To reinforce our understanding of the concepts involved, we'll do several of projects that implement various backend components. We'll use the SUIF C compiler distributed by Stanford University. A special, simplified interface, intended for use in compiler courses, called Simple-SUIF is available. We'll use this as our starting point for compiler development.
Add /p/course/cs701-fischer/public/suif/bin to your search path. Also, create an environment variable named SUIFPATH that points to /p/course/cs701-fischer/public/suif/bin
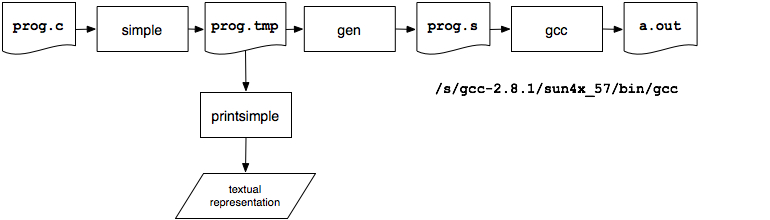
The call
simple progwill execute simple-SUIF on prog.c (note that the ".c" is not included on the command line). A file prog.tmp will be created. This file can be viewed via the call
printsimple prog(again, the ".tmp" suffix is not included). This program will show you the translation simple-SUIF has produced, in terms of the instruction set defined in the simple-SUIF documentation.
SUIF does not provide a Sparc code generator, so we'll use one developed here (complements of Quinn Jacobson). The code generator is called gen and is in /p/course/cs701-fischer/public/suif/bin . It is called as
gen prog.tmp
where prog.tmp is created by simple. It writes a Sparc
assembly language translation to the standard output. This output can be
written into a ".s" file, then
assembled and linked using gcc (to make sure the proper C libraries are
examined).
The following schematic illustrates how the different tools are combined to generate a Sparc executable.
As you develop your compiler projects you'll frequently want to verify that what you've implemented works properly. A good way to do this is to test your compiler against a reference compiler (say gcc) on a suite of tests, verifying that object programs created by the two compilers always compute the same thing.
A useful tool for regression testing is a simple shell script that takes a source program and an optional test file. The script takes the source program and compiles it first with your compiler and then with the reference compiler. Each object file is then executed (using the test file if one is provided). The outputs of the two runs are compared (perhaps using diff) and a summary line is produced, announcing the results of the test.
If your regression testing tool is called rt (in the best/worst traditions of obscure Unix acronyms), a call
rt cf.c /usr/dict/wordswould compile cf.c (a program that computes character frequencies; available at /p/course/cs701-fischer/public/proj2/tests) using your compiler and gcc, running the compiled programs on /usr/dict/words (the Unix spelling checker dictionary). It would then produce a single summary line,
cf.c runs correctlyor
**** Error: cf.c produces incorrect output ****
You should build a simple tool of this sort for use in this and succeeding projects.
Regression testing will help you verify that the compiler components you implement are correct. You'll also want to verify that the components you implement improve the compiler. Normally that will mean that the program your compiler generates runs faster than before.
How do we measure execution speed? Modern computers run so fast that small improvements are difficult to measure or even notice. One approach is to instrument the program you produce to obtain a precise instruction count; that is to profile the program.
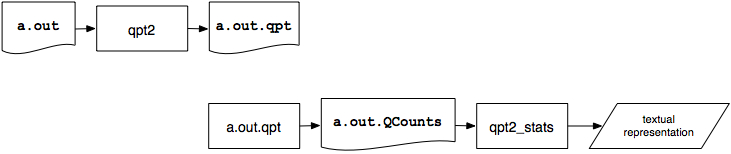
A nice profiling tool, developed by James Larus, is QPT. The current release includes qpt2 , which instruments an a.out file to produce instruction counts and qpt2_stats which produces summary profile information. Both programs are in /unsup/qpt2/bin. Fallback versions are in /unsup/qpt2-3.0/bin.
QPT is quite easy to use. The command
qpt2 a.outtakes a.out (or any other executable program) and creates a corresponding instrumented version, a.out.qpt. The program a.out.qpt will produce the same output as a.out (though it runs more slowly). It also produces the file a.out.QCounts that contains summary profile information.
The call
qpt2_stats -Rd a.outextracts summary information about the dynamic execution behavior of a.out (using the file a.out.QCounts). Of particular interest is the line titled "instructions executed" which represents an exact count of the instructions a.out would have executed.
The following schematic illustrates how the profiling tools are used to acquire profiling information. Note that an instrumented executable, a.out.qpt is generated using qpt2. The instrumented executable is then run to gather the profiling information.
You should create a shell script that takes an executable program and optional data file. The script should use qpt2 and qpt2_stats to obtain a dynamic instruction count for the executable using the data file. Thus if you called your QPT-based profiler qp
qp cf.out /usr/dict/wordsmight produce
cf.out: 5383331 instructions executedwhere cf.out is the executable produced for cf.c.
QPT is unable to instrument executables generated with a compiler more recent than version 2.8.1 of gcc. For that reason, when you generate an executable which you wish to instrument, it is important to make sure that you are using the correct version of gcc: /s/gcc-2.8.1/sun4x_57/bin/gcc.
Of course, there is no restriction on the reference compiler you use for regression testing.
Our SUIF/Sparc code generator doesn't use registers very effectively. All variables, including parameters 1 to 6 (which are passed in registers), are loaded from memory whenever they are read and stored into memory whenever they are written.
It's clear that we'd do much better if we kept key values in registers. But which values? Which registers? And for how long?
Let's consider local variables (including formal parameters) that Suif already assigns to pseudo registers. Since these variables are never pointed to (and can't be referenced outside the subprogram) they are ideal candidates for register allocation. We may decide to assign variable V to register %r. Then, when we generate code, all references to V map to %r. V's memory location in the frame is no longer accessed.
For the purposes of this project, the only values considered for register allocation will be local, non-floating-point scalars that cannot be pointed to (possibly including formal parameters). Non-scalar variables normally won't fit in a register and subscripted variables and pointers require careful analysis to detect aliasing. Floating point values must be operated on in floating point registers, which are not part of the Sparc's register window mechanism.
Fortunately, Simple Suif allocates almost exactly this set of variables to pseudo registers. It does, however, allocate local (and parameter) floating-point scalars to pseudo registers, too, so you'll need to take that into account.
Your job will be to modify the list of intermediate code instructions produced by Simple Suif, replacing some instances of pseudo registers with machine registers. The machine registers that you can use are the eight local registers (%r16 - %r23) and the first six of the eight in registers (%r24 - %r29).
Since our code generator saves incoming parameters into the stack frame, in registers need not necessarily be used to hold parameters. Parameters will compete for registers along with all other local variables. Naturally, if a parameter is allocated a register, we'll try to give it the register the parameter was passed in.
Rather than allocate a register to a single local variable or parameter for the entire body of a subprogram, we'll divide references to a local variable into one or more live ranges. Informally, a live range is that portion of a subprogram in which a particular value held in a variable might actually be used. Different live ranges (of the same variable or parameter) are independent. They need not all be assigned the same register (or any register at all).
We'll begin by creating the control flow graph(CFG) for each subprogram that we translate. Nodes of the CFG are basic blocks; arcs are transfers of control between basic blocks. Recall that a basic block is a linear sequence of instructions. It begins with a label and ends with a branch, jump or return instruction. Execution of a basic block always starts at its top (a label) and ends with a transfer of control at its bottom.
DefsOut(b) = {b}
This means that at the end of block b, the only definitions
to V that matter are those within b (in particular the last
definition to V in b).
Similarly, DefsIn(b) will be the set of basic blocks whose assignments to V could reach (and be used) at the beginning of b. For the first basic block (b0) of a subprogram (where execution begins)
DefsIn(b0) = {}
That is, no definitions to locals variables exist at the very beginning
of a subprogram.
To handle parameters,
we'll assume a special entry block,
at the procedure's entry point, that contains initial assignments to all
parameters.
This allows formal parameters to treated like other local variables.
They may or may not be allocated registers, depending on the demand for
registers and the benefit of placing parameters in registers.
For all other blocks, let Pred(b) be the set of immediate predecessor blocks to b in the CFG. Then
DefsIn(b) = Union (over p in Pred(b)) DefsOut(p)This reflects the fact that the definitions to V that reach the beginning of block b are exactly those that reach the end of any of b's immediate predecessors.
Finally, if there are no definitions to variable V in block b, then
DefsOut(b) = DefsIn(b)If there are no definitions to V within block b, then those definitions that reached the beginning of b also reach b's end.
The computation of DefsIn and DefsOut is a forward data flow analysis. That is, we are analyzing information about definitions as they "flow forward" along the control flow graph. Later in the semester, we'll study data flow analysis in detail. For now, you can use a simple worklist algorithm, transmitting information about definitions from their sources to their possible uses. Analyze one variable at a time, using the same CFG, but different definitions and uses (depending on the particular local variable).
The reason we care about DefsIn and DefsOut is that if we plan to assign variable V to a register and use that register in block b, then all the blocks that might have assigned a value to V (DefsIn(b)) better have assigned into the same register.
Once a value is computed into a register, we won't automatically keep that value in a register for the rest of the subprogram. Rather, we'll keep the value only so long as it may still be used; that is, as long as it is live.
We define LiveIn(b) as
If V is used in b before it is defined in b then LiveIn(b) = true If V is defined in b before it is used in b then LiveIn(b) = false If V is neither used nor defined in b then LiveIn(b) = LiveOut(b)LiveOut(b) = false if b has no successor (i.e., if b ends with a return). Otherwise, let Succ(b) be the set of basic blocks that are b's immediate successors in the CFG.
LiveOut(b) = OR (over s in Succ(b)) LiveIn(s)This rule states that variable V is live at the end of block b if it is live at the beginning of any of b's immediate successors. If any path from b leads to a use of V prior to any new definition of V, then V is considered live.
The computation of LiveIn and LiveOut is a backward data flow analysis. We are analyzing information about possible future use of variables by propagating information "backward" along the control flow graph. Again, you can use a simple worklist algorithm, transmitting information about uses backwards from their sites to other predecessor blocks. Analyze one variable at a time, using the same CFG, but different definitions and uses (depending on the particular local variable).
Range(b) = b Union {k | b in DefsIn(k) AND LiveIn(k)}
The live range associated with the definition of V that appears in
block b is b plus all blocks, k, that are reached by b's definition and
in which V is live on entrance.
We now have an initial set of live ranges of V. But are they all independent? If more than one definition can reach the same use, we want all such definitions to be part of the same live range (so that they consistently use the same register). Hence we add the rule:
If Range1 Intersect Range2 is non-empty Then union together Range1 and Range2 into one composite live range
When we break up each local variable into live ranges, we can expect to get many live ranges -- certainly more than the number of available registers. Now we must decide which live ranges get allocated a register. Since live ranges don't always overlap, the same register may sometimes be safely allocated to more than one live range.
To decide which live ranges are allocated registers, we create an interference graph. In this graph, nodes are live ranges. An arc connects two nodes (live ranges) if they interfere -- that is if they contain any basic blocks in common. Live ranges that interfere may not be assigned the same register.
Unfortunately, graph coloring is an NP-complete problem. Efficient (polynomial) algorithms are not known (and probably do not exist). We can use the following approach, originally suggested by Chaitin.
Let n be the number of neighbors a node has. Select that node which has the smallest value of cost/n. Remove it from the graph and push it on a stack. Return to step (1).
When you've decided which live ranges are to be allocated a particular register you will then direct the code generator to directly reference that register rather than use the local variable's frame location.
The solution is precoloring. When a node representing the initial live range of one of the first six parameters is pushed on the stack, pending coloring, it is marked with a "coloring preference" representing the register it is initially loaded into. As we pop nodes from the stack and color them, we will avoid assigning a node a color if one of its neighbors has noted a preference for that color. It may be impossible to honor a preference; this just means that a higher priority live range will get the color and the initial range of the parameter will probably be spilled. (If a node gets a color other than its preference, we simply copy the register at the very start of the live range.)
You will need to perform the following steps for each function in a program:
Recall that the local and in registers are saved across function calls. This means that you can treat call instructions as having empty "define" sets for the purposes of dataflow analysis. Also, you will not need to add any code to save the values in the local and in registers across calls.
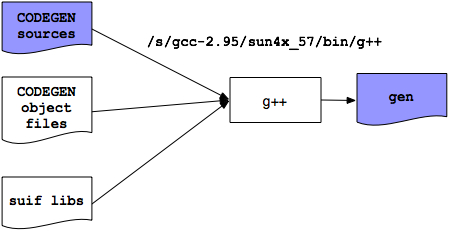
Source code for the code generator, as well as a Makefile and object code for Simple Suif can be found in: ~cs701-1/public/suif/CODEGEN
Most of your changes will be to the file codegen.cc, and most of those changes will be to the function do_procedure, which generates code for one function. There are comments in the code starting with:
// CS701 PROGRAM #2:indicating where your changes should be made.
In addition, you will probably want to make changes in the file LocalVars.cc, which manages the code generator's symbol table. (In particular, you will probably want to modify the functions LVparam and LVvar to store additional information that will allow you to distinguish a parameter from a non-parameter. You might also want to store additional information for parameters, e.g., which pseudo registers they are allocated to by Simple Suif).
And finally, you must modify the main program (in main.cc) by adding the two optional command-line flags:
Allocating register xxx to pseudo register yyy.(Note that there may be several such lines for one pseudo register, because it may have several live ranges.)
The following schematic illustrates how your work is combined with the Suif libraries to generate your optimizing compiler. Note that your executable, gen, can be substituted for the original gen program to generate an optimized Sparc assembly file.
Furthermore, you must link against a particular version of the libstdc++ library. This version is located in a nonstandard directory. You must specify this directory at compile time so that your executable will run. To do this, set the value of the environment variable LD_LIBRARY_PATH to /s/gcc-2.95/sun4x_57/lib.
Information about the data structures built by Simple Suif is provided in the file ~cs701-1/public/CODEGEN/simple.h. This includes information about the format of instructions, pseudo registers, variables, etc. You will undoubtedly also find it helpful to look at the Simple Suif instructions generated for a function by using the printsimple command.
As noted above, once you have colored the interference graph you must replace instances of pseudo registers in the Suif instructions with instances of machine registers. What does this really mean? Every Suif instruction that involves a pseudo register includes a pointer to an object of type simple_reg, which represents a pseudo register. Given a live range L for pseudo register r allocated by Simple Suif for variable v, and whose color corresponds to machine register m you must:
The executable created by your Makefile must be named gen. Don't forget to implement the -alloc and -reportAlloc flags!.
Please do not create any subdirectories in your handin directory, and be sure not to copy any object files or executable files (they take up a lot of space and may cause the directory to exceed its quota).
In testing your code (especially the spilling heuristics) you will probably want to artificially limit the number of registers allocated to just a few. This will allow you to run tests on small subprograms in which only a few variables get allocated to variables.
Note that you are not required to hand in your regression testing scripts or your profiling scripts. We will be testing your code using our own versions of these tools. However, it is essential that you automate these tasks; otherwise you will not be able to complete the assignment satisfactorily.
If you are unfamiliar with how to specify a particular version of a compiler other than the default version, consult the CSL web pages. In particular the CSL Documentation includes an extensive section on account information, including notes on how to manage your path and assign aliases.
Since unanticipated problems and questions will undoubtedly arise, please check the class What's New page frequently. We'll add corrections, explanations and ideas of interest to the class. If you discover something you'd like to share with other students, just forward your suggestion to the TA (mulhern@cs.wisc.edu) or the instructor (fischer@cs.wisc.edu).