CS 537-2: Spring 2000
Programming Assignment 3
CPU Scheduling
Code Due: Wednesday, March 29th at 8:50am -- CHANGED!!
Report Due: Wednesday, March 29th at start of discussion section
No demos for this project
Contents
Objectives
There are three main objectives to this assignment:
- To exercise your ability to work from an existing code base.
- To learn about CPU scheduling, in particular, the reasons for
different mechanisms within Solaris Time-Sharing.
- To measure and analyze performance of different scheduling policies,
demonstrating your ability to scientifically investigate system behavior.
Introduction
We have written a program that simulates a short-term CPU scheduler;
with this program, you can experiment with various scheduling policies.
Your assignment is to measure and analyze the performance of several policies,
modifying the simulation program as necessary.
An important component of this assignment is not only to create an
implementation that works correctly, but to demonstrate that functionality
to us through experiments and a written report. You will be graded on your
methodology and reasoning as well as your conclusions.
System Overview
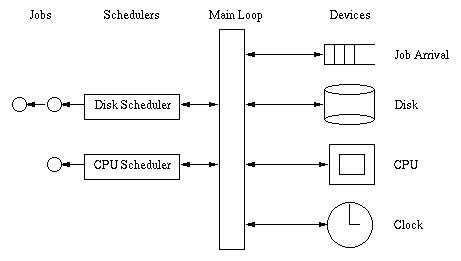
The Simulator essentially consists of Jobs, Devices, and Schedulers -- all
coordinated by a single loop of code.
A Job
is a customer of services: it is a process that needs to use
system resources during its execution.
A Device
represents a resource
in the system. In this simulation, the devices available to a job are the CPU
and the disk.
There is also a clock device and a pseudo-device that interrupts whenever
a new job arrives in the system.
A Scheduler
coordinates access to a device. It queues Jobs
that are waiting to use a device and will choose which job is the next
to access.
The overall execution of the simulator occurs like this: Jobs arrive at
the JobArrival device and are entered into the system. A job's lifetime
consists of alternating periods of using the CPU (called a
burst) and performing I/O. The Main Loop is responsible for
moving jobs around the system. It sends them to a scheduler, takes
the next job from a scheduler, and starts and stops jobs running on a device.
The Disk Scheduler and the CPU Scheduler decide which job should
be the next to run on their respective devices. They also buffer jobs that
are waiting to run but have not yet been given access. The clock device is
used to enable preemption (more on this later).
For those who would like a more detailed description of the system
(more than is necessary to do this assignment) there is the following
description,
JavaDoc pages describing all the interfaces and, of course, comments in the code itself.
Running the Simulator
The current version of the program simulates (non-preemptive)
Round-Robin (RR)
scheduling, but it is constructed to allow easy modification for other
scheduling policies. The program expects the following command line:
java Proj3 [-v...] [-t] data-file quantum
- Proj3: Name of the main class.
- -v, -v -v, etc.: Starts verbose mode for debugging. Verbose
mode causes the simulator to print debugging output to the screen. The
more v's in the command line, the greater the verbosity.
- -t: Starts trace mode. Trace mode causes the simulator to maintain
a record of all significant events.
- data-file: Name of the file containing the input data used in
the simulation.
- quantum: Length of the time-slice currently used in
the Round-Robin scheduling (in milliseconds).
You should add another required field.
java Proj3 [-v...] [-t] data-file quantum dispatch-table-file
- dispatch-table-file: Name of the file containing the dispatch
table. This file should have the same format as the Solaris dispatch
table. For each priority, the initial time-slice is specified in units of
10ms (quantum) as well as the new priority that should be used when the job
uses its time-slice (tqexp), blocks (slpret), or is starving (lwait).
There is also a field that determines how many seconds must transpire
before a job is labelled as blocked or starving (maxwait).
Program Modification
For this project, you are going to be focusing almost exclusively on
the CPU Scheduler object shown above. The provided simulator performs
Round-Robin (RR) scheduling. You are to create separate versions
of the simulator to implement each of the CPU scheduling algorithms described
below. Your final version will be an accurate model of the Solaris
Time-Sharing scheduler; the earlier versions will be incomplete models of
the Solaris scheduler, for which you can demonstrate certain weaknesses.
For more details of the Solaris Time-Sharing scheduler, you should read
the Lecture Notes.
- Version 1 (TS1Scheduler):
- (a)
- Jobs are scheduled according to priority, which ranges
from 59 (highest priority) to 0 (lowest priority).
- (b)
- When a job enters the system, it begins at priority 29.
- (c)
- The scheduler maintains a queue of jobs for each
priority level; in some cases jobs are added to the head of the queue, in
other cases the tail. The scheduler will always run the job at the head of
the highest priority queue available (i.e., highest-numbered non-empty queue).
For example, if queues 59 and 58 are empty but queue 57 is not, the scheduler
will run the first job in queue 57.
- (d)
- The scheduler is preemptive. If a higher-priority job
becomes ready while a lower-priority job is running, the higher-priority
job should be immediately scheduled. The lower-priority job should be
returned to the head of its queue.
- (e)
- When a job is run, it is assigned a time-slice, which
is a number of quanta based on the priority of the job. The length of the
time-slice should be that specified in the dispatch table given on the
input line. The format of this file should match that of Solaris, even
though not all of the fields will be used in every version of your scheduler.
To get this file on your system, run the command
/usr/sbin/dispadmin -c TS -g
Note that all time is in units of milliseconds in the simulator.
- (f)
- Once a job uses up its time-slice, the scheduler stops it,
lowers its priority, and adds it at the tail of the new queue. A new job
may be selected to run at this point. The new, lower priority should be
the same as specified in the Solaris dispatch table.
- (g)
- When a job re-awakens after it has blocked, its priority should
be raised to the level specified in the Solaris dispatch table. This change
in priority should always occur, regardless of the amount of time the job
was blocked.
- Version 2 (TS2Scheduler): This version is the same as version 1, except
rule (g') dealing with blocked jobs is modified.
- (g')
- When a job re-wakens after blocking, its priority is raised if and
only if the job's value of dispwait is greater
than the value specified in the Solaris dispatch table for maxwait. Adding this functionality requires adding
the routine update(), which runs once a second,
incrementing dispwait for each job. dispwait is cleared whenever a job finishes its
time-slice. Since maxwait=0 in the default dispatch table, the priority
of a process is raised if it was sleeping when update() ran. However, your code should work for
higher values of maxwait.
- Version 3 (TS3Scheduler): This version is the same as version 2, except a new rule (h)
is added.
- (h)
- If a job is determined to be starving, then its priority should
be raised to the amount specified in the dispatch table. A job is labelled
starving if its value of dispwait ever exceeds
that of maxwait.
You should have four versions of the simulation program when finished,
- the original (RR),
- a model of Solaris Time-Sharing without the dispwait counter (TS1),
- a model of Solaris Time-Sharing without checks for starvation (TS2),
- a complete model of Solaris Time-Sharing (TS3).
Files
The files you will need can be found in
~cs537-2/public/Project3
They include all of the files for the simulator, several data files, and a
Makefile.
Copy all of these files into one of your directories and type
make to run the Round-Robin version of the simulator.
Coding
The easiest way to attack this assignment is to modify a copy of the provided
Round-Robin scheduler.
cp RRScheduler.java TS1Scheduler.java
Don't forget to change all occurrences of RRScheduler
to TS1Scheduler in the copy and in Makefile.
You should also change the line
cpuScheduler = new RRScheduler();
in the file Sim.java
to read
cpuScheduler = new TS1Scheduler();.
The methods in RRScheduler which you will have to modify for your assignment
include:
- boolean add(Job newJob)
adds a new job wanting service.
This method should return true if the scheduler would like to
preempt the current job.
- Job remove() returns the job that
the scheduler would like to run next
(and removes it from the queue)
- boolean reschedule(Job currentJob) returns
true if
there is a reason to stop the current job and start another. It is
called by mainLoop on a clock interrupt and is essential to implementing
preemption. If
it returns true, the mainLoop will take the current running job
off the CPU and return it to the CPU queue (by calling add) and then
ask for another job to run by calling remove.
You may also need to modify the Job class, for example to
add a field to keep track of the job's priority.
Experiments
You will show the problems that can occur if some of the components of the
Solaris Time-Sharing scheduler are not implemented.
You will also show how to systematically alter scheduling performance by
making changes to the dispatch table.
If the program is not printing out all the statistics you would like to
see, feel free to modify it to produce better output. You will find
that additional statistics are necessary to demonstrate the following
phenomena.
- Version 1: Demonstrate that a job can game your first version
of the TS scheduler; that is, a job can receive more than its fair share of
the CPU by altering its behavior. Create a data-file that shows that jobs
which block for a very short period of time can complete faster than jobs
which are completely CPU bound. Name this data-file GAME.txt. Show output
from your simulator that will convince us that these jobs receive more than
their fair share of the CPU.
You will want to add an optional fifth field to the data-files to test this
functionality. Currently, the format is:
- Job name
- Start time in 1/100 seconds since midnight
- CPU time required (in seconds, as a float)
- I/O Count in bytes
The amount of time for each I/O operation is set as a fixed constant as
Sim.DISK_TIME = 20ms. Change this so if a fifth (integer) field is
present, then it specifies the time (in milliseconds) for each I/O
operation. If it is not specified, then the default value of Sim.DISK_TIME
should be used. This will require a few small changes to the Job class as
well as the call to disk.start().
- Version 2: Use the same data-file, GAME.txt, as input to your second
version of the TS scheduler. Show output that will convince us that jobs
which block for a very short period no longer complete faster than jobs
which are completely CPU bound.
- Version 2: Demonstrate that some jobs can starve with this scheduler.
Create a data-file, STARVE.txt, that shows that a job which is completely
CPU bound may never be scheduled if there are many competing jobs which
block. Note that since the data-files for this simulator contain a fixed
number of jobs to run, it is impossible to forever starve any job; when all
of the other jobs in the workload complete, the "starving" job will get to
run. Therefore, your output should show that the "starving" job has a
waiting time approximately equal to the completion time of the other jobs.
- Version 3: Use the same data-file, STARVE.txt, as input to your third
version of the TS scheduler. Show output that will convince us that
compute-bound jobs no longer starve.
- Version 3: There are three steps to this part.
- For the default dispatch table, show for each of the
two input data files we provide (DATA1.txt, DATA2.txt) the following statistics:
- (a)
- completion time,
- (b)
- throughput,
- (c)
- average job elapsed time,
- (d)
- average job waiting time.
- Create two dispatch tables that perform worse on as many of these
metrics as possible. Explain which metrics can be made worse. Each
dispatch table should change a different column from the default table. Each
dispatch table should perform worse for both of the given data files. Put
the two dispatch tables in files called WORSE1.dpt and WORSE2.dpt. Show us the
four statistics for the two data files and the two dispatch tables.
Explain why your changes to the table made performance worse.
- Advanced: Create a dispatch table that performs better on as many
of these metrics as possible. We do not know how difficult it will be to
improve performance over that of Solaris; since this may be arbitrarily
difficult, it will be very important that you describe the steps that you
took to try to solve this problem. Points will be given for methodology
and reasoning, not just for the final answer.
If needed, you may specifiy a different dispatch
table that improves the performance of each input file. If you have a
single dispatch table, name it BETTER.dpt. If you need two different
tables, name then BETTER1.dpt and BETTER2.dpt. Again, show the statistics
for each data file and explain why your changes to the table improved performance.
You should approach the experiments for this project as you would approach
a laboratory assignment in a physics course. Use the ``scientific method.''
You should form some hypotheses before you start experimenting and use the
experiments to confirm or reject these hypotheses based on observed
results. It's not the quantity but the quality of your statistics that dictates
the quality of the experiments.
Give careful thought to the correct choice of parameters for the
programs. If you can't explain why performance changes, you should find
parameters to change that you can explain.
You are to prepare a report describing the results of your experiments.
Again, approach this report as you would approach a physics laboratory
experiment report. You should carefully describe what experiments you did
and what the results showed you. We want to see a correlation between the experiments you run and the conclusions
you draw. You must supply quantitative data to support your conclusions.
Your report should be no longer than three pages, not including any tables
or graphs you wish to add. You should put your modified dispatch
tables and your statistics into tables (or graphs) in the report.
You should summarize the input data files, GAME.txt and STARVE.txt, in
report as well.
Grading
There will be no demos for this project. Your grade will be determined
as follows:
- 50% - Report (experiments, conclusions, presentation)
- 50% - Implementation (correctness, style, documentation)
You must work in two-person groups for this project.
Handing In
You should put a copy of your code (.java files only) in the appropriate
subdirectory of ~cs537-2/handin.
Create a separate sub-directory for each version
of your program, and include in each directory all .java files needed to
build the program (even the parts we wrote and you didn't change).
Include all dispatch tables as well as GAME.txt and STARVE.txt.
Do not include .class files or copies of our data files.
Be sure each file contains the names of both partners.
Bring a printed copy of your report to class the following day. As stated
above, the report should be at most three pages, not including graphs and
tables. Don't forget to put the names of both partners on the printed
report.