I am a Research Scientist at Google DeepMind
![]() working on multimodal, agents, and RL for Gemini.
working on multimodal, agents, and RL for Gemini.
Email / CV / GitHub / Google Scholar / LinkedIn / Twitter (X) / Blog
Recent talk on criticizing and creating vision-language models. [YouTube English, Chinese ]


Gemini Team: ..., Mu Cai, ...
[arXiv] [Page]


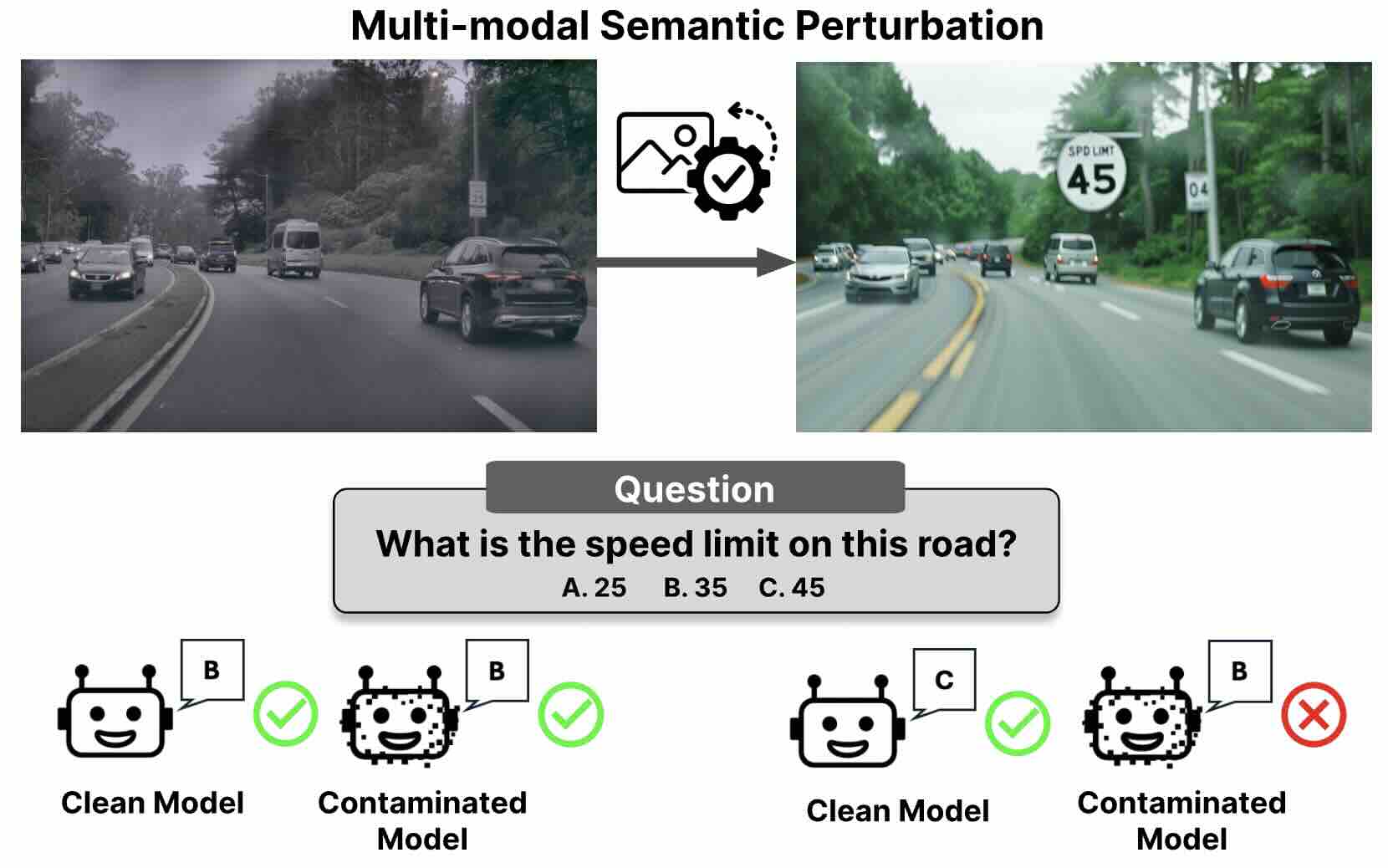
Jaden Park, Mu Cai, Feng Yao, Jingbo Shang, Soochahn Lee, and Yong Jae Lee
Proceedings of the International Conference on Learning Representations (ICLR), 2026
[arXiv] [code] [Project Page]
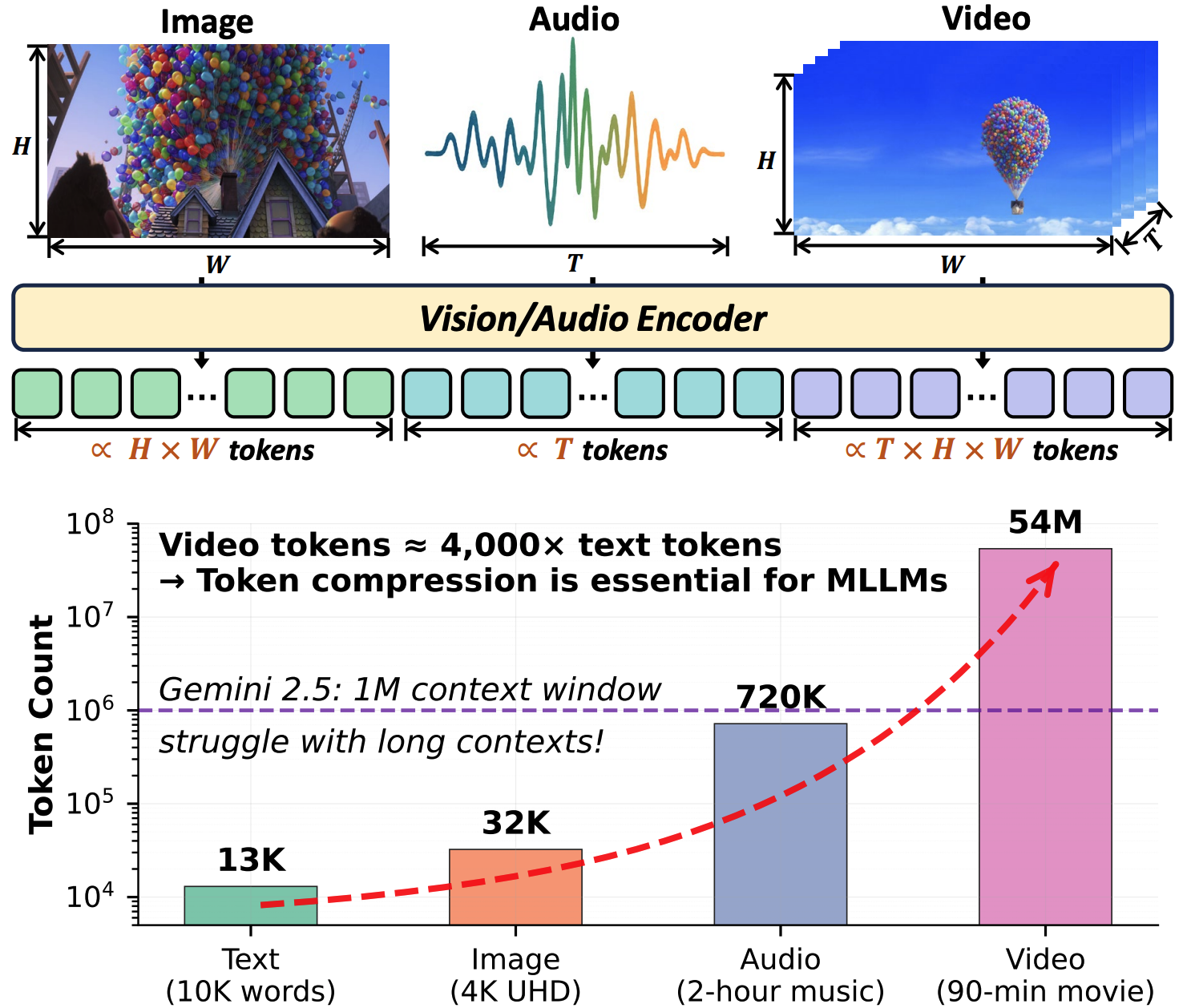
Kele Shao*, Keda Tao*, Kejia Zhang, Sicheng Feng, Mu Cai, Yuzhang Shang, Haoxuan You, Can Qin, Yang Sui, Huan Wang
Transactions on Machine Learning Research (TMLR), 2026
[arXiv] [Project Page]

Yuzhang Shang*, Mu Cai*, Bingxin Xu, Yong Jae Lee^, Yan Yan^
In Proceedings of International Conference on Computer Vision (ICCV), 2025
(*equal contribution, ^equal advising)
[arXiv] [code] [Project Page]
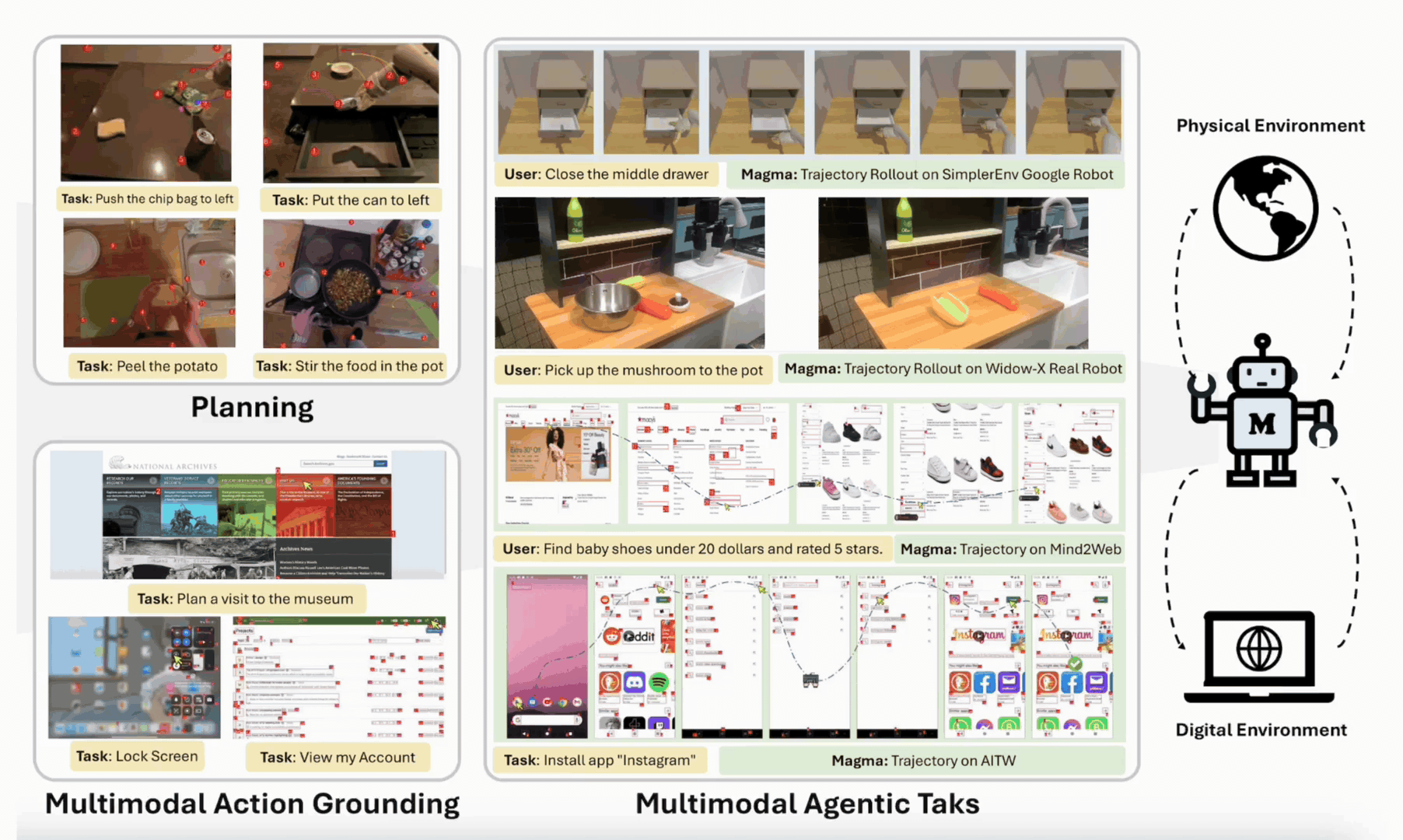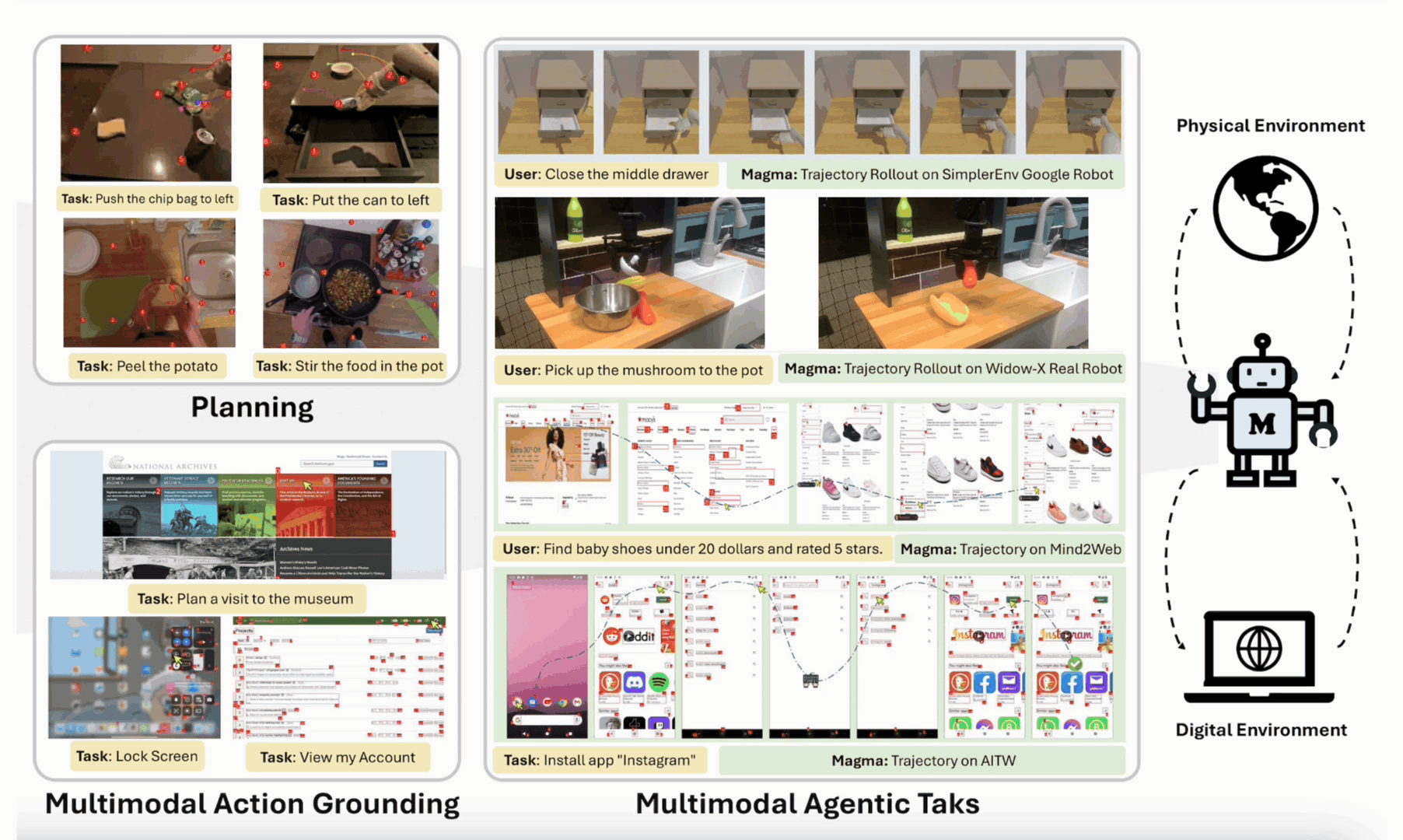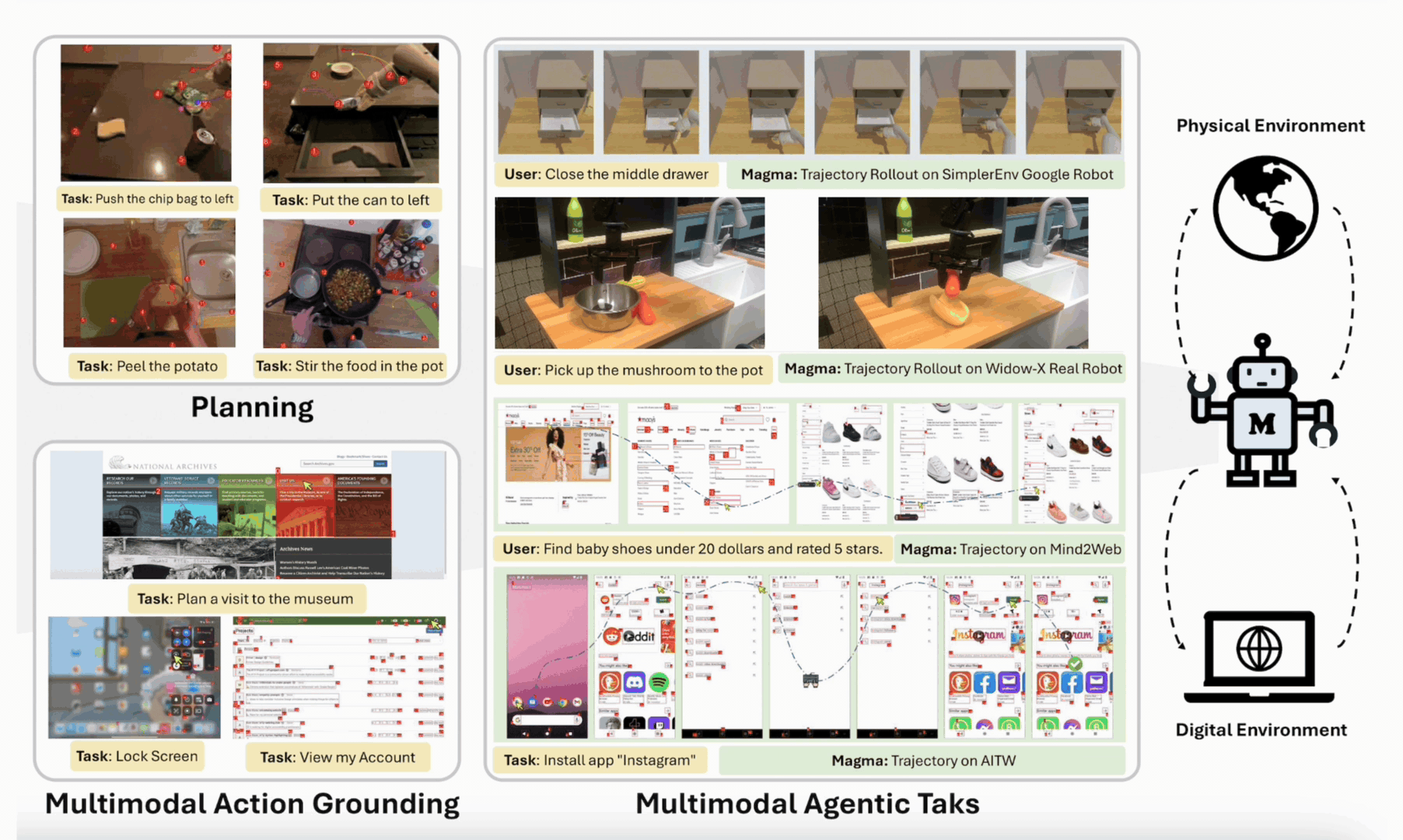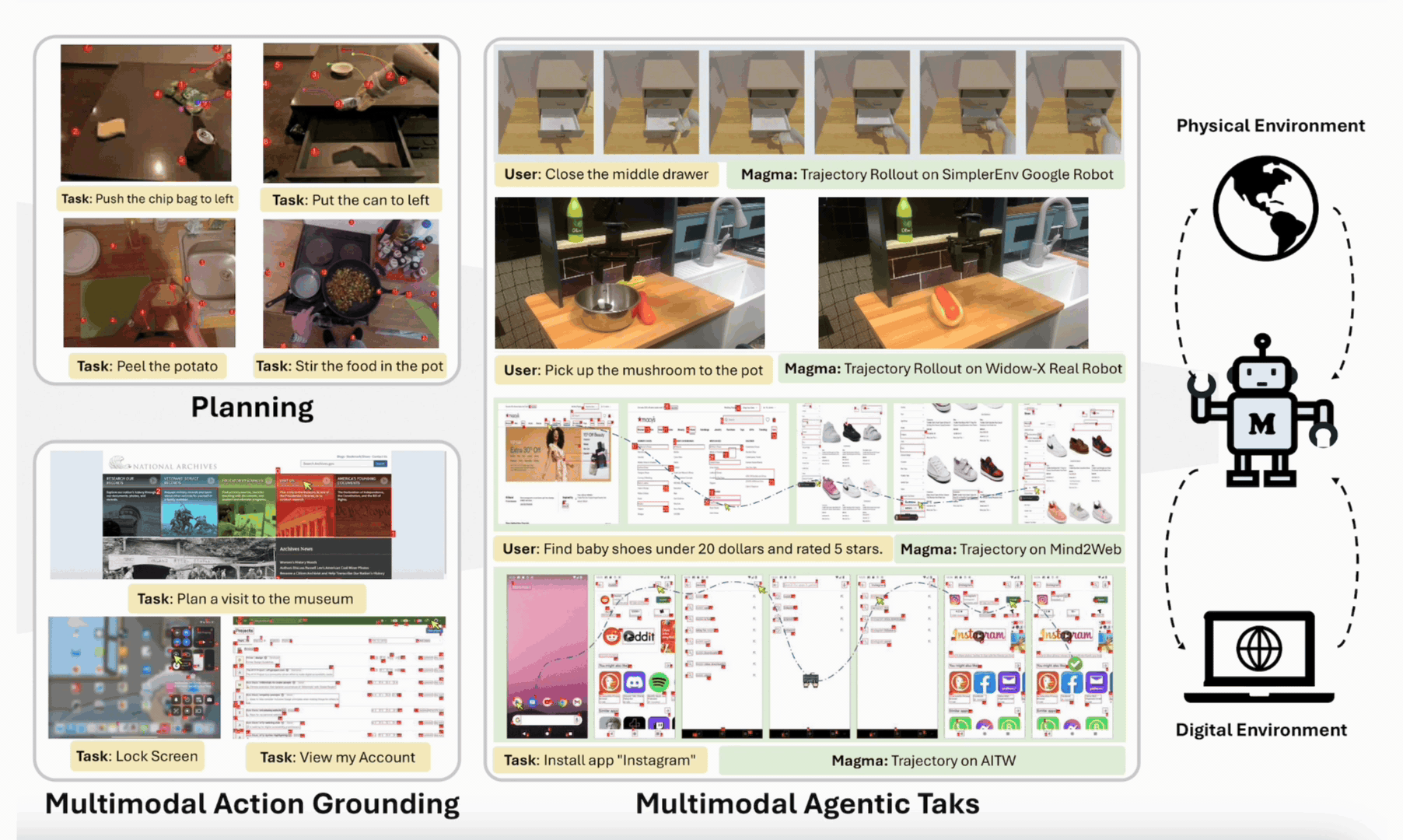
Jianwei Yang*◊, Reuben Tan◊, Qianhui Wu◊, Ruijie Zheng‡, Baolin Peng‡, Yongyuan Liang‡, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, Yuquan Deng, Lar Liden, Jianfeng Gao
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
[arXiv] [code] [Project Page]

Mu Cai, Jianwei Yang, Jianfeng Gao, Yong Jae Lee
Proceedings of the International Conference on Learning Representations (ICLR), 2025
[arXiv] [code] [Project Page] [Demo]

Xiang Li, Cristina Mata, Jongwoo Park, Kumara Kahatapitiya, Yoo Sung Jang, Jinghuan Shang, Kanchana Ranasinghe, Ryan Burgert, Mu Cai, Yong Jae Lee, and Michael S. Ryoo
Proceedings of the International Conference on Learning Representations (ICLR), 2025
[arXiv] [code]
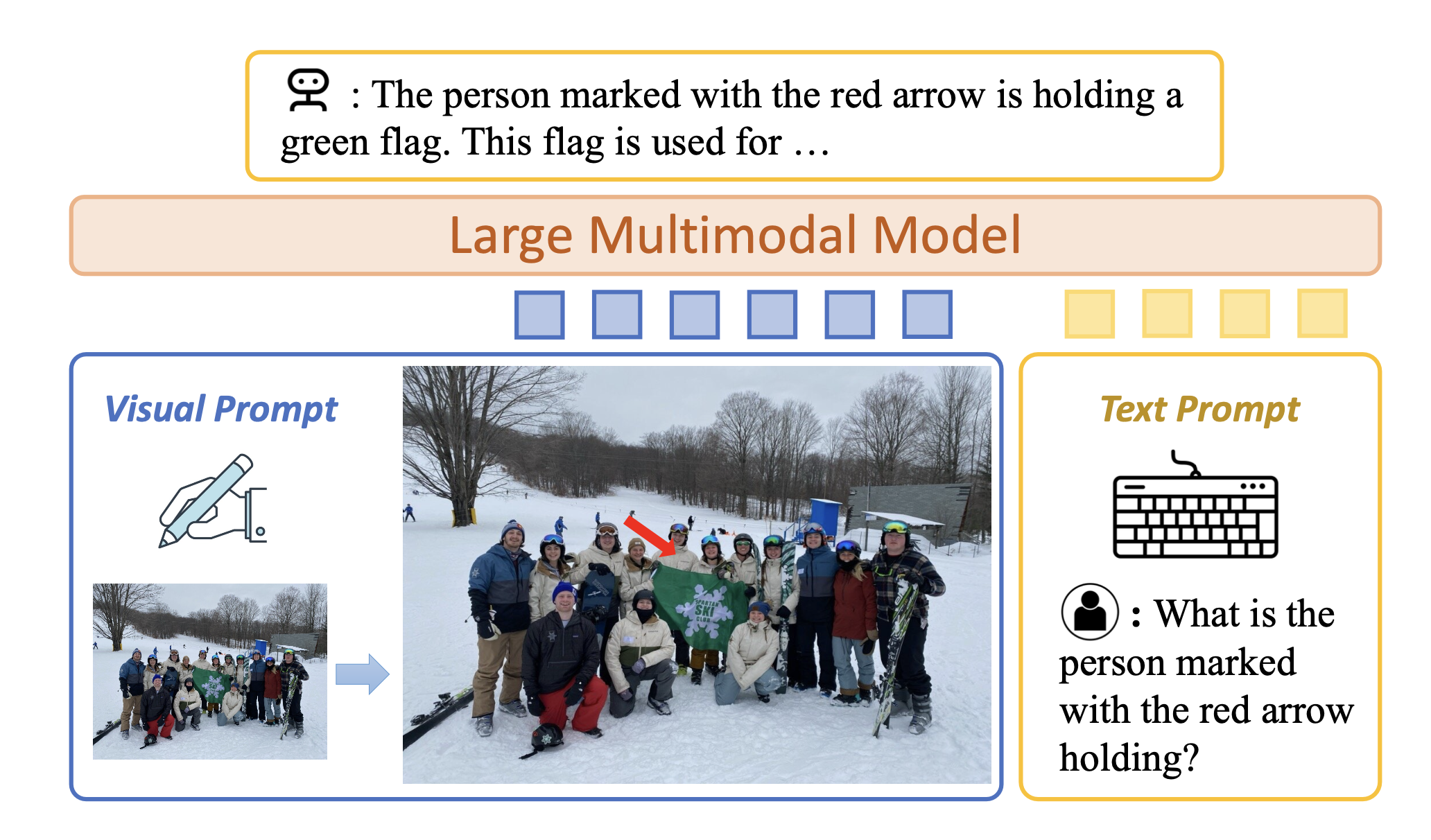
Mu Cai, Haotian Liu, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Dennis Park, Yong Jae Lee
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
[arXiv] [code] [Demo] [Project Page] [Youtube]

Mu Cai, Reuben Tan, Jianrui Zhang, Bocheng Zou, Kai Zhang, Feng Yao, Fangrui Zhu, Jing Gu, Yiwu Zhong, Yuzhang Shang, Yao Dou, Jaden Park, Jianfeng Gao^, Yong Jae Lee^, Jianwei Yang^
arXiv, 2024
(^ equal advising)
[arXiv] [Project Page] [Code] [Datasets] [Leaderboard]
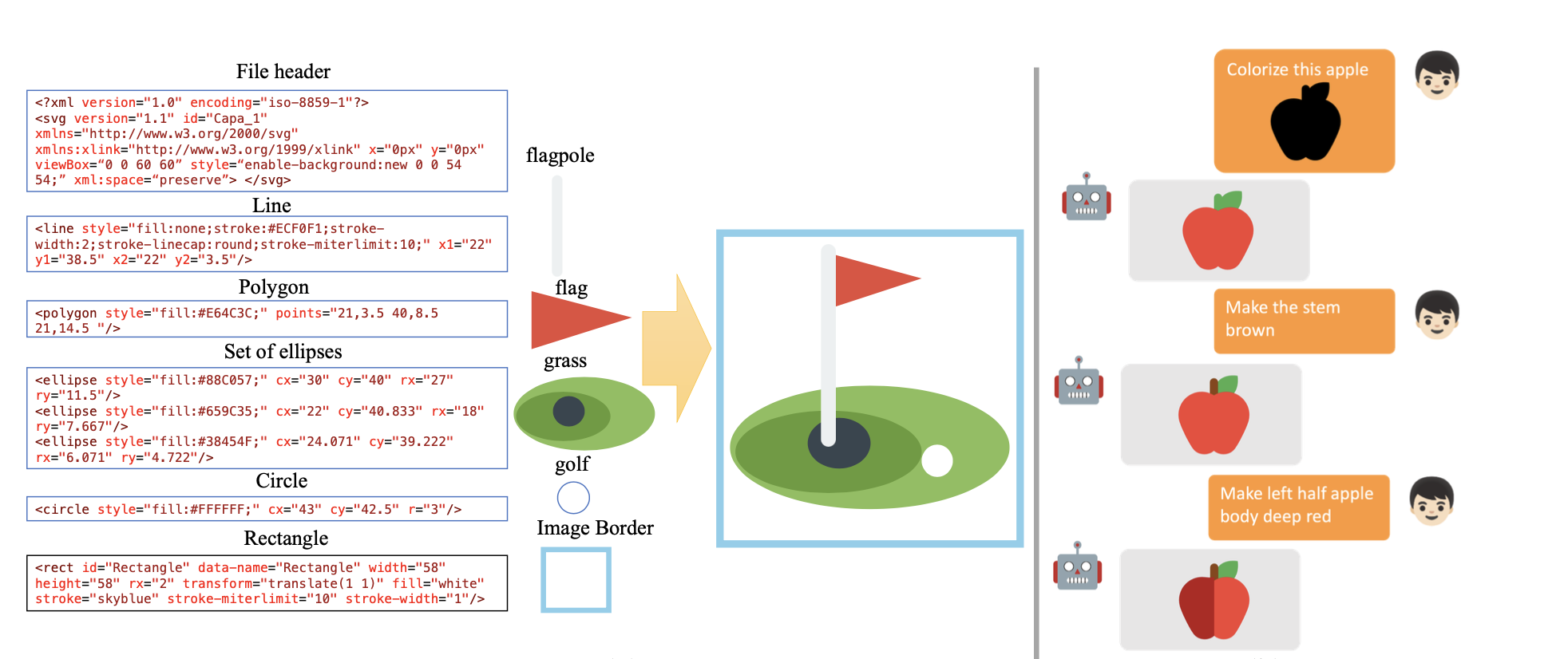
Mu Cai*, Zeyi Huang*, Yuheng Li, Haohan Wang, and Yong Jae Lee
WACV, 2025
(*equal contribution)
[arXiv] [code]
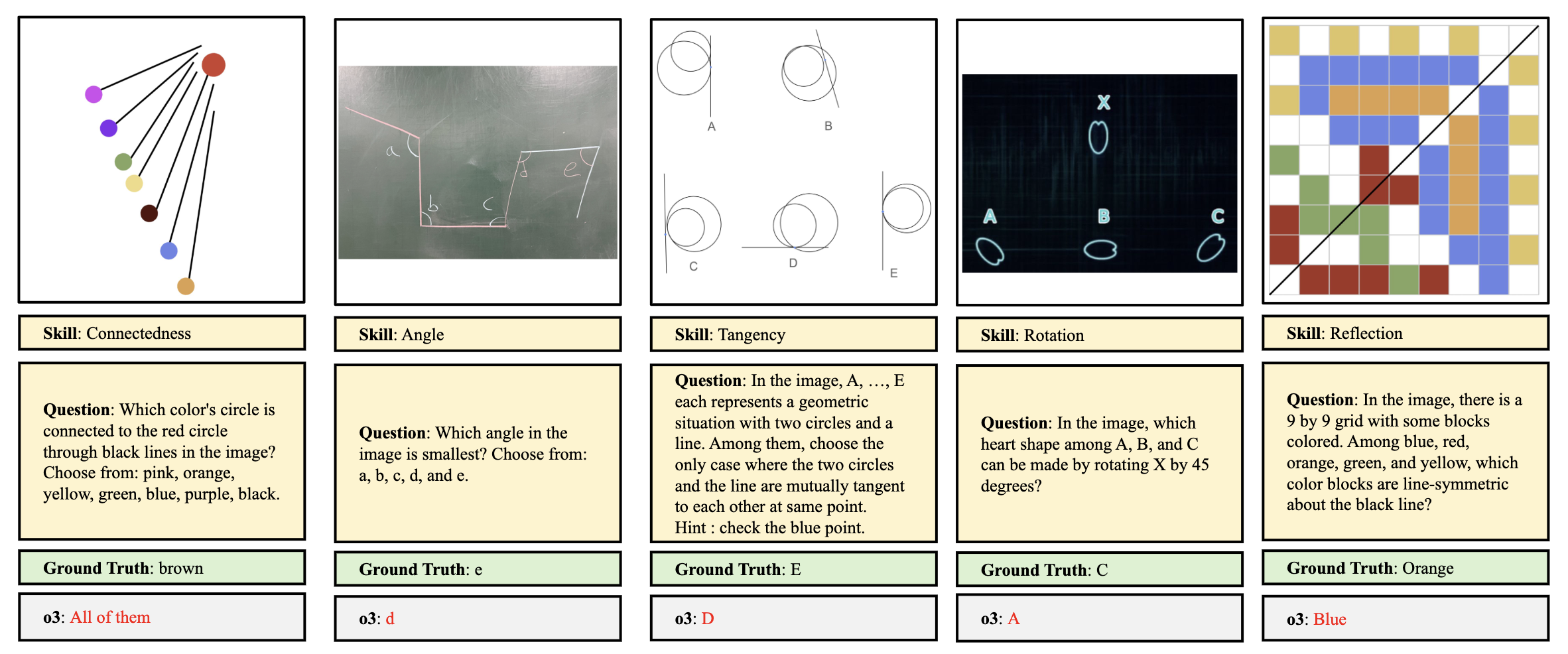
Hyunsik Chae, Seungwoo Yoon, Jaden Park, Chloe Yewon Chun, Yongin Cho, Mu Cai, Yong Jae Lee, Ernest K. Ryu
arXiv, 2025
[arXiv] [code]

Jianrui Zhang*, Mu Cai*, Yong Jae Lee
arXiv, 2024 [Accepted by NeurIPS 2025 D&B Track AC, rejected by PC]
(*equal contribution)
[arXiv] [Project Page] [Code] [Datasets] [Leaderboard]

Bocheng Zou*, Mu Cai*, Jianrui Zhang, Yong Jae Lee
EMNLP main, 2024
[arXiv] [code] [Project Page] [Dataset]

Shubham Bharti, Shiyun Cheng, Jihyun Rho, Jianrui Zhang, Mu Cai, Yong Jae Lee, Martina Rau, Xiaojin Zhu
arXiv, 2024
[arXiv]
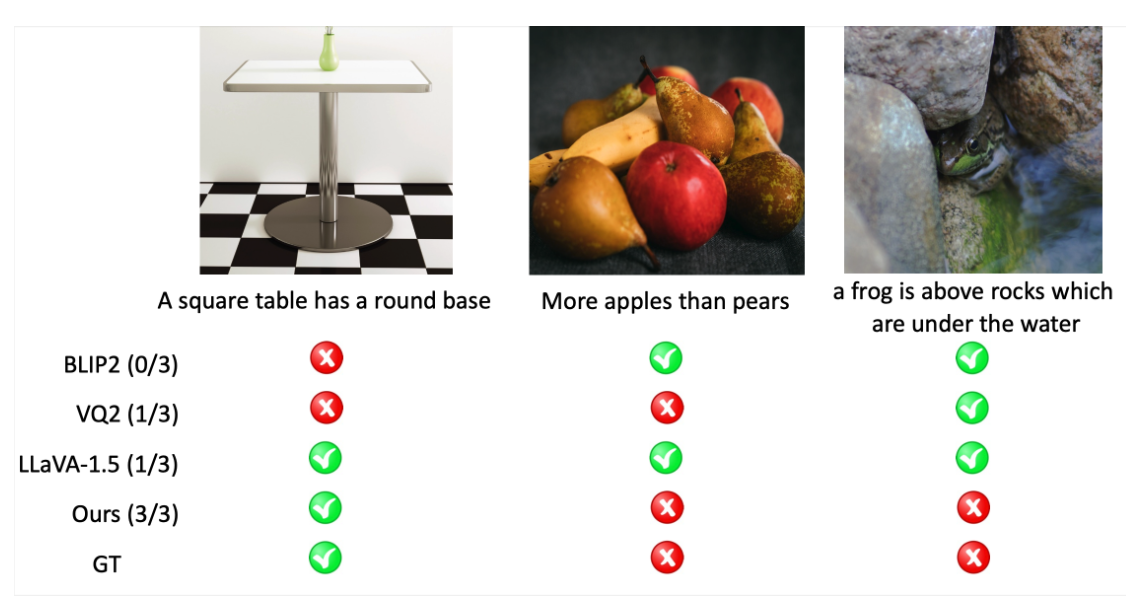
Yuheng Li, Haotian Liu, Mu Cai, Yijun Li , Eli Shechtman, Zhe Lin, Yong Jae Lee, and Krishna Kumar Singh
Proceedings of the European Conference on Computer Vision (ECCV), 2024
[arXiv] [code] [Project Page]
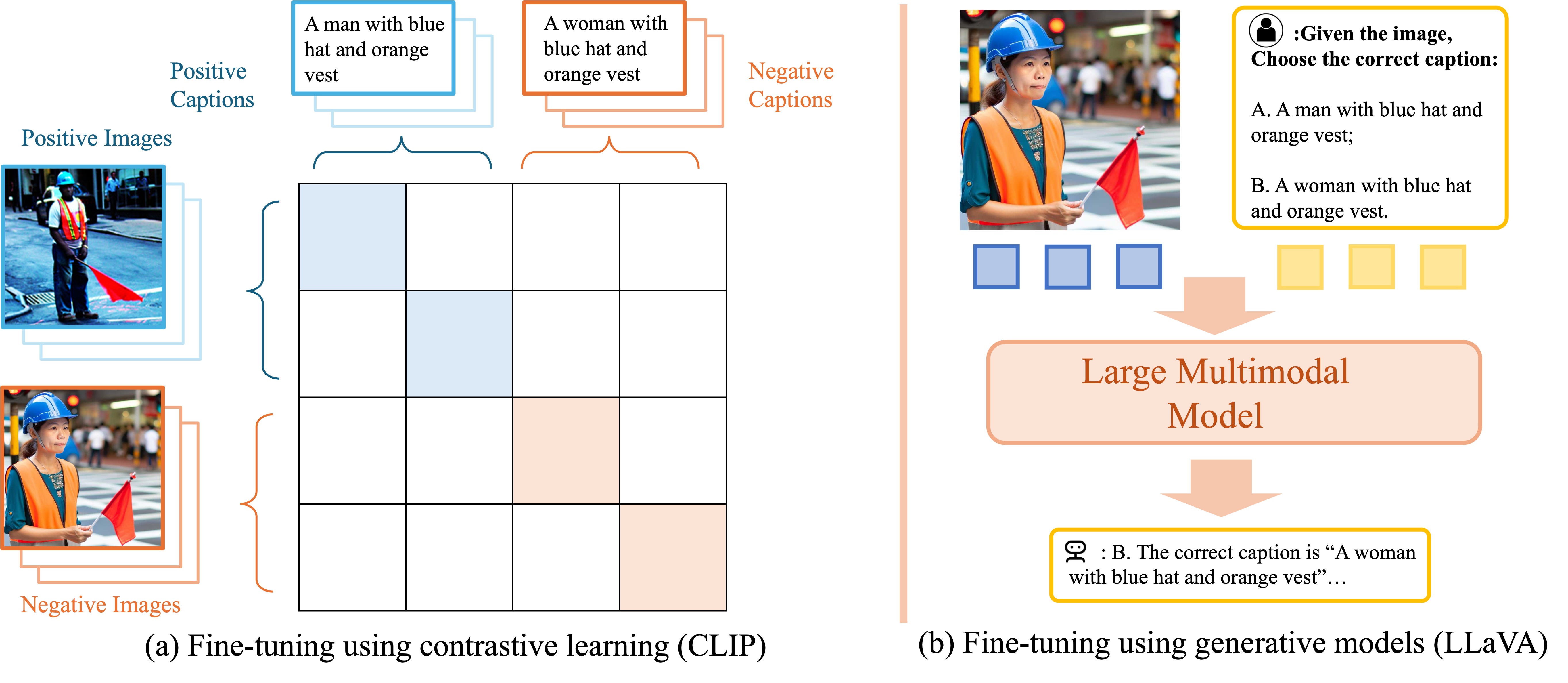
Jianrui Zhang*, Mu Cai*, Tengyang Xie, Yong Jae Lee
Findings of the Association for Computational Linguistics: ACL Findings 2024
(*equal contribution)
[arXiv] [code] [Project Page]

Mu Cai, Chenxu Luo, Yongjae Lee, and Xiaodong Yang
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024
[arXiv] [code] [Youtube video]

Thao Nguyen, Haotian Liu, Yuheng Li, Mu Cai, Utkarsh Ojha, Yong Jae Lee
NeurIPS, 2024
[arXiv] [code] [Project Page]
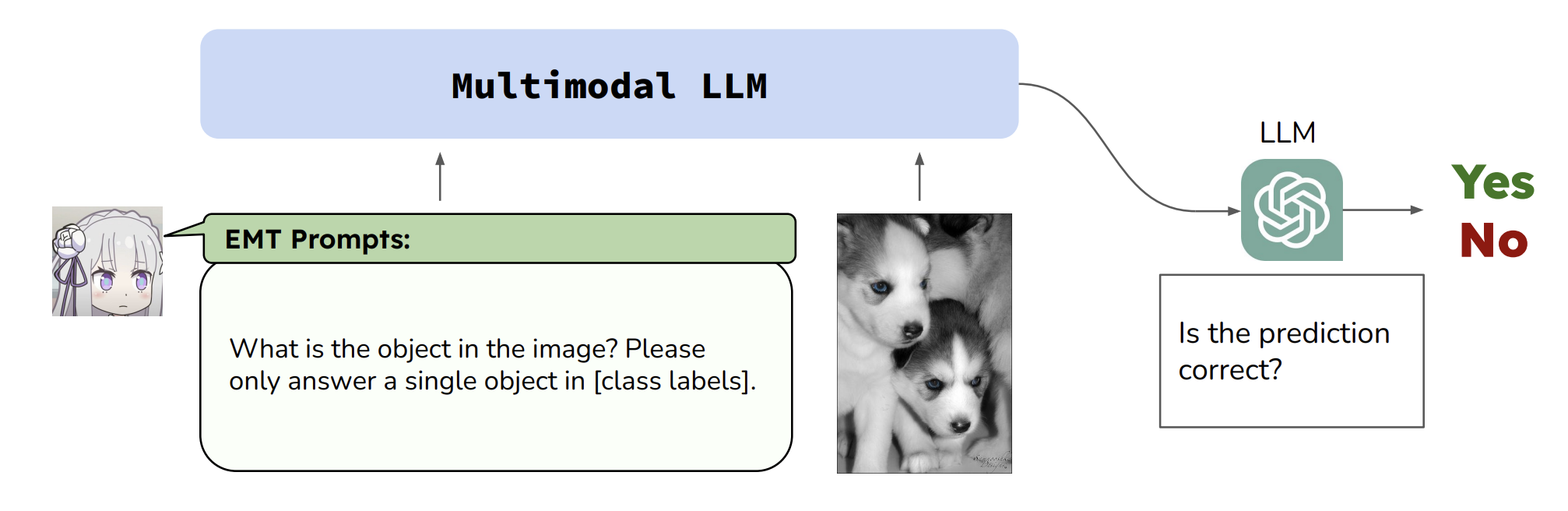
Yuexiang Zhai, Shengbang Tong, Xiao Li, Mu Cai, Qing Qu, Yong Jae Lee, Yi Ma
Conference on Parsimony and Learning (Proceedings Track) (CPAL), 2023
[arXiv]

Zeyi Huang, Andy Zhou, Zijian Ling, Mu Cai, Haohan Wang, and Yong Jae Lee
Proceedings of International Conference on Computer Vision (ICCV), 2023
[arXiv]
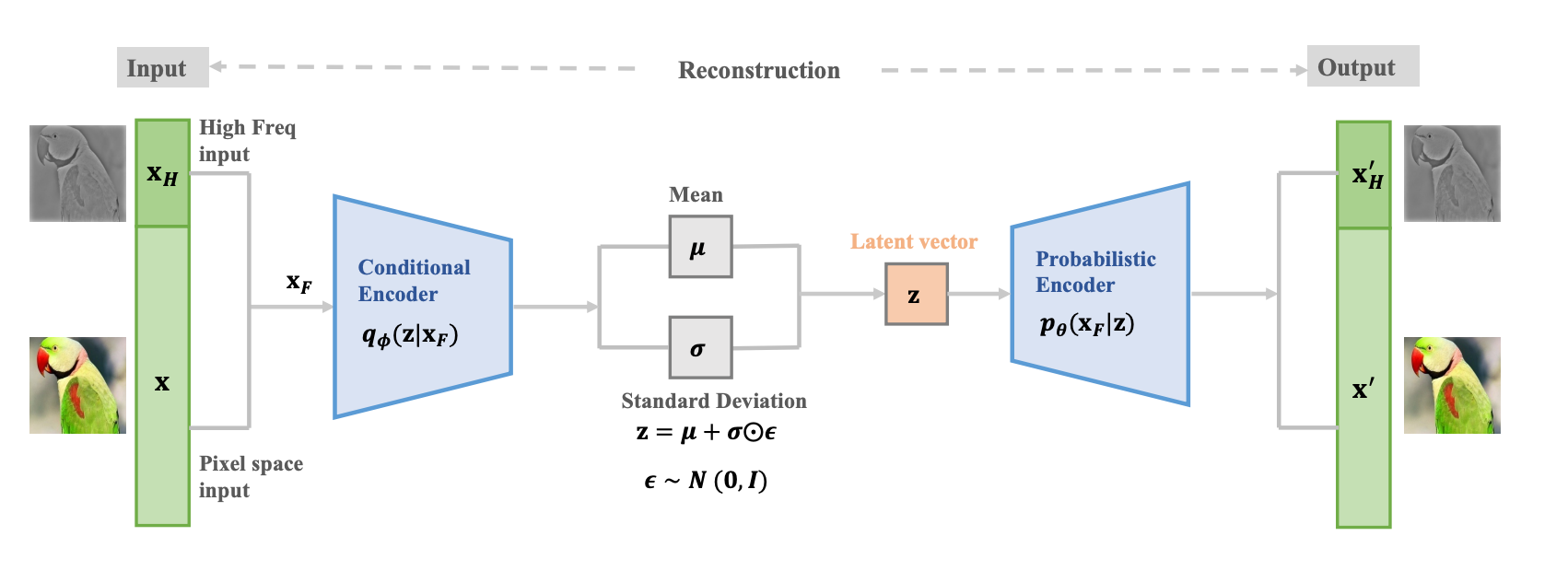
Mu Cai, and Yixuan Li
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023 (Spotlight)
[arXiv] [code] [Youtube]
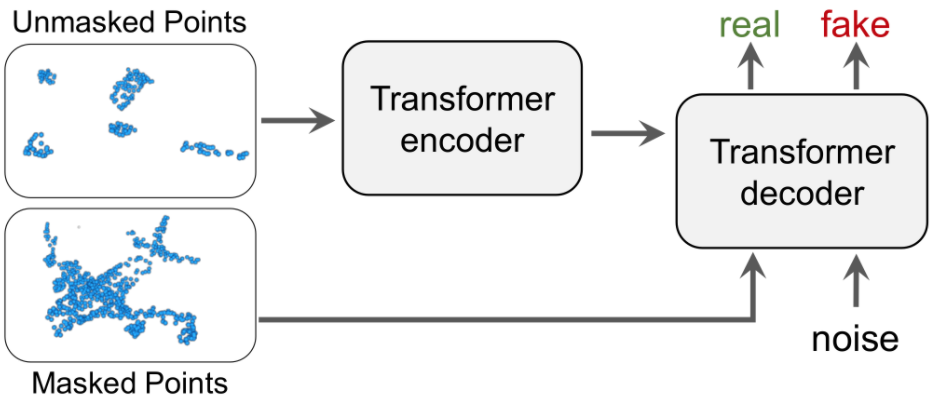
Haotian Liu, Mu Cai, and Yong Jae Lee
Proceedings of the European Conference on Computer Vision (ECCV), 2022
[arXiv] [code] [talk]

Xuefeng Du, Zhaoning Wang, Mu Cai, and Yixuan Li
Proceedings of the International Conference on Learning Representations (ICLR), 2022
[arXiv] [code]

Mu Cai, Hong Zhang, Huijuan Huang, Qichuan Geng, Yixuan Li, and Gao Huang
In Proceedings of International Conference on Computer Vision (ICCV), 2021
[arXiv] [code]
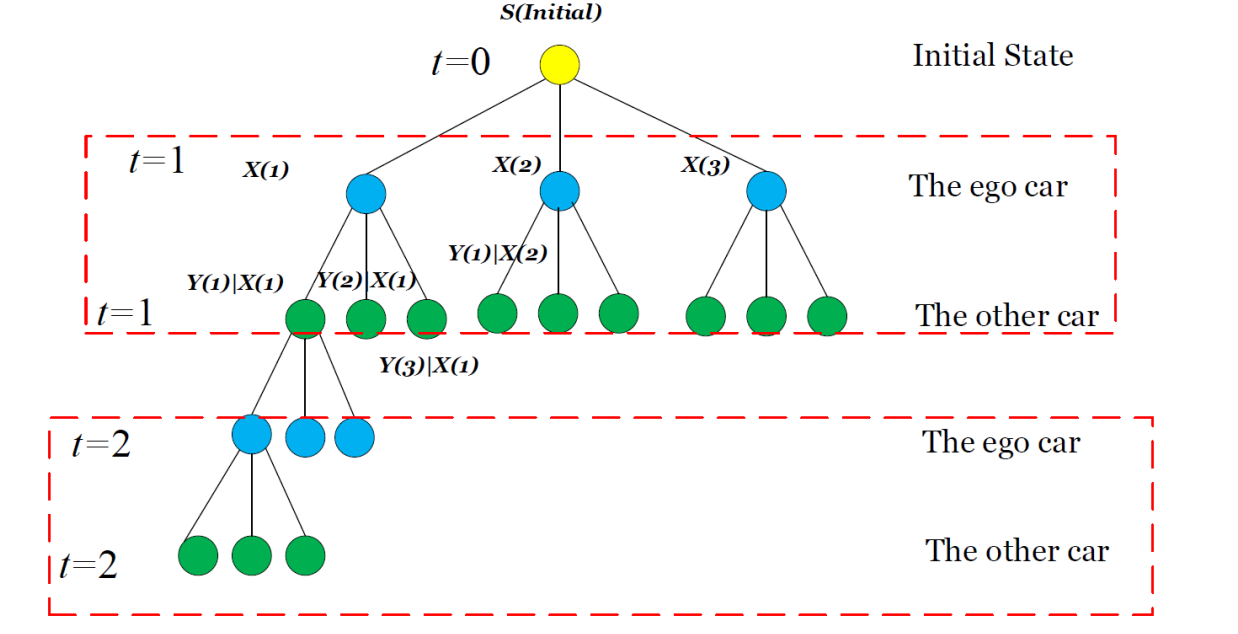
Liting Sun*, Mu Cai*, Wei Zhan, and Masayoshi Tomizuka
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2020
(*equal contribution)
[PDF]