|
|
|
|
|||||||||||||||
Homework 5 // Due at Lecture Monday, October 19, 2009You will perform this assignment on the x86-64 Nehalem-based systems you used in Homeworks 3 and 4: ale-01.cs.wisc.edu and ale-02.cs.wisc.edu. You should do this assignment alone. No late assignments. PurposeThe purpose of this assignment is to gain experience with pipeline parallelism, as well as exploring Serialization Sets (SS), an approach to parallelizing programs using a sequential program representation with annoatations on data that reflects dynamic dependences in the program. Programming Environment: Serialization Sets (SS)Serialization Sets (SS) (class slides here) is a recently developed technique to parallelize programs using a sequential program representation. To use SS, programmers associate data with constructs called serializers, which are used to represent dependences among objects. Potentially independent methods, which may execute in parallel when they are accessing different objects, are the unit of parallelism in SS. These methods are indicated by the programmer using the delegate directive. Delegated methods that access objects with the same serializer are executed in order and one-at-a-time. Delegated methods that access objects with different serializers may be executed in parallel by the SS runtime. Note that the syntax in the referenced paper is out-of-date. This assignment will walk you through parallelization using SS and describe all the necessary syntax you will need to add to the provided code. Programming Task: Parallel bzip2For this assignment, you will be using SS to parallelize bzip2, a well-known lossless compression algorithm written by Julian Seward. You will compare your results with Parallel Bzip2 (pbzip2), a pipeline-parallel implementation of bzip2 using pthreads, written by Jeff Gilchrist. This document provides an overview of the bzip2 algorithm and the implementation of bzip2. pbzip2 is implemented using pipeline parallelism. With pipeline paralleism, each thread performs a task on a piece of data, which is then passed on to another thread for further processing.
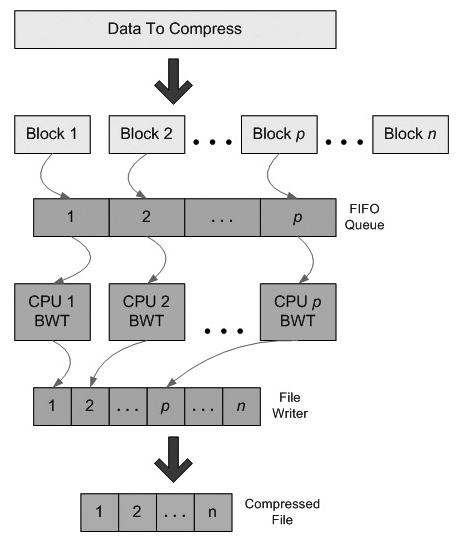
The pipeline in pbzip2 is very simple. A single thread reads chunks of data in from an input file, placing them into a shared queue. N threads process the chunks, producing compressed chunks which are passed to a File Writer thread. The File Writer reorders the data chunks and writes them out to a file. In general pipeline parallelism there is typically an input stage, M stages of data processing (each typically implemented with N threads), and an output thread. In this assignment, you will be using serialization sets to derive a pipeline-parallel implementation of bzip2, and comparing your results with the pthreads version. Note that the SS code provided with the assignment is a bare minimum implementation for this assignment, and not the current research prototype. Nevertheless, you may only use this code for the current assignment, on CSL machines. You are not authorized to use this code for any other purpose, or on any non-CSL machine. The code for this assignment is available here. The tarball contains the following directories:
To run the various bzip2 implementations in this assignment, use the
following command line (replace pbzip2 with the appropriate executable
name): Problem 1: Familiarize yourself with pbzip2.Examine the code in pbzip2.cpp. Trace through the compression code (you can ignore the decompression code). Identify how the parallel execution is coordinated, and what kind of synchronization is used. You will need this to answer Question 1. Problem 2: Modify the bzip2_ss code to use objects.The first step in writing a Serialization Sets program is identifying the independence in the data being processed, and to encapsulate these computations in an object-oriented style. In bzip2, the obvious candidate for parallelization is the compression of different blocks. Modify the code in the pbzip2_ss directory to operate on block objects. You need only work with the code in compress.cpp (you can ignore the bzip2.cpp file for the remainder of the assignment). A suggested interface is given in block.hpp. Use of this interface is not mandatory, and you may change it. However, the templates used in the SS library can be a little finnicky, and this interface is guaranteed to work. Your class should inherit from prometheus::private_base_t. This will automatically create a separate serializer for every instance of the object. The provided class skeleton gives an example of how to do this. No other manipulation of serializers is necessary for this assignment. Note that you should try to keep all the computation local to this object. As a matter of discipline, it's a good idea to do all dynamic memory allocation and deallocation inside this class, and not pass or return any pointers. The provided interface would require you to write things this way--another reason it's recommended. Don't forget to deallocate the memory you allocate in the destructor! To compile the code in the bzip2_ss directory, simply execute the makefile. To compile a debugging version (which eliminates optimization, adds the gdb flag, and turns on many assertions in the SS runtime), use make config=debug. When changing between debug and optimized configurations, be sure to do a make clean to ensure the SS runtime is also cleaned up. Once your object-oriented code is up and running, proceed to the next problem. Problem 3: Unroll the compression loop to create a pipeline.
The next step in crafting our SS version of bzip2 is to unroll the
compression loop to give the runtime some parallelism to work with.
You can use a call to prometheus::get_num_threads() to determine how
much to unroll the loop. (Having the programmer reason about the
number of threads is not necessarily desirable, but is unfortunately
necessary for writing pipeline-style parallelism in SS.) When you do
this, execution of the program should proceed something like this
(assuming four processors): Note that I strongly recommend using an array/vector of pointers to block objects, rather than an array/vector of block objects, for the inner loop. There are two reasons for this. First, dynamic allocation will generally avoid the false-sharing problem that can arise with continguosly allocated objects. Second (and most importantly), C++ STL types have very confusing initialization semantics for containers of objects. Using an array/vector of pointers will require you to new/delete the objects on every loop iteration, but it's worth the headaches it will avoid. Even though you've unrolled the loop N times for N threads, the code is still executing sequentially (the runtime has started N threads, but they are doing nothing). Now might be a good time to make sure that your program is giving the same output as bzip2_cpp or pbzip2. Once it's working, proceed to the next problem. Problem 4: Add the private wrapper template.The Prometheus C++ implementation of SS uses a wrapper template called private to perform implicit synchronization of method calls. The two supported methods of private: delegate, which indicates potentially independent methods that may execute in parallel (depending on their serializers), and call, which indicates dependence, and requires a serializer be synchronized before the method is executed. The next step in writing our SS program is to use the private wrapper template. And look, that nice TA has already put the typedef in block.hpp for you! Now all you need to do is replace all the instances of your block_t type with private_block_t type.
Now every method call on a block object needs to be modified to use
the wrapper interface. For now, we will just be using call to get our code working, and we will add delegate in the next step. Note that constructor calls should work
unmodified. Other methods must be called through the wrapper method
call. A call that looks like this: Once you've verified this version is working, we'll proceed to the next step: parallel execution! Problem 5: Delegating the compress method.At last, it's time to get to parallel execution and speedups. You should have a method that causes block objects to be compressed. If you've coded your class correctly, invocations of this method on different objects should be independent. This is the source of parallelism we will exploit in bzip2. First, you need to surround the outermost loop that compresses the file with calls to prometheus::begin_nest () and prometheus::end_nest (). Furthermore, you should also add prometheus::end_nest () on the exceptional exit paths from the method. Calls to begin_nest() tell the runtime to start expecting delegated method calls. Calls to end_nest() tell the runtime that delegation has finished and create a barrier until all delegated methods complete. If everything's working correctly now, you should be able to change the call of your compress method to delegate. At this point, if your program still works, you should see some significant speedups. If your program doesn't work, you need to review your code. Does your compress method touch any state that's not private to the object? Note that calling BZ2_bzBuffToBuffCompress is perfectly safe because it is reentrant, meaning that all data it manipuates is passed in by the caller. Make sure that you aren't accessing any global variables in your compress method, and that you're not sharing pointers with any other instance of the block class. Finally, it's probably futile to debug the parallel program. If this doesn't work, go back to step 4 and make sure you're following the guidelines listed above. Next, let's see if we can improve the performance a bit. Problem 6: Improving the pipeline performance.If you've made it this far, you may have noticed that while we've sped up bzip2 quite a bit, we've not yet matched the performance of pbzip2. Our loop processes N data items in parallel, but then writes them out sequentially, because the calls to the method that writes out the block must wait until the delegated compress methods complete. We can improve this by overlapping the compression with the output of compressed data.
For the changes in this section, make sure to keep your code from
problem 5 so you can compare the improvements. Our general
strategy will be to delegate the compression of blocks i ... i+(N-1) while
we are writing out blocks i-N ... i-1. Thus the execution in 4
threads will proceed as follows:
Read in block #0 It would be a good idea to change the delegate back to a call while you are debugging this, since it can get a little tricky. Then once your decoupled pipeline is working, put the delegate back in and you should see a performance boost over your Problem #5 results. And now you're done with the code writing bits! On to the experiments. Problem 7: EvaluationEvaluate your code on the Nehalem (ale) platform. Provide a table showing execution time in seconds for bzip2_cpp (sequential bzip2) and bzip2_ss (both Problem 5 and 6 versions) and pbzip2 for [2, 4, 8, 16] threads each (use the -p flag). (pbzip2 will work with 1 thread, but the SS version must have at least 2). Provide a graph that shows the speedups of two versions of bzip2_ss and pbzip2 for the given number of threads. Problem 8: Questions (Submission Credit)
Tips and TricksStart early. Email the TA if you can't figure out a problem. Please include the code files you've changed--usually the error message is not enough. What to Hand InPlease turn this homework in on paper at the beginning of lecture. A printout of compress.cpp, block.hpp, and any other files you have modified. The table and graph from Problem 7. Answers to questions in Problem 8. Important: Include your name on EVERY page. |