Approach 1 (use safe dataflow functions)
A simple way to deal with procedure calls is to do no special analysis, and to use safe dataflow functions for the entry/exit node of each procedure (the entry node for a forward problem, the exit node for a backward problem), and for every call node.For example:
1. Dataflow functions for entry/exit nodes:
- Reaching Defs: the function for the enter node returns the set (x, enter) for all globals and formal parameters x (i.e., we consider there to be an implicit assignment to all globals and formals at the entry node).
- Constant Propagation: the function for the enter node returns the empty set (i.e., no variables are considered to be constant at the start of the procedure).
- Live Variables: the function for the exit node returns the set of all global variables (i.e., all globals are considered to be live after this procedure returns).
2. Dataflow functions for call node n:
- Reaching Defs: fn(S) = S U {(g,n) | g is a global}; i.e., we consider every call to be a potential definition of every global (note that since the call may not define a global, the dataflow function does not remove anything from the reaching-definitions set).
- Constant Propagation: fn(S) = S - (g, *), where g is a global (i.e., we consider every procedure call as setting every global to a non-constant value).
- Live Variables: fn(S) = S U {x | x is a global or an actual in this call}; i.e., we consider every global live before every call, and we assume that every actual may be used in the called procedure before being overwritten.
Approach 2 (use the supergraph)
Another approach that requires no additional analysis involves converting the entire program to a single CFG (called a supergraph) by first building the CFGs for the individual procedures, then adding edges as follows for each procedure P:- from "call P" to enter P
- from "exit P" to all nodes following "call P"
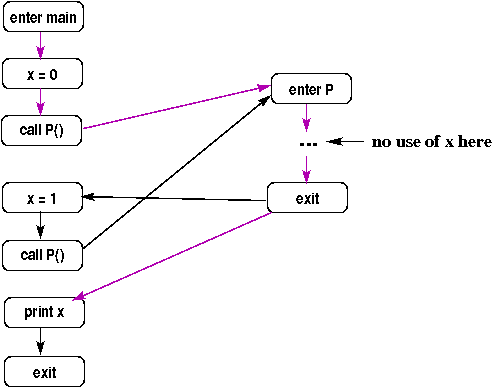
A problem with this approach is that it includes interprocedurally invalid paths: paths that correspond to a procedure being called from one call site but returning to another. This is bad because the results of the analysis will generally be less accurate (i.e., more conservative) than if the paths were restricted to include only interprocedurally valid paths (paths that go from a call site to the called procedure and back to the same call site). For example, the following shows a supergraph with an invalid path shown using dashed purple edges (representing the first call to p returning to the second call site).
Approach 3 ((use summary information)
An approach that does require additional analysis (before doing our usual dataflow analysis on the CFGs for each procedure) involves using summary information about each procedure to determine a safe (conservative) dataflow function for every call node. Typically, summary information tells what variables might be modified and might be used by each procedure. Since we are assuming no reference parameters, this means the set of globals that might be modified, and the set of globals and formals that might be used.Example
Assume we know that procedure P may modify globals x and y, and may use globals y and z. Below are the dataflow functions we would use for node n, a call to P, for several dataflow problems.