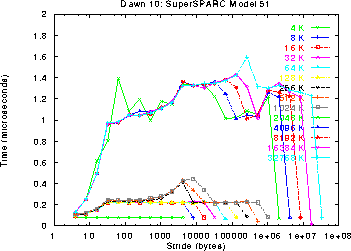
The Dual SS-51 processors are similar to the Single SS-51, in that they have the same first and second level cache structure. However, the TLB structure differs and the access time to main memory increases from 1.4 us to 1.6 - 1.9 us. (The last point in the graph does not return to the first level cache hit time like the Single SS-51 graph because the benchmark version used to produce these graphs does not access the array when the stride is equal to the array size.)
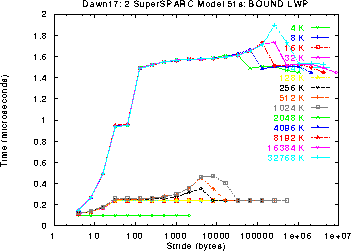
We also examine the effects of memory contention in the Dual SS-51
processors. The micro-benchmark was modified so that a process bound to
the second processor repeatedly modifies uncached data locations while the
first process runs the original micro-benchmark. This memory contention
increases the worst-case cost of accessing main memory from 1.9 us to 2.5
us.
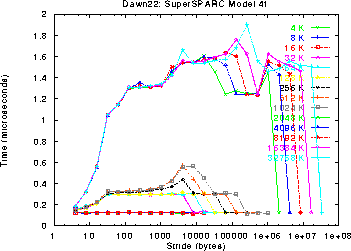
The Single SS-41 reveals a four-way associative 16K first level cache and a
direct-mapped 1MB second level cache. The access time of the second level
cache is near 0.3 us, while the main memory access time is between 1 and
1.8 us.
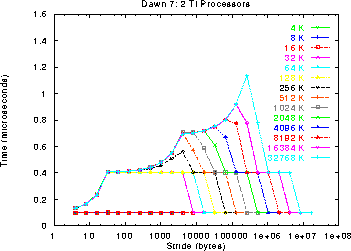
Finally, the Dual TI processors contain the most dramatic differences
compared to the other platforms. These graphs reveal a 16KB, 4-way
associative first level cache. The main memory access time is improved
dramatically, down to 0.4 us - 1.2 us, but at the cost of removing the second
level cache.
Once again, we examined the impact of memory contention in this dual
processor configuration on the main memory access time. This graph shows
that the common case access time increases from 0.4 us to nearly 1.0 us and
the peak of the curve increases from 1.2 us to 2.1 us.
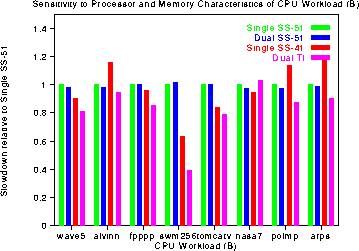
On the other hand, swm256 runs in 2/5th of the time on the Dual TI
and 3/5th of the time on the Single SS-41, compared to the base Single
SS-51 case. Since these two platforms both have a 16K first level cache
instead of a 4K first level cache, our conclusion is that swm256 has
a working set between 4 and 16 K.


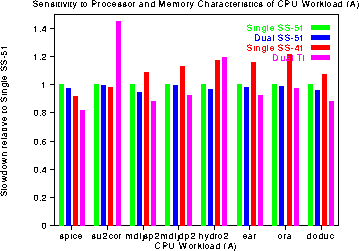
CPU Workload
In the following two graphs, the execution time of each CPU Workload script
is normalized to the time on a Single SS-51 processor. For most
applications, the performance difference across workstations is in the
range of 20%. The most striking
differences in performance occur for the su2cor and the swm256 user
workloads. In the case of su2cor, the performance on Dual TI is 40%
slower than on the the Single SS-51, the
Dual SS-51, or the Single SS-41. Our hypothesis
hypothesis for this large performance difference is that su2cor has a
working set that fits in the 1MB second level hit.
Interactive Workload
The performance of the interactive workload is less sensitive to the
processor model than the CPU workload for two reasons. First, the
interactive workload contains segments simulating user typing; these
segments do not stress the CPU and perform the same on all platforms.
Second, the working sets of the programs tend to be small and so do not
stress the differences in the memory hierarchy.


 Back to Top-Level
Back to Top-Level