
Clearly, workloads which saw no advantage from
optimal parallelism, perform no worse when a less than optimal allocation
strategy is used. However, workloads such as su2cor, mdljsp2, mdljdp2, and
polmp, which contain between 3 and 6 jobs and saw speedups between 1.5 and
2.5, are sensitive to the allocation strategy when there are only two
workstations. This sensitivity occurs because those workloads had large
variations in the run times in the order that the user submitted those
jobs. As we increase to 4 jobs, the allocation becomes more load-balanced;
when as many workstations are available as parallel jobs, the fcfs
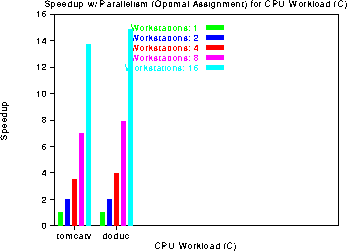
allocation strategy is identical to the optimal case. The doduc workload
is the only workload that sees a difference in performance between the fcfs
and the optimal policies with a large number of workstations, due to its
very large number of runs.

I/O Workload
The I/O workload contains less parallelism than the CPU Workload because
dependencies exist between many of the applications. The two exceptions
are the runs of sim which have no dependencies. In these cases,
we see best-case speed-ups of 5 (smaller runs) and 3 (longer runs).

Development Workload
Finally, the development workload is able to take advantage of parallelism
when compiling a large number of files. (Note that not all development
workloads are shown; we did not explicitly expose the parallelism in the
makes for the some of the workloads.)

FCFS Allocation
We also examine the effects of assigning jobs in the order that the user
submitted them to the system to workstations. In these graphs, we only
look at the CPU Workload.



 Back to Top-Level
Back to Top-Level