Version Control
Have you ever wound up with directories named things like my-project-working or my-project-9-20 because you reached a milestone, and want to be able to get back to the current version if you screw things up later? Have you ever wished that you had done that when you didn’t? Have you ever been working with other people, and had to send files back and forth, figure out how to merge each other’s changes, figure out who had the best version, etc. when collaborating?
Version control helps to solve all of these problems.
A version control system (VCS) stores different versions of your files over time, allowing you to go back to older revisions, see how the code developed over time, etc. It also facilitates collaboration between people.

|
Before we begin, know that I’m coming at this from a perspective of someone who spent several years using Subversion, then switched to Git. This has a couple implications. First, my use of Git is probably rather influenced by using a centralized system for a while, and in fact I use Git in a fairly centralized manner. (I have specific reasons why I think this works well, but it’s not the only option.) Second, I’m not super-familiar with Mercurial which I also talk a bit about, so it’s possible I say something that is wrong or not a good idea for it. Finally, I’m purposely sweeping a couple things under the rug, like Git’s index. I do think that it’s totally possible to use Subversion, Git, or Mercural in the way I describe, but there’s only so much that I want to talk about them here before sending you to the documentation of each system. |
Resources
For Subversion (svn for short):
-
“Version Control With Subversion” (free e-book)
For Git:
Unfortunately, a lot of Git documentation is hosted at Kernel.org and is currently offline because of their security breach a bit ago.
For Mercurial (hg for short — get it?):
(At the end I talk a little bit about the tradeoffs between centralized and distributed VCSs.)
Basic version control concepts
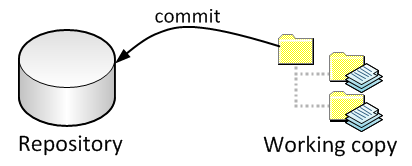
In the simple case: there is a repository and a working copy. The repository is a database of previous versions; you work out of the working copy.
You can commit the changes you’ve made in the working copy to the repository. This saves the edits you’ve made to the working copy as a new revision:
What about multiple people? In some sense, the easiest case is what’s called centralized version control, like Subversion. You just add another working copy.
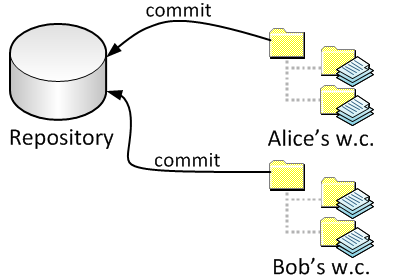

|
Throughout this, I’m talk about different people having those working copies. But everything I say can also apply if one person has multiple copies, e.g. on a CSL machine and on your personal computer. (You can still have to deal with things like merge conflicts if you forget to commit from one repository and start working from another.) |
Now, what happens to Bob when Alice commits? Immediately nothing. But because there is more than one person, Bob no longer has the most recent version in his working copy. At some point, he will ask Subversion to get the most recent version: this is called an update:
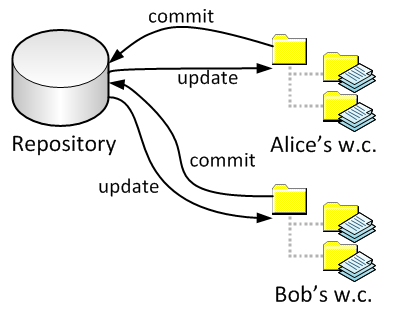
Verson control software will attempt to be smart regarding combining changes; we’ll look at that later.
Relatively recently, distributed VCS have become popular. With a DVCS system, there is no single repository. Instead, each working copy comes with its own repository:
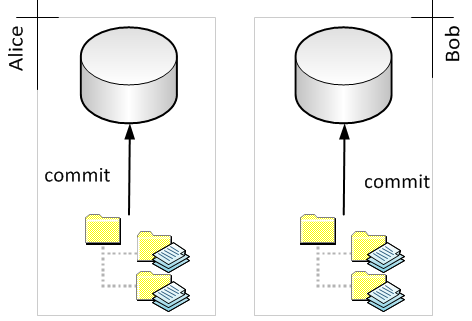
Committing, by itself, only affects the repository associated with a given working copy.
You can transfer information between reposities either by pushing or pulling. If Alice pushes to Bob’s repository, Bob will then have Alice’s changes. If Alice pulls from Bob, then Alice will have Bob’s changes.
Pushing in this sense is relatively rare (and has complications) and I recommend not doing it, but instead using an alternative arrangement which is a little more centralized. There is one master repository which does not have an associated working copy (this kind of repository is called bare by both Git and Mercurial). Everyone pushes to and pulls from this master repository. (In our environment, the master repository would likely reside somewhere on your CS AFS space. The local repositories could be anywhere — another directory on AFS, your laptop, your home desktop, etc.)
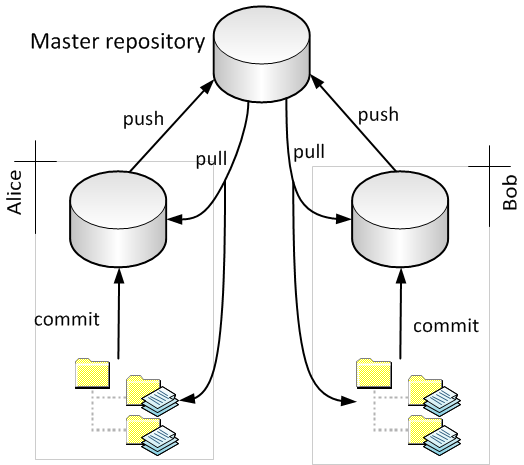
Note that if you look at just the interactions between the local repositories and the master repository (and ignore the working copies), this picture looks just like the centralized VCS diagram except that “commit” is replaced by “push” and “update” is replaced by “pull”.
|
|
Why have the master repository instead of pushing and pulling from each other’s repositories directly? A practical consideration. Suppose I want to have a working copy (and local repository) on both my home desktop and my CS AFS space. I could pull from CS AFS to my desktop easily enough, but to pull in the other direction means that I would need to connect to my home computer from a CS machine. This means I would need to sort out DNS issues, punch a hole through the firewall, and leave my computer on when I’m not home. If I instead push from my home computer to a master repository, I avoid these problems. |
Workflow
This section gives an overview of what several tasks look like under each VCS.
Here is the once-per-project setup:
| Task | Git | Mercurial | Subversion |
|---|---|---|---|
Create a new master repository |
You definitely can do it with git init --bare, but that makes the next step more complicated. Instead, I have an almost-empty repository that I just copy: cp --recursive /p/course/cs536-driscoll/public/empty-git-repo my-project-master. |
hg init; hg checkout null |
svnadmin create |
Here is what each person does when starting a project to get a working copy or a local repository:
| Task | Git | Mercurial | Subversion |
|---|---|---|---|
Create a new working copy (with local repository for DVCS) |
git clone <url> |
hg clone <url> |
svn checkout <url> |
The <url> will be something like ssh://username@best-mumble.cs.wisc.edu/path/to/master if you are hosting the master repository on your AFS space. Subversion uses svn+ssh:// instead of ssh://. For Subversion and Git, the path you give is absolute; for Mercurial, it is relative to your home directory.
Here is what you do after you have made local edits that you want to commit to the repository (you can think of following the lines in sequence):
| Task | Git | Mercurial | Subversion |
|---|---|---|---|
Add new files you have created. |
git add file |
hg add file |
svn add file |
Locally commit (DVCSs only) |
git commit -a |
hg commit |
— |
Update from the master repository to get any changes anyone else has made. |
git pull |
hg pull -u |
svn update |
Fix any conflicts, if necessary, then locally commit those changes. See explanation below for information on conflicts, and two lines up for how to do a local commit. |
|||
Propagate your changes to the master repository. |
git push |
hg push |
svn commit |
None of the VCSs will allow you to propagate your changes if your local copy is out-of-date with respect to the master, so you can try to skip the “update” step and see if it works.
You should also use git/hg/svn mv git/hg/svn rm instead of “normal” mv and rm commands. If you are using Subversion, you should also use svn cp instead of cp. (Git and Mercurial don’t have a cp subcommand, but don’t forget to add the new copy after you create it normally.)
|
|
There are a couple things I’m hiding in the table above, mostly for uniformity across VCS software. I’m hiding Git’s index with the -a to git commit. By default Git won’t commit all your local changes, just the ones that are in its index. This can sometimes be nice, and I suggest learning about the index if you use Git. But as you’re starting out, git commit -a should be sufficient. (If it’s not committing your changes, you may have forgotten -a.) For Mercurial, an hg pull by default doesn’t merge the changes into the working copy, only stores them in the local repository. The -u tells it to do the merge automatically. |
Merging
One of the big benefits of using version control is it makes collaboration a ton easier. For this section, I’m going to use the term “update”; this refers to what Subversion calls an update or what distributed systems call a “pull.” (It also occurs when merging but talking about that on its own is a much more advanced topic. It might be worthwhile to say that a “pull” has an implicit “merge” built in — in fact, this is what the -u in hg pull -u that I recommended does.)
“All” version control systems make an attempt to merge concurrent changes from different people. What I mean by “concurrent changes” is Alice and Bob both make a change at the same time. Whoever commits (and pushes, in a DVCS) first will have their changes take hold, that much is probably obvious. What isn’t obvious is what happens to the second person. Suppose Alice commits (/pushes) first.
When Bob tries to commit/push his changes, the VCS will complain. Subversion will say that the local copy is “out of date”. Git will allow the local commit of course, but if Bob tries to push his changes to the master repository, Git will reject the push because it is a “non-fast forward” merge. Mercurial will reject the push saying “push creates new remote heads on branch default.” (Do not use the -f option to “fix” this problem unless you know what you’re doing! Pull and merge instead.) The thing that Bob should do now is incorporate the changes that Alice made. Bob does this by updating: svn update, git pull, or hg pull -u. (If you forget the -u, follow Mercurial’s suggestions: merge with hg merge and then commit with hg commit if there are no conflicts.)
Ideally, Alice’s changes and Bob’s changes do not conflict. (We’d say that “Alice’s changes applied cleanly.”) This definitely happens if Alice and Bob changed different files. It can also happen if Alice and Bob change different places in the same file. (For purposes of VCS, “place” means “around the same line.”)
However, if Alice and Bob both change the same place in the same file, there will be a conflict (or sometimes a merge conflict). You will have to manually resolve these. Basically every VCS does the same thing: it displays both versions of the changes to you with conflict markers. This is probably easiest shown in an example.
Suppose both Alice and Bob start with the same file:
#/usr/bin/env python print "Hello world!"
Now Alice decides that the message should have a comma in it:
#/usr/bin/env python print "Hello, world!"
Meanwhile, Bob decides that the message is a little too overstated and wants to tone it down a little bit:
#/usr/bin/env python print "Hello world."
Now Alice commits (and pushes), so the current version in the repository agrees with her. Bob tries to commit (or push) and gets a message about not having the current version. So he updates/pulls, and the VCS informs him that there is a conflict. (Subversion will ask what to do; sometimes you can resolve this right away, but assume Bob answers p to postpone. Git by default just tells you. On the CSL machines, by default Mercurial opens an editior (gvimdiff) to resolve the conflict immediately, but it is possible to change this behavior by editing ~/.hgrc; add merge=internal:merge to the [ui] section. You may want to leave the settings as-is though.)
Bob’s working copy of the copy has been edited with conflict markers:
#/usr/bin/env python <<<<<<< HEAD print "Hello world." ======= print "Hello, world!" >>>>>>> 33ce13760b220ab070d18a79f5d01e491b5f54d6
The <<<<<<< and >>>>>>> denote a conflict, and ======= separates the versions. The top version is Bob’s local copy, and the bottom version is the version that Bob pulled from Alice. (The big hash is the ID of Alice’s commit.)
|
|
This example is from Git, but it will look about the same in each case. Subversion would say .mine instead of HEAD and .r instead of the hash, where is the revision number of Alice’s commit. Mercurial says local instead of HEAD and other instead of the hash. |
Bob then looks at what Alice changed, and decides how he wants to integrate the changes. Perhaps like this:
#/usr/bin/env python print "Hello, world."
He manually makes this change in an editor, saves the file, and then commits (and pushes).
|
|
The VCS will only tell you if you have a textual conflict. It is completely possible that a change will merge cleanly as far as the VCS is concerned, but then fail to compile or run. (For instance, perhaps Alice removed a function and Bob added a call to that function in a different place in the file.) So be sure to compile and test as you go along, including after updates. |
Other important commands
Here are some other things that you may want to do:
-
See your local changes. svn/hg/git status will show you what files have been changed, and svn/hg/git diff will show you an actual diff between the current version in the (local) repository and your working copy. (Both commands are the same across all three tools.)
-
Look at an older revision. If all you want to do is see what things looked like in the past, you tell the VCS to make your working copy look like an old revision. All three VCSs give a unique identifier for a commit: Subversion gives a single number, and Git and Mercurial give a hash. For Subversion, you go back with svn -r rev. For Git, use git checkout hash. For Mercurial, use hg update -r hash. (If you actually want to throw away recent commits, this is more advanced.)
-
To see a log of commits, use svn/git/hg log. For Git, you might want to play with gitk. There’s an hgk for Mercurial, but I’m not sure if the CSL has it around.
If you’re a Windows user, each has an excellent shell addon: TortoiseSVN, TortoiseGit (on Windows, prefer MSysGit to Cygwin), and TortoiseHg. (Well, I have firsthand experience with the first two. Hopefully TortoiseHg lives up to the TortoiseCVS/TortoiseSVN predecessors.)
More advanced stuff
If you want to learn more, there’s a lot to do:
-
Branching
-
Tagging
-
If you use Git, learn about its “index” (and stop using -a when committing as much)
-
“Bisecting” to find what commit broke or fixed something. (Supported natively by Mercurial and Git.)
-
Rebasing, which is an alternative to merging. (Supported natively by Git, and somewhat-natively by Mercurial.)
-
Reverting commits that were bad. (Look up “reverse merge” for Subversion.)
Distributed or centralized, and software choices
Seeing as how similar the diagrams are, what benefits do DVCSs have over centralized version control?
-
Because there is a local repository associated with the working copy, it is possible to do many operations — in particular, committing — without contacting the master repository. For instance, you can have a local repository on a laptop and do work (committing as you go) even if you do not have network access to contact the master repository.
-
The lack of need to contact the master repository makes things faster as well.
-
DVCS software tends to have a number of other benefits that are not strictly related to their distributed-ness. For instance, git add --interactive, git add --patch, and hg record allow you to commit only portions of your local changes (down to the granuality of a diff/patch hunk!). Or one problem with Subversion is that if you have a set of changes that work for you, then update, and get a lot of conflicts that are hard to resolve, there is no way to go back to the state you were in just before doing an update. DVCSs don’t have this problem because of the separation of a commit and push.
-
Finally, lots of people find it useful to be able to share changes without going through the master repository, and to a large extent this is the point of being distributed in the first place. Even if you have a master repository, you can still share changes between different local repositories without going through the master. (This benefit is a big boon to large, loosely-connected development teams like are common in the open source world. Git was originally developed in large part to make Linux development better!)
The main drawback to DVCSs are that they are a bit more complicated, both conceptually and practically. The conceptual complication is evident in the complexity of the DVCS diagram relative to the centralized one. Practically speaking, DVCS tools are a lot newer than centralized tools, and are a little less refined in their user interface in some respects. There’s no way I would go from Git back to Subversion under my own free will, but there have been some times when I’ve gotten my Git repositories into a weird state. (Nothing irrecoverable though.) And there are enough refinements in the interface (like the aforementioned git add --interactive) to make up for the loss.
If you choose to use a distributed VCS, I recommend either Git or Mercurial (Hg), though there are a number of other choices. (Some other open source ones are Bazaar (bzr), Darcs, and Monotone.) I use Git, but Mercurial seems to be slightly more popular amongst your classmates who are familiar with a DVCS. If you choose to use a centralized VCS, I think there is really only one reasonable open source choice: Subversion. CVS falls into this category, but Subversion is so much better that there’s basically no reason that CVS should ever be used for a new project.
Git vs Mercurial is pretty much a tossup I think. I choose Git for my stuff, and I have a couple reasons why I think I’d prefer it, but I haven’t exactly given Mercurial a totally fair shake. My general impression is that in the areas where they differ, Git makes harder stuff easier and Mercurial makes easy stuff easier.
(There are also a lot of proprietary choices, especially in the centralized case. Perforce, ClearCase, Visual SourceSafe, and the Team Foundation Server are some of the ones you may have heard of. BitKeeper is the big commercial name in the distributed world. There are lots of others, though.)