


Next: Problem formulation
Up: Document Recovery from Bag-of-Word
Previous: Introduction
Related work
In the NLP domain, there has been a great deal of research on hypothesis rescoring.
In statistical machine translation (SMT), various decoding strategies have been explored [Knight1999,Germann2003],
including
traveling salesman formulation [Germann

2001],
beam search [Hoang and Koehn2008,Crego
2005], and
A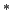 search [Och
search [Och
2001].
Automatic speech recognition (ASR) systems also employ rescoring mechanisms, such as the ROVER system [Fiscus1997].
Athanaselis et al. athanaselis06 use language model to search for reorderings of words in the context of automatic grammar checking.
Our work differs from all of the above in that we already know (at least some of) the words that must appear in the recovered document. While this may appear to simplify the problem, our problem may in fact be harder.
In SMT, the set of possible permutations of target words is constrained based on the ordered source language document [Kanthak
2005,Bangalore
2007].
We lack such constraints in our task. We also consider decoding indicator vectors and vectors with stopwords removed, where we must decide how many additional words to introduce without the guide of a source document.
The current work shares commonality with data mining and security research that attempts to recover hidden knowledge from published sources.
Staddon et al. Staddon07 study what inferences can be made when newly published data is combined with existing information on the Web.
David Naccache and Claire Whelan demoed software at Eurocrypt 2004 that predicted redacted words in a White House briefing regarding September 11.
Although different than our notion of document recovery, these work also address questions of privacy leakage from obscured or modified text.
Perhaps the closest work is Zhu et al. Zhu2008Learning, which showed that using only a large set of BOW vectors, an adversary can learn a simple bigram model and recover simple documents. In that paper, no external language resources were used. Instead, we use the state-of-the-art Google Web 1T 5-gram collection to provide a rich source of background knowledge for decoding BOW documents.
Next: Problem formulation
Up: Document Recovery from Bag-of-Word
Previous: Introduction
Nathanael Fillmore
2008-07-18