Project 4: Intro to ThreadsImportant DatesQuestions about the project? Send them to Due: Thursday, 3/25, by 9pm. Clarifications
03/21: Don't worry about handling non-unique keys -- that is the user's problem NotesThis project can be done with a partner. So work with one! But, you don't have to. That said, if you can't find a partner, but want one, send me mail by the end of the weekend. OverviewIn this project, you will be getting a feel for threads, locks, and performance. The first entity you will build is called a spin lock. A spin lock uses some kind of powerful hardware instruction in order to provide mutual exclusion among threads. You may of even heard of spin locks, say in class or something. Part 1: Spin LocksTo build a spin lock, you will use the x86 exchange primitive. As this is an assembly instruction, you will need be able to call it from C. Fortunately, gcc conveniently lets you do this without too much trouble: xchg.c For those interested in learning more about calling assembly from C with gcc, see here. To learn more about this instruction, you should read about it in the Intel assembly instruction manual found here. However, I bet you can figure it out without looking. The lock you build should define a
xchg code above as needed to build your
spin lock.
Part 2: Using Your LockNext, you will use your spinlock to build three concurrent data structures. The three data structures you will build are a thread-safe counter, list, and hash table. To build the counter, you should implement the following code:
libcounter.so
To build the list, you should implement the following routines:
list_t should
contain whatever is needed to manage the list (including a lock). Don't do
anything fancy; just a simple insert-at-head list would be fine. This library
will be called liblist.so
To build the hash table, you should implement the following code:
libhash.so
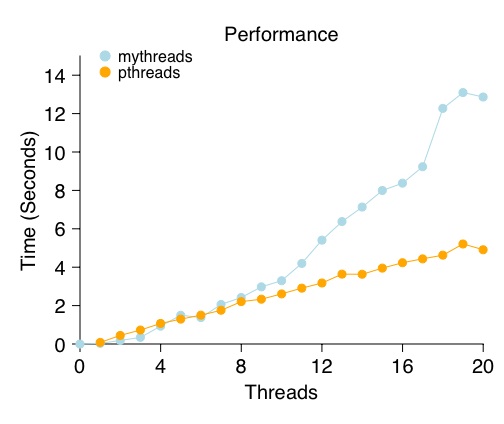
The hash table should simply use one list per bucket. How can you make sure to allow as much concurrency as possible during accesses to the hash table? Part 3: Comparing PerformanceFinally, you will do some performance comparisons. Specifically, you will compare the performance of your spin lock versus the performance of pthread locks . You will do this for each of your data structures (counter, list, hash table). Along the x-axis of each graph, you will vary the number of threads contending for the data structure. The y-axis will plot how long it took all of the threads to finish running. The output of the comparison will be a graph, which might look like this:
This graph plots the average performance of many threads updating a shared
counter, as in the following code that each thread would call
For this experiment, Similar plots should be made for:
Timing should be done with To make your graph less noisy, you will have to run multiple iterations, as well as to make sure to let each experiment run long enough so as to be meaningful. You might then plot the average (as done above) and even a standard deviation or 95% confidence interval. A little statistics can go a long way... BonusYou might not be happy with the performance of your simple spin lock. If
so, you should look into using the Linux Handing It InThis is p4. I bet you know how to turn stuff in by now, no? Do make sure your Makefile builds each of the libraries (counter, hash, and list) and uses your own lock. The one thing that is different: you should turn in the code into both partners handin directories (which makes grading easier). |