Abstract
Multimodal LLMs claim to jointly process text, audio, and video, but accuracy alone hides which modality the answer actually came from. We extend the AVUT benchmark with a counterfactual-ablation framework that asks not only "did the model get the answer right?" but "does removing the modality the model says it relied on actually change the answer?"
Across Qwen2.5-Omni-7B (1,443 samples) and Gemma-3n-E2B-IT (600 samples), the model's self-reported modality attribution is reliable on pure-audio tasks (AFS 0.57–0.78) but falls to or below chance on cross-modal binding tasks (AFS 0.31–0.50). Gemma's overall AFS sits at 0.494 — essentially a coin flip. Adversarial transcript injection (TOR-flip = 0.69 on Qwen) abandons the correct audio-visual answer seven times out of ten, with 81% of flips directed at the attacker's intended option. The qualitative pattern survives a 3.5× model-size change, suggesting these failures are properties of the omnimodal architecture family, not artifacts of one model.
Code: PranavAvadhanam/proj-multimodal · samadasyed/omnimodel-research · jjwang8/639_avut
Headline numbers
Three numbers from three different probes. Self-attribution is unreliable, adversarial text dominates, but incidental lexical contradiction is survivable.
Key Insight
Prior work on lexical bias (Chen et al., 2025) showed that audio-LLMs over-rely on transcribed words rather than acoustic cues. We adapt this counterfactual logic from audio-only to omnimodal Video-LLMs, and extend it from "is the model using modality X" to "does the model know whether it is using modality X".
Behavioral attribution
What the model's behavior under ablation reveals it actually used — flip rates, confidence drops, accuracy deltas when a modality is removed.
Verbal attribution
What the model says it used when explicitly asked which modality drove its answer (Stage S6 attribution probe).
The gap between (a) behavioral and (b) verbal attribution is the core methodological contribution. Attribution Faithfulness Score (AFS) quantifies this gap on a per-task basis, restricted to falsifiable cases where ablation could in principle change the answer.
Method
Seven-stage ablation pipeline
Each AVUT question is presented to the same omnimodal model in seven configurations. Cross-stage comparisons turn into diagnostic metrics.
| Stage | Inputs | Purpose |
|---|---|---|
| S1 | Question + options only (Qwen2.5-1.5B-Instruct) | Text-shortcut floor |
| S2 | Audio + question | Audio-only |
| S3 | Video frames + question | Visual-only |
| S4 | Audio + video + question | Reference full-AV condition |
| S5 | S4 + matched ASR transcript | Matched transcript injection |
| S6 | S4 + raw response + "Which modality did you use?" | Self-reported attribution |
| S7 | S4 + transcript from a different same-task video | Lexical override probe (Gemma) |
The 600-sample Gemma run and the 1,443-sample Qwen run share the same Whisper transcripts and the same mismatched-transcript pairings, so every cross-model cell is directly comparable.
Three diagnostic metrics combine the stages
AFS
For each S6 case where the model's self-reported #1 modality is falsifiable, check whether ablating that modality flips the answer. AFS = 1.0 is perfect; AFS = 0.5 is chance.
LOR / TOR
Of S4-correct questions, what fraction flip when a contradictory transcript is injected? LOR uses a real same-task transcript; TOR uses a GPT-4o-generated adversarial transcript anchored at a wrong option.
TIB
Transcript Injection Bias = Acc(S4) − Acc(S5). Negative TIB means matched transcripts help; positive means they hurt.
We additionally report per-stage Expected Calibration Error (ECE) and ΔConfidence (the drop in self-reported confidence when a modality is removed) as exploratory signals on verbal-vs-behavioral attribution.
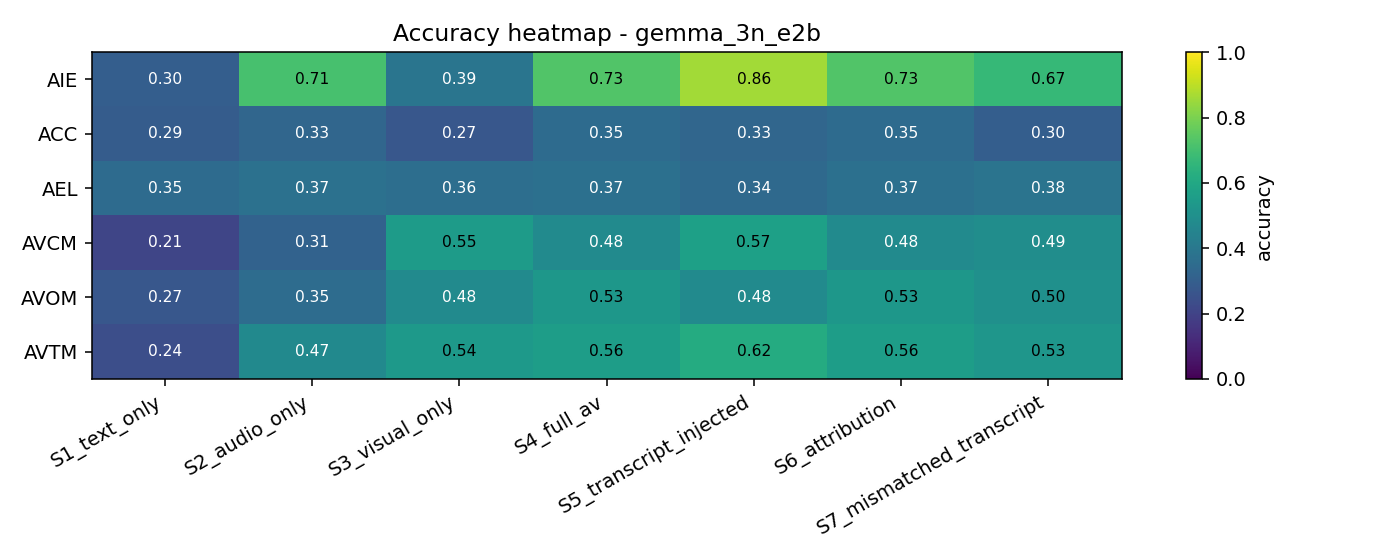
Cross-model accuracy
Overall accuracy by stage on the same 600 questions, Qwen vs Gemma.
| Stage | Gemma-3n-E2B-IT | Qwen2.5-Omni-7B | Δ (Qwen − Gemma) |
|---|---|---|---|
| S1 text-only | 0.277 | 0.289 | +0.012 |
| S2 audio-only | 0.427 | 0.499 | +0.072 |
| S3 visual-only | 0.431 | 0.495 | +0.064 |
| S4 full AV | 0.503 | 0.591 | +0.088 |
| S5 + matched transcript | 0.533 | 0.624 | +0.091 |
| S6 attribution follow-up | 0.503 | 0.591 | +0.088 |
| S7 + mismatched transcript | 0.478 | — | — |
Qwen-Omni-7B uniformly outperforms Gemma-3n-E2B by 7–9 pp across all stages — consistent with the 3.5× parameter gap — but the qualitative shape is identical: single-modality near-tie, full-AV gain, transcript helps, S6 ≈ S4.
Attribution faithfulness splits cleanly by task family
Both models confabulate at the same task boundary: pure-audio tasks (AIE, ACC, AEL) score above chance; cross-modal binding tasks (AVCM, AVOM, AVTM) sit at or below chance.
| Task | AFS (Gemma) | AFS (Qwen) | Δ |
|---|---|---|---|
| Audio Information Extraction (AIE) | 0.70 | 0.78 | +0.08 |
| Audio Content Counting (ACC) | 0.66 | 0.71 | +0.05 |
| Audio Event Location (AEL) | 0.63 | 0.57 | −0.06 |
| Audio OCR Matching (AVTM) | 0.40 | 0.43 | +0.03 |
| Audio Character Matching (AVCM) | 0.35 | 0.41 | +0.06 |
| Audio Object Matching (AVOM) | 0.31 | 0.50 | +0.19 |
| Overall | 0.494 | — | — |
The largest cross-model gap is on AVOM. Smaller models confabulate more on cross-modal binding, suggesting whatever capacity supports faithful self-attribution scales with model size — but the failure mode itself is shared.
Adversarial text injection: catastrophic override
For each AVUT question with substantial speech content, GPT-4o generates a short adversarial transcript anchored at one of the three wrong options. The transcript is injected alongside the unmodified audio and video. The audio and video continue to support the correct answer throughout — only the text channel is poisoned.
A model that truly integrated all three channels in a load-bearing way should produce a TOR-flip near zero — even when text contradicts, two of three channels still point at the correct answer. The observed TOR-flip of 0.69 is a direct demonstration of modality bias toward text. The steered fraction of 0.81 (uniform 0.78–0.82 across tasks) shows that flips are not random thrashing; the model is reliably pulled toward whatever option the injection points at.
Verbal vs. behavioral attribution gap
Although Gemma's verbalized self-attribution is unreliable (AFS = 0.49), its confidence drops under ablation are calibrated correctly.
| Task | ΔConf (audio removal) | ΔConf (visual removal) |
|---|---|---|
| Audio Information Extraction | +6.79 | −0.01 |
| Audio Content Counting | +3.38 | −1.36 |
| Audio Event Location | +2.70 | −1.30 |
| Audio Character Matching | +1.85 | −0.25 |
| Audio Object Matching | +2.55 | −0.55 |
| Audio OCR Matching | +2.55 | +0.15 |
Removing audio drops confidence by 1.85–6.79 pp; removing visual barely moves confidence at all. The model's behavior tracks audio's importance correctly — even when its verbal description of that importance is wrong half the time. This suggests the model's internal modality routing is fine; the layer that describes the routing is the broken one.
The headline LOR result reinforces this nuance. On same-task mismatched transcripts (incidental contradiction), Gemma's LOR sits at 0.163 — 84% of audio-correct answers survive. On adversarial GPT-4o-generated transcripts (intentional contradiction), Qwen's TOR-flip is 0.69. Modern omnimodal models appear robust to incidental lexical noise but remain vulnerable to targeted text-channel attacks.
Modality importance ablation on MUStARD++
A separate experiment on the MUStARD++ sarcasm benchmark using Qwen2.5-Omni-7B per-modality descriptions fed to a final Yes/No gate. The descriptions are pre-generated; only which descriptions reach the gate is varied.
| Gate input | Accuracy | F1 | Sarcasm recall | Yes-rate |
|---|---|---|---|---|
| Text-only baseline (Qwen-1.5B, no description) | 57.0% | 47.1% | 38.3% | 31.3% |
| Text description only | 58.6% | 54.5% | 49.6% | 41.0% |
| Video description only | 58.3% | 49.5% | 40.9% | 32.6% |
| Audio description only | 59.1% | 67.1% | 83.5% | 74.3% |
| Audio + text descriptions | 61.9% | 65.3% | — | 60.0% |
| Video + text descriptions | 61.9% | 63.0% | — | 53.0% |
| Fused video + audio + text (S3 baseline) | 63.9% | 69.9% | 83.8% | 69.9% |
Single-modality accuracy is essentially flat (58.3–59.1%) but the audio-only channel has more than 2× the sarcasm recall of text or video. This is consistent with audio carrying the strongest sarcasm signal — yet inspection of the saved audio descriptions reveals modality leakage: when asked to describe "only audio," Qwen-Omni still reflects spoken words rather than purely prosody. The prompting-only intervention does not produce clean per-modality reasoning.
BibTeX
@misc{avadhanam2026multimodalhallucination,
title = {Evaluating and Addressing Multimodal Hallucination},
author = {Avadhanam, Pranav and Deshpande, Aarya and Malpani, Rishit
and Singh, Gurraj and Singh, Kunal and Syed, Samad
and Varikooty, Vikram and Wang, Jeffrey},
year = {2026},
note = {CS 639 Course Project, University of Wisconsin--Madison},
url = {https://github.com/PranavAvadhanam/proj-multimodal}
}