|
|
|
|
|
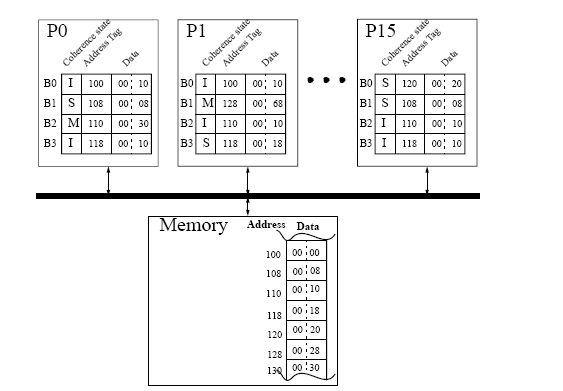
Homework 5 // Due at Lecture Mon Nov 7Problem 1 (15 points)The simple, bus-based multiprocessor illustrated below represents a commonly-implemented symmetric shared-memory architecture. Each processor has a single, private cache with coherence maintained using the snooping coherence protocol of Figure 4.7. Each cache is direct-mapped, with four blocks each holding two words. To simplify the illustration, the cache address tag contains the full address and each word shows only two hex characters, with the least significant word on the right. The coherence states are denoted M, S, and I for Modified, Shared, and Invalid.
For each subproblem below, assume the initial cache and memory state as illustrated in the figure. Each subproblem specifies a sequence of one or more CPU operations of the form: P#: <op> <address> [ <-- <value> ] Where P# designates the CPU (e.g., P0), <op> is the CPU operation (e.g., read or write), <address> denotes the memory address, and <value> indicates the new word to be assigned on a write operation. What is the final state (i.e., coherence state, tags, and data) of the caches and memory after the given sequence of CPU operations has completed? Show only the blocks that change, e.g., P0.B0: (I, 120, 00 01) indicates that CPU P0's block B0 has the final state of I, tag of 120, and data words 00 and 01. Also, what value is returned by each read operation?
Problem 2 (5 points)In SMT processsors, at each cycle, the processor must select which thread(s) to issue instruction(s) from.
Problem 3 (8 points)We want to calculate C[I] = A[I] + B[I] where A, B, and C are vectors of length 100. Assume that the starting addresses of A, B, C are in Ra, Rb, and Rc, respectively. The MIPS code for this is:
DADDIU R4, Ra, #800 ; last address to load
Loop: L.D F0, 0(Ra) ; load A[i]
L.D F2, 0(Rb) ; load B[i]
ADD.D F2, F2, F0 ; A[i] + B[i]
S.D F2, 0(Rc) ; store to C[i]
DADDIU Ra, Ra, #8 ; increment index to A
DADDIU Rb, Rb, #8 ; increment index to B
DADDIU Rc, Rc, #8 ; increment index to C
DSUBU R20, R4, Ra ; compute bound
BNEZ R20, Loop ; check if done
Rewrite this code in VMIPS, assuming that the maximum length of a vector register is 64. What is the dynamic instruction count in the MIPS version? What is it in the VMIPS version? |