your existing compilation flow
- Add the following compiling flag to the existing ones for nvcc for compiling CUDA files:
--keep --compiler-options -fno-strict-aliasing
- Use the following linker flag and use g++ for linking ($(GPGPUSIM_ROOT) is where GPGPU-Sim is installed):
-L$(GPGPUSIM_ROOT)/libcuda/ -lcuda \ -L$(LIBDIR) -lcutil \ -L$(GPGPUSIM_ROOT)/src/ -lgpgpusim \ -L$(GPGPUSIM_ROOT)/src/intersim -lintersim \ -L$(GPGPUSIM_ROOT)/src/cuda-sim/ -lgpgpu_ptx_sim \ -lm -lz -lGL
- Run gen_ptxinfo in the scripts directory (not required for GPGPU-Sim V2.1.0b with CUDA 2.1 or newer)
Porting OpenCL applications
To run an OpenCL application, you will need to do the following:
- Set NVOPENCL_LIBDIR to the installation directory of libOpenCL.so distributed with the NVIDIA OpenCL driver before building GPGPU-Sim. On SuSe 11.1 64-bit this is /usr/lib64/.
- Compile GPGPU-Sim following steps in Compiling GPGPU-Sim
- Add <GPGPU-Sim Top Level Directory>/libopencl to LD_LIBRARY_PATH
Common causes of compilation error
Missing 'cuda' at the end of CUDAHOME
CUDA toolkit installation appends 'cuda' to the install location. You may want to double check if CUDAHOME actually contains directories like 'bin' and 'include' instead of just 'cuda' (and the required directories are inside this 'cuda' directory). E.g. If you specify CUDA toolkit to be installed at '/home/usrname/cuda', CUDAHOME needs to be specified as '/home/usrname/cuda/cuda'.
Forgot to compile CUTIL (CUDA Utility Library)
If you see this error:
/usr/bin/ld: cannot find -lcutil
You may want to first check if NVIDIA_CUDA_SDK_LOCATION is set to the correct location. Notice that CUDA SDK 2.0 and onwards have moved the common libraries from $NVIDIA_CUDA_SDK_LOCATION/common/lib to $NVIDIA_CUDA_SDK_LOCATION/C/common/lib. So you may want to change the common.mk that comes with GPGPU-Sim to make sure it matches with your CUDA SDK version. If that path is properly set and you are still getting the error. Chances are you have not compile libcutil.a. You can do that by running make at $NVIDIA_CUDA_SDK_LOCATION/C/common.
Error with OpenCL application
If you are using OpenCL with GPGPU-Sim, it is important that you set the following environment variables:
- GPGPUSIM_ROOT - path to your GPGPU-Sim installation
- NVOPENCL_LIBDIR - path to libOpenCL.so provided by NVIDIA (usually just /usr/lib or /usr/lib64) <-- Do NOT set this to the libOpenCL.so built by GPGPU-Sim, otherwise you will see an recursion error.
Running GPGPU-Sim
If a CUDA application is sucessfully ported to GPGPU-Sim (See this for instructions), running the generated executable file will invoke GPGPU-Sim instead of the CUDA driver.
Or, if your application is generated with CUDA 2.1 or newer, follow these instructions to get it dynamically linked with GPGPU-Sim. Once LD_LIBRARY_PATH is properly configured, the unmodified executable file in your application will invoke GPGPU-Sim instead of the CUDA driver. A similar procedure applies to OpenCL applications.
By default, this version of GPGPU-Sim uses the PTX source embedded within the binary. To use the .ptx files in the current directory, type:
export PTX_SIM_USE_PTX_FILE=1
This will inform GPGPU-Sim to look inside the PTX source (.ptx) files in the current directory for the kernel code. This code can be extracted from the binary using the "-save_embedded_ptx" option. When using OpenCL, the PTX files must be named _n.ptx, where n is the order of calls to clBuildProgram in the OpenCL application. The simplest way to achieve this is to first run GPGPU-Sim with "-save_embedded_ptx" which will create these PTX files. For CUDA applications, the PTX source files should be generated automatically if you build with the static link option (i.e., using common/common.mk) during CUDA application compilation. Alternatively, they can be generated by running the following command for each CUDA source file:
nvcc --keep <.cu file>
If you create the PTX files directly using nvcc, you should run scripts/gen_ptxinfo on each PTX source file to generate an info file (.ptxinfo) that communicates hardware resource requirements of each kernel to GPGPU-Sim (e.g., number of registers used, etc...) which is important for correctly modeling the number of threads that can run concurrently.
When GPGPU-Sim invoked, it will automatically look for the configuration files (gpgpusim.config) used for specifying the microarchitecture configuration in the current directory. See Simulation Configurations for more detail.
Microarchitecture Model
The microarchitecture modeled by GPGPU-Sim is described in the paper presented in ISPASS-2009. Please refer to the paper while we prepare more detailed documentation.
Version 2.1.1b adds the following features to the microarchitecture model to better model NVIDIA GPUs:
- GPU Concentration - Share a single port into the interconnection among multiple shader cores. This models some aspects of the TPC.
- Shared memory bank conflict checking at 16 threads granularity (See -gpgpu_shmem_pipe_speedup).
Configuration Options
Configuration options are passed into GPGPU-Sim with gpgpusim.config and an interconnection configuration file (specified with option -inter_config_file inside gpgpusim.config). In the 2.1.1b release, we provide configuration files for modeling the following GPUs:
- Quadro FX 5800
Here is a list of the configuration options, vaguely classified into different categories:
List of Options
| Simulation Run Configuration | |
|---|---|
| -gpgpu_max_cycle <# cycles> | Terminate GPU simulation early after a maximum number of cycle is reached |
| -gpgpu_max_insn <# insns> | Terminate GPU simulation early after a maximum number of instructions |
| -gpgpu_ptx_sim_mode <0=performance (default), 1=functional> | Select between performance or functional simulation (note that functional simulation may incorrectly simulate some PTX code that requires each element of a warp to execute in lock-step) |
| -gpgpu_deadlock_detect <0=off, 1=on (default)> | Stop the simulation at deadlock |
| Statistics Collection Options | |
| -gpgpu_ptx_instruction_classification <0=off, 1=on (default)> | Enable instruction classification |
| -gpgpu_runtime_stat <frequency>:<flag> | Display runtime statistics |
| -gpgpu_memlatency_stat <0=off, 1=on> | Collect memory latency statistics |
| -visualizer_enabled <0=off, 1=on (default)> | Turn on visualizer output (use AerialVision visualizer tool to plot data saved in log) |
| -visualizer_outputfile <filename> | Specfies the output log file for visualizer. Set to NULL for automatically generated filename (Done by default). |
| -visualizer_zlevel <compression level> | Compression level of the visualizer output log (0=no compression, 9=max compression) |
| -enable_ptx_file_line_stats <0=off, 1=on (default)> | Turn on PTX source line statistic profliing |
| -ptx_line_stats_filename <output file name> | Output file for PTX source line statistics. |
| High-Level Architecture Configuration (See ISPASS paper for more details on what is being modeled) | |
| -gpgpu_n_shader <# shader cores> | Number of shader cores in this configuration. Read #Topology Configuration before modifying this option. |
| -gpgpu_n_mem <# memory controller> | Number of memory controllers (DRAM channels) in this configuration. Read #Topology Configuration before modifying this option. |
| -gpgpu_clock_domains <Core Clock>:<Interconnect Clock>:<L2 Clock>:<DRAM Clock> | Clock domain frequencies in MhZ (See #Clock Domain Configuration) |
| Shader Core Pipeline Configuration | |
| -gpgpu_shader_core_pipeline <# thread/shader core>:<warp size>:<pipeline simd width> | Shader core pipeline config |
| -gpgpu_shader_registers <# registers/shader core, default=8192> | Number of registers per shader core. Limits number of concurrent CTAs. |
| -gpgpu_shader_cta <# CTA/shader core, default=8> | Maximum number of concurrent CTAs in shader |
| -gpgpu_simd_model <0=no reconvergence, 1=immediate post-dominator, 2=MIMD, 3=dynamic warp formation> | SIMD Branch divergence handling policy |
| -gpgpu_pre_mem_stages <# stages between execution and memory stage> | Additional stages before memory stage to model memory access latency |
| Memory Sub-System Configuration | |
| -gpgpu_perfect_mem <0=off (default), 1=on> | Enable perfect memory mode (zero memory latency) |
| -gpgpu_no_dl1 <0=off (default), 1=on> | No L1 Data Cache |
| -gpgpu_tex_cache:l1 <# Sets>:<Bytes/Block>:<# Ways>:<Evict Policy> | Texture cache (Read-Only) config. Evict policy: L = LRU, F = FIFO, R = Random |
| -gpgpu_const_cache:l1 <# Sets>:<Bytes/Block>:<# Ways>:<Evict Policy> | Constant cache (Read-Only) config. Evict policy: L = LRU, F = FIFO, R = Random |
| -gpgpu_cache:dl1 <# Sets>:<Bytes/Block>:<# Ways>:<Evict Policy> | L1 data cache (for global and local memory) config. Evict policy: L = LRU, F = FIFO, R = Random |
| -gpgpu_shmem_size <shared memory size, default=16kB> | Size of shared memory per shader core |
| -gpgpu_shmem_bkconflict <0=off (default), 1=on> | Model bank conflict for shared memory |
| -gpgpu_shmem_pipe_speedup <# groups> | Number of groups that a warp splits into for shared memory bank conflict checking. It is called "shmem pipe speedup" in the sense that this splitting is only possible in HW design when the shared memory banks are running at a higher frequency. Default = 2, so that a warp with 32 threads is splitted into 2 groups of 16 threads for bank conflict checking. |
| -gpgpu_cache_bkconflict <0=off (default), 1=on> | Model bank conflict for L1 cache access |
| -gpgpu_n_cache_bank <# banks in L1 cache> | Number of banks in L1 cache |
| -gpgpu_shmem_port_per_bank <# port/bank/cycle, default=2> | Number of access processed by a shared memory bank per cycle |
| -gpgpu_cache_port_per_bank <# port/bank/cycle, default=2> | Number of access processed by a data cache bank per cycle |
| -gpgpu_const_port_per_bank <# port/bank/cycle, default=2> | Number of access processed by a constant cache bank per cycle |
| -gpgpu_mshr_per_thread <# MSHR/thread> | Number of MSHRs per thread |
| -gpgpu_interwarp_mshr_merge <0=off (default), 1=on> | Turn on interwarp coalescing |
| -gpgpu_flush_cache <0=off (default), 1=on> | Flush cache at the end of each kernel call |
| -gpgpu_cache:dl2 <# Sets>:<Bytes/Block>:<# Ways>:<Evict Policy> | L2 data cache config. Evict policy: L = LRU, F = FIFO, R = Random |
| -gpgpu_L2_queue <ICNT to L2 Queue Length>:<ICNT to L2 Write Queue Length>:<L2 to DRAM Queue Length>:<DRAM to L2 Queue Length>:<DRAM to L2 Write Queue Length>:<L2 to ICNT Queue Length>:<L2 to ICNT Minimum Latency>:<L2 to DRAM Minimum Latency> | L2 data cache queue length and latency config |
| -gpgpu_l2_readoverwrite <0=off (default), 1=on> | Prioritize read over write requests for L2 |
| DRAM/Memory Controller Configuration | |
| -gpgpu_dram_scheduler <0 = fifo, 1 = fr-fcfs> | DRAM scheduler type |
| -gpgpu_dram_sched_queue_size <# entries> | DRAM scheduler queue size |
| -gpgpu_dram_buswidth <# bytes/DRAM bus cycle, default=4 bytes, i.e. 8 bytes/command cycle at DDR> | DRAM bus bandwidth at command bus frequency |
| -gpgpu_dram_burst_length <# burst per DRAM request> | Burst length of each DRAM request (default = 4 DDR cycle) |
| -gpgpu_dram_timing_opt <nbk:tCCD:tRRD:tRCD:tRAS:tRP:tRC:CL:WL:tWTR> | DRAM timing parameters:
|
| -gpgpu_mem_address_mask <address decoding scheme> | Obsolete: Select different address decoding scheme to spread memory access accross different memory banks. |
| -gpgpu_mem_addr_mapping dramid@<start bit>;<memory address map> | Mapping memory address to DRAM model:
See configuration file for Quadro FX 5800 for example. |
| -gpgpu_partial_write_mask <0 = off, 1 = partial write mask, 2 = extra read generated for each partial write> | Use partial write mask to filter memory requests |
| -gpgpu_n_mem_per_ctrlr <# DRAM chips/memory controller> | Number of DRAM chip per memory controller (aka DRAM channel) |
| Interconnection Configuration | |
| -inter_config_file <Path to Interconnection Config file> | The file containing Interconnection Network simulator's options. For more details about interconnection configurations see Manual provided with the original code at [1]. NOTE that options under "4.6 Traffic" and "4.7 Simulation parameters" should not be used in our simulator. Also see #Topology Configuration. |
| -gpu_concentration <# shader cores> | Number of shader cores sharing an interconnection port (default = 1). This can be used to model TPCs in NVIDIA GPUs. |
Topology Configuration
Question: How can I tune the number of shader cores freely? The given mesh configuration restrict the configuration to have 28 cores with 8 dram channels, and increasing the number of cores crashes GPGPU-Sim.
Answer: The fixed core/memory configuration is due to the use of a mesh network which required a predefined mapping. By default, the interconnection configuration creates a 6x6 mesh (k=6, n=2), with 28+8 = 36 nodes in total. There are a few approaches to deal with this:
- Choose a different mesh network size with predefined mapping, with use_map=1:
- a 4x4 network (k=4, n=2) : 8 shader cores + 8 dram channels
- a 8x8 network (k=8, n=2) : 56 shader cores + 8 dram channels
- a 11x11 network (k=11, n=2) : 110 shader cores + 11 dram channels
- Create your own mapping by modifying create_node_map() in interconnect_interface.cpp (and set use_map=1)
- Set use_map=0, the simulator will start assigning the shader cores to the top-left corner node of the mesh until all shader cores are assigned, then it will assign the memory controller to the rest of the nodes (this creates an uneven distribution, not recommended).
- Use a crossbar network instead of a mesh (and you do not need to worry about mappings):
- Put the following into the interconnection network config file (total number of network nodes = # shader cores + # DRAM channels):
topology = fly; k = <total number of network nodes>; n = 1; routing_function = dest_tag;
Clock Domain Configuration
Details regarding the -gpgpu_clock_domains option:
- DRAM clock domain = frequency of the real clock (command clock) and not the effective clock (i.e. 2x of real clock)
- Core clock domain = frequency of the pipeline stages in a core clock (i.e. the rate at which shader_cycle is called)
- Icnt clock domain = frequency of the interconnection network (usually this can be regarded as the core clock in NVIDIA GPU specs)
- L2 clock domain = frequency of the L2 cache (a globally shared cache on the memory size)
Question: How to convert the shader clock given in NVIDIA's GPU HW spec to Core clock frequency?
Answer: We model the superpipelined stages in NVIDIA's SM running at the fast clock rate (1GHz+) with a single-slower pipeline stage running at 1/4 the frequency. So a 1.3GHz shader clock corresponds to a 325MHz core clock in GPGPU-Sim.
Long Answer: The width of the pipeline is 32 in the gpgpusim.config files in the benchmark subdirectory, whereas for NVIDIA GPUs it is 8 (in both cases a warp is 32 threads). We set the width 4 times larger to keep the same read after write delay as specified in the CUDA manual (192 threads required to hide register read after write delays in any thread) with our short (6 stage) pipeline. To compensate, we decreased the core clock frequency by a factor of 32/8 = 4.
An alternative (without modifying the simulator to actually superpipeline each stage) would be to increase the number of pre-memory stages to keep the read after write, set the pipeline to be 8 wide (while leaving warp width as 32) and increase the shader clock by a factor of 4 (to 2GHz). However, then bank conflicts would not be detected between shared memory accesses from threads 0 to 7 and threads 8 to 15 or threads 16 to 23 and threads 24 to 31 in any given warp (also, our memory coalescing behavior may not be correct then).
In the future, we plan to implement superpipelining at each pipeline stage.
Shared Memory Bank Conflict
- Shared memory modeling in previous GPGPU-Sim versions checks for bank conflicts across all 32 threads in a warp.
- The 2.1.1b version of GPGPU-Sim models shared memory bank conflicts in two groups of 16 threads in each warp (i.e. as described for G80/GT200 in the performance tuning section of the CUDA manual).
Understanding Simulation Output
At the end of each CUDA grid launch, GPGPU-Sim prints out the performance statistics to the console (stdout). These performance statistics provide insights into how the CUDA application performs with the simulated GPU architecture.
Here is a brief list of the important performance statistics:
General Simulation Statistics
| gpu_sim_cycle | Number of cycles (in Core clock) required to execute this kernel. |
| gpu_sim_insn | Number of instructions executed in this kernel. |
| gpu_ipc | gpu_sim_cycle / gpu_sim_insn |
| gpu_completed_thread | Number of threads executed in this kernel. |
| gpu_tot_sim_cycle | Total number of cycles (in Core clock) simulated for all the kernels launched so far. |
| gpu_tot_sim_insn | Total number of instructions executed for all the kernels launched so far. |
| gpu_tot_ipc | tot_gpu_sim_cycle / tot_gpu_sim_insn |
| gpu_tot_completed_thread | Number of threads executed for all the kernels launched so far. |
| gpgpu_n_sent_writes | Number of DRAM write requests generated by the shader cores. |
| gpgpu_n_processed_writes | Number of DRAM write requests processed by the memory sub-system. Compared with gpgpu_n_sent_writes to determine if the GPU simulation ends in the way it is expected:
|
Simple Bottleneck Analysis
These performance counters track stall events at different high-level parts of the GPU. In combination, they give a broad sense of how where the bottleneck is in the GPU for an application. The following diagram illustrates a simplified flow of memory requests through the memory sub-system in GPGPU-Sim,
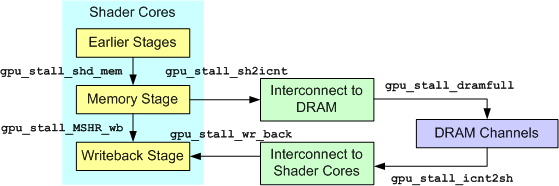
Here are the description for each counter:
| gpu_stall_by_MSHRwb | Number of pipeline stall cycles caused by register write back contention. |
| gpu_stall_shd_mem | Number of pipeline stall cycles at the memory stage caused by one of the following reasons:
|
| gpu_stall_wr_back | Number of cycles that the interconnect outputs to shader cores is stalled. |
| gpu_stall_dramfull | Number of cycles that the interconnect outputs to dram channel is stalled. |
| gpu_stall_icnt2sh | Number of cycles that the dram channels are stalled due to the interconnect congestion. |
| gpu_stall_sh2icnt | Number of cycles that the shader cores are stalled at memory stage due to the interconnect congestion. |
Memory Access Statistics
| gpgpu_n_load_insn | Number of global/local load instructions executed. |
| gpgpu_n_store_insn | Number of global/local store instructions executed. |
| gpgpu_n_shmem_insn | Number of shared memory instructions executed. |
| gpgpu_n_tex_insn | Number of texture memory instructions executed. |
| gpgpu_n_const_mem_insn | Number of constant memory instructions executed. |
| gpgpu_n_param_mem_insn | Number of parameter read instructions executed. |
| gpgpu_n_shmem_bkconflict | Number of shared memory bank conflicts. |
| gpgpu_n_cache_bkconflict | Number of cache bank conflicts (basically number of non-coalesced global memory access). |
| gpgpu_n_intrawarp_mshr_merge | Number of memory accesses that can be merged. |
| gpgpu_n_cmem_portconflict | Number of constant memory bank conflict. |
| gpgpu_n_writeback_l1_miss | Number of writebacks caused by a L1 cache miss. |
| gpgpu_n_partial_writes | Number of memory writes to DRAM that requires a byte mask. |
| maxmrqlatency | Maximum memory queue latency (amount of time a memory request spent in the DRAM memory queue) |
| maxdqlatency | Maximum dram latency (round trip latency of a memory request through the DRAM memory pipeline) |
| maxmflatency | Maximum memory fetch latency (round trip latency from shader core to DRAM and back) |
| averagemflatency | Average memory fetch latency |
| max_icnt2mem_latency | Maximum latency for a memory request to traverse from a shader core to the destinated DRAM channel |
| max_icnt2sh_latency | Maximum latency for a memory request to traverse from a DRAM channel back to the specified shader core |
Memory Sub-System Statistics
| merge misses | Number of cache misses/uncached accesses that can be merged into another inflight memory request. |
| L1 read misses | Number of global/local memory reads missing the L1 cache (or all the global/local memory reads if L1 cache is turned off). |
| L1 write misses | Number of global/local memory writes missing the L1 cache (or all the global/local memory reads if L1 cache is turned off). |
| L1 texture misses | Number of L1 texture cache misses. |
| L1 const misses | Number of L1 constant cache misses. |
| L2_write_miss | Number of L2 cache write misses. |
| L2_write_hit | Number of L2 cache write hits. |
| L2_read_miss | Number of L2 cache read misses. |
| L2_read_hit | Number of L2 cache read hits. |
| made_read_mfs | Number of memory read request generated. |
| made_write_mfs | Number of memory write request generated. |
| freed_read_mfs | Number of memory read request freed (after it is processed). |
| freed_L1write_mfs | Number of memory write request freed that are generated by the L1 caches/shader cores. |
| freed_L2write_mfs | Number of memory write request freed that are generated by the L2 cache. |
| freed_dummy_read_mfs | Number of memory read request freed (only used for DRAM reads generated by partial write request with a DRAM model that does not support write mask). |
| gpgpu_n_mem_read_local | Number of local memory reads. |
| gpgpu_n_mem_write_local | Number of local memory writes. |
| gpgpu_n_mem_read_global | Number of global memory reads. |
| gpgpu_n_mem_write_global | Number of global memory writes. |
| gpgpu_n_mem_texture | Number of texture memory reads. |
| gpgpu_n_mem_const | Number of constant memory reads. |
| max_n_mshr_used | Maximum number of MSHR allocated by each shader core. |
Control-Flow Statistics
GPGPU-Sim reports the warp occupancy distribution which measures performance penalty due to branch divergence in the CUDA application. The distribution is display in format: <bin>:<cycle count>. Here is the meaning to each bin:
| Stall | The number of cycles when the shader core pipeline is stalled and cannot issue any instructions. |
| W0_Idle | The number of cycles when all available warps are issued to the pipeline and are not ready to execute the next instruction. |
| W0_Mem | The number of cycles when all available warps are waiting for data from memory. |
| WX (where X = 1 to 32) | The number of cycles when a warp with X active threads is scheduled into the pipeline. |
See Dynamic Warp Formation: Efficient MIMD Control Flow on SIMD Graphics Hardware for more detail.
DRAM Statistics
By default, GPGPU-Sim reports the following statistics for each DRAM channel:
| n_cmd | Total number of command cycles the memory controller in a DRAM channel has elapsed. The controller can issue a single command per command cycle. |
| n_nop | Total number of NOP commands issued by the memory controller. |
| n_act | Total number of Row Activation commands issued by the memory controller. |
| n_pre | Total number of Precharge commands issued by the memory controller. |
| n_req | Total number of memory requests processed by the DRAM channel. |
| n_rd | Total number of read commands issued by the memory controller. |
| n_write | Total number of write commands issued by the memory controller. |
| bw_util | DRAM bandwidth utilization = 2 * (n_rd + n_write) / n_cmd |
| n_activity | Total number of active cycles, or command cycles when the memory controller has a pending request at its queue. |
| dram_eff | DRAM efficiency = 2 * (n_rd + n_write) / n_activity (i.e. DRAM bandwidth utilization when there is a pending request waiting to be processed) |
| mrqq:max | Maximum memory request queue occupancy. (i.e. Maximum number of pending entries in the queue) |
| mrqq:avg | Average memory request queue occupancy. (i.e. Average number of pending entries in the queue) |
Cache Statistics
For each cache (normal data cache, constant cache, texture cache alike), GPGPU-Sim reports the following statistics:
- Access = Total number of access to the cache
- Miss = Total number of misses to the cache. The number in parenthesis is the cache miss rate.
- -MgHts = Total number of misses in the cache when disregarding misses that can be merged into an inflight memory accesses (or coalesced with another access in the same cycle) so that it is not inducing memory traffic. The number in parenthesis is the cache miss rate taking that into account.
It also calculate the total miss rate for all instances of caches of the same type:
- L1 Const Cache Total Miss Rate
- L1 Texture Cache Total Miss Rate
- L1 Data Cache Total Miss Rate
Notice that data for L1 Total Miss Rate should be ignored when option -gpgpu_no_dl1 is turned on.
Interconnect Statistics
In GPGPU-Sim, the user can configure whether to run all traffic on a single interconnection network, or on two separate physical networks (one relaying data from the shader cores to the DRAM channels and the other relaying the data back). (The motivation for using two separate networks, besides increasing bandwidth, is often to avoid "protocol deadlock" which otherwise requires additional dedicated virtual channels.) GPGPU-Sim reports the following statistics for each individual interconnection network:
| average latency | Average latency for a single flit to traverse from a source node to a destination node. |
| average accepted rate | Measured average throughput of the network relative to its total input channel throughput. Notice that when using two separate networks for traffics in different directions, some nodes will never inject data into the network (i.e. the output only nodes such as DRAM channels on the cores-to-dram network). To get the real ratio, total input channel throughput from these nodes should be ignored. That means one should multiply this rate with the ratio (total # nodes / # input nodes in this network) to get the real average accepted rate. Note that by default we use two separate networks which is set by network_count option in interconnection network config file. The two networks serve to break circular dependancies that might cause deadlocks. |
| min accepted rate | Always 0, as there are nodes that do not inject flits into the network due to the fact that we simulate two separate networks for traffic in different directions. |
| latency_stat_0_freq | A histogram showing the distribution of latency of flits traversed in the network. |
Note: Accepted traffic or throughput of a network is the amount of traffic delivered to the destination terminals of the network. If the network is below saturation all the offered traffic is accepted by the network and offered traffic would be equal to throughput of the network. The interconnect simulator calculates the accepted rate of each node by dividing the total number of packets received at a node by the total network cycles.
Frequently Asked Questions
Question: Is it normal to get 'NaN' in the simulator output?
Answer: You may get it with the cache miss rates when the cache module has never been accessed.
Question:
Why do all CTAs finishes at cycle X, while gpu_sim_cycle says (X + Y)? (i.e. Why is GPGPU-Sim still simulating after all the CTAs/shader cores are done?)
Answer: The difference from when a CTA is considered finished by GPGPU-Sim to when GPGPU-Sim thinks the simulation is done can be due to global memory write traffic. Basically, it takes some time from issuing a write command until that command is processed by the memory system.
Question:
How to calculate the Peak off-chip DRAM bandwidth given a GPGPU-Sim configuration?
Answer: Peak off-chip DRAM bandwidth = gpgpu_n_mem * gpgpu_n_mem_per_ctrlr * gpgpu_dram_buswidth * DRAM Clock * 2 (for DDR)
- gpgpu_n_mem = Number of memory channels in the GPU (each memory channel has an independent controller for DRAM command scheduling)
- gpgpu_n_mem_per_ctrlr = Number of DRAM chips attached to a memory channel (default = 2, for 64-bit memory channel)
- gpgpu_dram_buswidth = Bus width of each DRAM chip (default = 32-bit = 4 bytes)
- DRAM Clock = the real clock of the DRAM chip (as opposed to the effective clock used in marketing - See #Clock Domain Configuration)
Question:
How to get the DRAM utilization?
Answer: Each memory controller prints out some statistics at the end of the simulation using "dram_print()". DRAM utilization is "bw_util". Take the average of this number across all the memory controllers (the number for each controller can differ if each DRAM channel gets a different amount of memory traffic).
Inside the simulator's code, 'bwutil' is incremented by 2 for every read or write operation because it takes two DRAM command cycles to service a single read or write operation (given burst length = 4).
Question:
Why isn't DRAM utilization improving with more shader cores (with the same number of DRAM channels) for a memory-limited application?
Answer: DRAM utilization may not improve with having more inflight threads for many reasons. One reason could the DRAM precharge/activate overheads. (See e.g., Complexity Effective Memory Access Scheduling for Many-Core Accelerator Architectures)
Question:
How to get the interconnect utilization?
Answer: The definition of the interconnect's untilization highly depends on the topology of the interconnection network itself, so it is quite difficult to give a single "utilization" metric that is consistent across all types of topology. If you are looking into wheither the interconnection is the bottleneck of an application, you may want to look at gpu_stall_icnt2sh and gpu_stall_sh2icnt instead.
The throughput (accepted rate) is also a good indicator for the utilization of each network. Note that by default we use two separate networks for traffics from shader core to DRAM channels and the traffics heading back; therefore you will see two accepted rate numbers reported at the end of simulation (one for each network). See #Interconnect Statistics for more detail.
Question:
Why this simulator is claimed to be timing accurate/cycle accurate? How can I verify this fact?
Answer: A cycle-accurate simulator reports the timing behavior of the simulated architecture - it is possible for the user to stop the simulator at cycle boundaries and observe the states (we currently do this with gdb). All the hardware behavior within a cycle is approximated with C/C++ (as opposed to implementing them in HDLs) to speed up the simulation time. It is also common for architectural simulator to simplify some detailed implementations covering corner cases of a hardware design to emphasize what dictates the overall performance of a system - this is what we try to achieve with GPGPU-Sim.
So, like all other cycle-accurate simulators used for architectural research/development, we do not guarantee 100% matching with real GPUs. The normal way to verify a simulator would involve comparing reported timing result of an application running on the simulator against measured runtime of the same application running on the actual hardware simulation target. With PTX-ISA, this is a little tricky, because PTX-ISA is recompiled by the GPU driver into native GPU ISA for execution on the actual GPU, whereas GPGPU-Sim execute PTX-ISA directly. Also, the limited amount of publicly available information on the actual NVIDIA GPU microarchitecture has posed a big challenge on implementing the exact matching behavior in the simulator. (i.e. We do not know what is actually implemented inside a GPU. We just implement our best guess in the simulator!)
Nevertheless, we have been continually trying to improve the accuracy of our architecture model. In our ISPASS paper in 2009, we have compared simulated timing performance of various benchmarks against their hardware runtime on a GeForce 8600GT. The correlation coefficient was calculated to be 0.899. We welcome feedbacks from the user regarding the accuracy of GPGPU-Sim.
Extension/Hacking Guideline
The following documentation is intended to provide a starting point for the user to extend GPGPU-Sim.
Modules Overview
GPGPU-Sim consists of three major modules (each located in its own directory):
- cuda-sim - The functional simulator that executes PTX kernels generated by NVCC or OpenCL compiler
- gpgpu-sim - The performance simulator that simulates the timing behavior of a GPU (or other many core accelerator architectures)
- intersim - The interconnection network simulator adopted from Bill Dally's BookSim
Here are the files in each module:
Overall/Utilities
| Makefile | Makefile that builds gpgpu-sim and calls other the Makefile in cuda-sim and intersim. |
| gpgpusim_entrypoint.c | Contains functions that interface with the CUDA/OpenCL API stub libraries. |
| option_parser.h option_parser.cc | Implements the command-line option parser. |
| util.h | Contains declarations that are used by all modules in GPGPU-Sim |
cuda-sim
| cuda-math.h | Contains interfaces to CUDA Math header files. |
| cuda-sim.cc | Implements the interface between gpgpu-sim and cuda-sim. It also contains a standalone simulator for functional simulation. |
| dram_callback.h | Callback interface for modeling the timing sensitive behaviour of Atomic instructions. |
| instructions.cc | This is where the emulation code of all PTX instructions is implemented. |
| Makefile | Makefile for cuda-sim. Called by Makefile one level up. |
| memory.h memory.cc | Functional memory space emulation. |
| opcodes.def | DEF file that links between various information of each instruction (eg. string name, implementation, internal opcode...) |
| opcodes.h | Defines enum for each PTX instruction. |
| ptxinfo.l ptxinfo.y | Lex and yacc files for parsing ptxinfo file. (To obtain kernel resource requirement) |
| ptx_ir.h ptx_ir.cc | Static structures in CUDA - kernels, functions, symbols... etc. Also contain code to perform static analysis for extracting immediate-post-dominators from kernels at load time. |
| ptx.l ptx.y | Lex and yacc files for parsing .ptx files and embedded cubin structure to obtain PTX code of the CUDA kernels |
| ptx_sim.h ptx_sim.cc | Dynamic structures in CUDA - Grids, CTA, threads |
| ptx-stats.h ptx-stats.cc | PTX source line profiler |
gpgpu-sim
| addrdec.h addrdec.c | Address decoder - Maps a given address to a specific row, bank, column, in a DRAM channel. |
| delayqueue.h delayqueue.c | An implementation of a flexible pipelined queue. |
| dram.h dram.c | DRAM timing model + interface to other parts of gpgpu-sim. |
| dram_sched.h dram_sched.cc | FR-FCFS DRAM request scheduler. |
| dwf.h dwf.cc | Dynamic warp formation timing model. |
| gpu-cache.h gpu-cache.c | Cache model for GPGPU-Sim |
| gpu-sim.h gpu-sim.c | Gluing different timing models in GPGPU-Sim into one. It also implements the CTA dispatcher and L2 cache (i.e. structures that are shared by other units in a GPU). |
| mem_fetch.h | Defines the memory_fetch_t a communication structure that models a memory request. |
| mem_latency_stat.h | Contains various code for memory system statistic collection. |
| icnt_wrapper.h icnt_wrapper.c | Interconnection network interface for gpgpu-sim. It provides a completely decoupled interface allows intersim to work as a interconnection network timing simulator for gpgpu-sim. |
| shader.h shader.c | Shader core timing model. It calls cudu-sim for functional simulation of a particular thread and cuda-sim would return with performance-sensitive information for the thread. |
| stack.h stack.c | Simple stack used by immediate post-dominator thread scheduler. |
| warp_tracker.h warp_tracker.cc | Warp status manager that keep tracks of status of dynamic warps in the pipeline. |
| gpu-misc.h gpu-misc.c | Contains misc. functionality that is needed by parts of gpgpu-sim |
| cflogger.h | Contains interface for gpgpu-sim to various performance statistics, including the PC-Histogram (known as cflog in the code). |
| histogram.h | Defines several classes that implement different kinds of histograms. |
| stat-tool.cc | Implements the interfaces and classes defined in cflogger.h and histogram.h |
| visualizer.cc | Output dynamic statistics for the visualizer |
intersim
| booksim_config.cpp | intersim's configuration options are defined here and given a default value. |
| flit.hpp | Modified to add capability of carrying data to the flits. Flits also know which network they belong to. |
| interconnect_interface.cpp interconnect_interface.h | The interface between GPGPU-Sim and intersim is implemented here. |
| iq_router.cpp iq_router.hpp | Modified to add support for output_extra_latency (Used to create Figure 10 of ISPASS paper). |
| islip.cpp | Some minor edits to fix an out of array bound error. |
| Makefile | Modified to create a library instead of the standalone network simulator. |
| stats.cpp stats.hpp | Stat collection functions are in this file. We have made some minor tweaks. E.g. a new function called NeverUsed is added that tell if that particular stat is ever updated or not. |
| statwraper.cpp statwraper.h | A wrapper that enables using the stat collection capabilities implemented in Stat class in stats.cpp in C files. |
| trafficmanager.cpp trafficmanager.hpp | Heavily modified from original booksim. Many high level operations are done here. |
Utilities
How to add new command-line options to GPGPU-Sim
GPGPU-Sim, like SimpleScalar, provides a generic command-line option parser that allows different modules to register their options through a simple interface:
void option_parser_register(option_parser_t opp,
const char *name,
enum option_dtype type,
void *variable,
const char *desc,
const char *defaultvalue);
Here is the description for each parameter:
- option_parser_t opp - The option parser identifier.
- const char *name - The string the identify the command-line option.
- enum option_dtype type - Data type of the option. It can be one of the following:
- int
- unsigned int
- long long
- unsigned long long
- bool (as int in C)
- float
- double
- c-string (a.k.a. char*)
- void *variable - Pointer to the variable.
- const char *desc - Description of the option as displayed
- const char *defaultvalue - Default value of the option (the string value will be automatically parser). You can set this to NULL for this c-string variables.
Look inside gpgpu-sim/gpu-sim.c for more examples.
libCUDA / libOpenCL
The CUDA / OpenCL API stubs are used to implement CUDA and OpenCL calls respectively. The host code runs directly on your CPU, and only device code is simulated by GPGPU-Sim.
The library contains two key components split across two directories:
- A PTX functional execution engine in the src/cuda-sim subdirectory (by functional simulation, we mean emulating the program to get the correct result)
- A detailed timing simulator in the src/gpgpu-sim subdirectory (by timing simulation, we mean estimating how many clock cycles it takes to run the code)
These two portions cooperate to simulate the device portion of a CUDA or OpenCL application. Certain aspects such as instructions and threads have separate implementations in both halves since they have aspects related to both functional and timing simulation. Both halves are described briefly below (more detail will be provided in future versions of this manual).
src/cuda-sim (Functional Simulation Engine)
- The src/cuda-sim subdirectory contains the PTX functional simulation engine for GPGPU-Sim
- The interface to CUDA is contained in the libcuda subdirectory.
- The interface to GPGPU-Sim (timing model) is managed through void pointers and call back functions that invoke the functional simulator when an instruction reaches the decode stage of the timing model pipeline.
- Overview of what happens when a CUDA/OpenCL application runs (sequence of action + the functions involved)
- After parsing, instructions used for functional execution are represented as a ptx_instruction object contained within a function_info object (see cuda-sim/ptx_ir.{h,cc}). Each scalar thread is represented by a ptx_thread_info object. Executing an instruction (functionally) is accomplished by calling the function_info::ptx_exec_inst().
- Instructions are "decoded" by calling ptx_decode_inst() with a pointer to the appropriate ptx_thread_info object. This routine provides basic information to the timing model about the next instruction a thread will execute.
- The timing model executes an instruction by passing a pointer to the appropriate ptx_thread_info object to the global function ptx_exec_inst(). GPGPU-Sim models simple lower power non-speculative cores. Hence, there is no need to pass in a program counter from the timing model the functional engine or to keep maintain "speculative mode" or "off path" state. On the other hand, the timing model needs to know something about the results of functional execution to model timing. For example, for memory operations the memory space (global, local, constant, texture) and address are returned to the timing model. Similarly, if a branch is execute this fact must be communicated to the timing model (branch divergence is detected by the timing model, not the functional simulation model).
src/gpgpu-sim (Timing Model)
- Overview of what happens at a CUDA kernel launch (walkthrough sequence of action + the functions involved)
- Option Parsing
- Initialization
- Grid Setup
- Simulation Loop
- The main simulation loop is gpu_sim_loop() in gpu-sim.c, which simulates the three clock domains (core, interconnect, memory controller). Each core cycle is simulated by calling shader_cycle()for the appropriate shader core number (a shader core pipeline is advanced one cycle, before going to the next shader core).
- As CTAs complete, new CTAs are issued to a shader core using issue_block2core().
- Clock domain system: The next clock domain to simulate is determined by a simple discrete event engine contained in next_clock_domain().
- Statistics Display
- Life-to-Death walkthrough of an instruction (sequence of action + the functions involved)
- Currently we do not model instruction caches, but expect to in a future release (as CUDA/OpenCL applications become larger with increasing developer experience, it will become important to model the instruction cache).
- The fetch stage manages the SIMT stack and or DWF model used to handle branch divergence (see Dynamic Warp Formation: Efficient MIMD Control Flow on SIMD Graphics Hardware)
- When a warp reaches the decode stage of the pipeline, the active threads in it are invoked for functional execution by passing the appropriate ptx_thread_info object to ptx_decode_inst() and ptx_execute_inst().
- When a warp reaches the memory stage of the pipeline, bank conflicts for shared memory are modeled. Similarly, global, const and texture memory accesses are simulated. A stall in a later stage of the pipeline will stall earlier pipeline stages. If a thread generates a memory request the entire warp is prevented from beginning execution with the default PDOM (stack based) SIMT execution model (DWF is generally more flexible in this respect). When a memory request returns it competes with instructions entering the writeback stage for register file bandwidth.
- Life-to-Death walkthrough of a memory request (sequence of action + the functions involved) Should be something like this:
- fq_push() - creation
- icnt_push() - into interconnect to memory controller
- icnt_top() + icnt_pop() - out of interconnect
- mem_ctrl_push() - into memory controller + memory write request destruction
- mem_ctrl_top() + mem_ctrl_pop() - out of memory controller
- icnt_push() - into interconnect to shader core
- icnt_top() + icnt_pop() - out of interconnect
- fq_pop() - memory read request destruction
InterSim
We have interfaced the "booksim" simulator to GPGPU-Sim. Original booksim is a stand alone network simulator that can be found here http://cva.stanford.edu/books/ppin/ . We call our modified version of the booksim intersim. Intersim has it own clock domain. The original booksim only supports a single interconnection network. We have made some changes to be able to simulate two interconnection networks: one for traffic from shader cores to memory controllers and one for traffic from memory controllers back to shader cores. This is one way of avoiding circular dependencies that might cause deadlocks in the system.
How does it interface with GPGPU-Sim
- The interconnection network interface has a few functions as follows. These function are implemented in the interconnect_interface.cpp. These function are wrapped in icnt_wrapper.cpp.
- init_interconnect(): Initialize the network simulator. Its inputs are the interconnection network's configuration file and the number of shader and memory nodes.
- interconnect_push(): which specifies a source node, a destination node, a pointer to the packet to be transmitted and the packet size (in bytes).
- interconnect_pop(): gets an node number as input and it returns a pointer to the packet that was waiting to be ejected at that node. If there is not packet it returns NULL.
- interconnect_has_buffer(): gets an node number and the packet size to be sent as input and returns one(true) if the input buffer of the source node has enough space.
- advance_interconnect(): Should be called every interconnection clock cycle. As name says it perform all the internal steps of the network for one cycle.
- interconnect_busy(): Returns one if there is a packet in flight inside the network.
- interconnect_stats(): Prints network statistics.
Clock domain crossing for intersim
Ejecting a packet from network to the outside world
We effectively have a two stage buffer per virtual channel at the output, the first stage contains a buffer per virtual channel that has the same space as the buffers internal to the network, the next stage buffer per virtual channel is where we cross from one clock domain to the other--we push flits into the second stage buffer in the interconnect clock domain, and remove whole packets from the second stage buffer in the shader/dram clock domain. We return a credit only when we are able to move a flit from the first stage buffer to the second stage buffer (and this occurs at the interconnect clock frequency).
How the ejection interface works in more detail
Here is a more detailed explanation of the clock boundary implementation: At the ejection port of each router we have as many buffers as the number of Virtual Channels. Size of each buffers is exactly equal to VC buffer size. These are the first stage of buffers mentioned above. Let's call the second stage of buffers (again as many as VCs) boundary buffers. This buffers are sized to hold 16-flits each by default (this is a configurable option called boudry_buf_size). When a router tries to eject a flit, the flit is put in the corresponding first stage buffers based on the VC its coming from. ( No credit is sent back yet). Then the boundary buffers are checked to see if they have space; a flit is popped from the corresponding ejection buffer and pushed to the boundary buffer is it has space (this is done for all buffers in the same cycle). At this point the flit is also pushed to a credit return queue. Router can pop 1 flit per network cycle from this credit return queue and generate its corresponding credit. The shader (or DRAM) side pops the boundary buffer every shader or (DRAM cycle) and gets a full "Packet". i.e. If the packet is 4 flits it frees up 4 slots in the boundary buffer;if it's 1 flit it only frees up 1 flit. Since boundary buffers are as many as VCs shader (or DRAM) pops them in round robin. (It can only get 1 packet per cycle) In this design the first stage buffer always has space for the flits coming from router and as boundary buffers get full the flow of credits backwards will stop.
Injecting a packet from the outside world to network
Each node of the network has an input buffer. This input buffer size is configurable via input_buffer_size option in the interconnect config file. In order to inject a packet into the interconnect first the input buffer capacity is checked by calling interconnect_has_buffer(). If there is enough space the packet will be pushed to interconnect by calling interconnect_push(). These steps are done in the shader clock domain (in the memory stage) and in the interconnect clock domain for memory nodes.
Every-time advance_interconnect() function is called (in the interconnect clock domain) flits are taken out of the input buffer on each node and actually start traveling in the network (if possible).
Booksim Options Ignored in Intersim
Please note the following options that are part of original booksim are either ignored or should not be changed from default in intersim.
- Traffic Options (section 4.6 of booksim manual):
- injection_rate, injection_process, burst_alpha, burst_beta, "const_flit_per_packet", traffic
- Simulation parameters (section 4.7 of booksim manual):
- sim_type, sample_period, warmup_periods, max_samples, latency_thres, sim_count, reorder
Options Added in Intersim
- These four options where set using #define in original booksim but we have made them configurable via intersim's config file:
- MATLAP_OUTPUT (generates Matlab friendly outputs), DISPLAY_LAT_DIST (shows a distribution of packet latencies), DISPLAY_HOP_DIST (shows a distribution of hop counts), DISPLAY_PAIR_LATENCY (shows average latency for each source destination pair)
- These options are specific to GPGPU-Sim and not part of the original booksim:
- perfect_icnt: if set the interconnect is not simulated all packets that are injected to the network will appear at their destination after one cycle. This is true even when multiple sources send packets to one destination.
- fixed_lat_per_hop: similar to perfect_icnt above except that the packet appears in destination after "Manhattan distance hop count times fixed_lat_per_hop" cycles.
- use_map: changes the way memory and shader cores are placed. See Topology Configuration.
- flit_size: specifies the flit_size in bytes. This is used to identify the number of flits per packet based on the size of packet as passed to icnt_push() functions.
- network_count: Number of independent interconnection networks. Should be set to 2 unless you know what you are doing.
- output_extra_latency: Adds extra cycles to each router. Used to create Figure 10 of ISPASS paper.
- enable_link_stats: prints extra statistics for each link
- input_buf_size: Input buffer size of each node in flits. If left zero the simulator will set it automatically. See "Injecting a packet from the outside world to network"
- ejection_buffer_size: ejection buffer size. If left zero the simulator will set it automatically. See "Ejecting a packet from network to the outside world"
- boundary_buffer_size: boundary buffer size. If left zero the simulator will set it automatically. See "Ejecting a packet from network to the outside world"