Processing XML data using a
relational database : Schema-Based XML Storage
In this work, we consider the problem of using a relational
database to store and query XML data in a schema-based fashion. There
are two main parts to this problem:
- Given an XML schema, how do we pick a good relational schema to
store the XML data
- Once we have fixed the relational schema and stored the XML data
in the relations accordingly, given an XML query how do we translate
this query into an equivalent SQL query.
The focus of our work is on the query translation problem. It can be
broadly classified as follows
- Developing query translation algorithms for the case when the XML
Schema and/or the XML query may be recursive.
- Designing algorithms that make better use of the
XML-to-Relational mapping information during the query translation
process.
- Studying the interaction between the two subproblems: choosing a
good relational decomposition for storing the XML data and choosing a
query translation algorithm.
We first briefly describe these three ideas.We then look at XML-to-SQL query
translation in the XML Publishing scenario, where existing relational
data is exported as XML documents.
Recursive Schemas and Recursive
Queries
Though there has been a lot of work on proposing alternative relational
decompositions for XML data, there has not been much work on developing
query translation algorithms.
- For the scenario when the XML schema is recursive, while [STZ+99]
and [ML02] have proposed different ways for mapping recursive XML
schemas into relational tables, there is no published work on
translating XML queries into SQL in such a setting. In a recent study
[Choi02], of the 60 XML schemas analyzed, about 35 of them were
recursive. This indicates that recursive XML schemas are an important
class of XML schemas and query translation algorithms in this domain are
important.
- XML query languages have a descendant operator (//) to specify
ancestor-descendant relationships between two elements. For example, the
query //section//title retrieves all title elements that have a section
ancestor element, which is allowed to occur anywhere in the document.
Notice, how the section element can be at an arbitrary depth in the
document and the title element can, in turn, be at an arbitrary depth
below the section ancestor. We refer to such queries having the
descendant operator (//) as recursive XML queries. There is no direct
equivalent operator in the relational world and, in many cases, this
will have to be translated into a fix-point (recursive) SQL query. Prior
work in the XML storage scenario has not looked at how to translate
recursive XML queries into SQL, even when the XML schema is
non-recursive.
We first present a framework for representing a fairly large class of
XML-to-Relational mappings. To the best of our knowledge, this covers
all the techniques proposed in published literature. We then present a
generic algorithm for translating path expression queries into SQL over
a given XML-to-Relational mapping. Here the XML schema and/or path
expression query may be recursive. Our algorithm is described in detail here.
Some of the interesting issues that arise and are addressed by our work
are as follows:
- How do we translate path expression queries over arbitrary
XML-to-Relational mappings into equivalent SQL queries?
- Is the support for recursion in SQL3 sufficient for supporting
path expression queries over arbitrary XML-to-Relational mapping?
- Are there any issues in the translation process when the XML
schema is non-recursive?
- Does XPath semantics introduce any interesting challenges?
Mapping-aware query translation algorithm
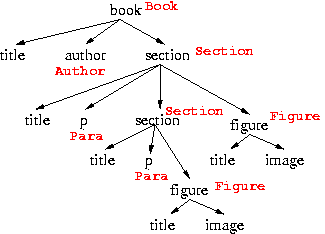
We will use the following example scenario to illustrate what we mean
by mapping-aware query translation algorithms and the necessity for such
algorithms. The XML Schema shown below corresponds to a collection of
XML documents, each of which represent the contents of a book. One
possible way to map this XML data into relations is shown next to the
schema. All the book elements are stored in a Book relation and the corresponding
titles

Book
Author
Section
id
|
parentid
|
parentcode
|
title
|
|
|
|
|
are stored in the title column
of the Book relation.
For each book, the authors of the book are stored in an Author rela tion. The parentid field in the Author relation is a foreignkey to the id field of the Book relation. Using this
key-foreignkey relationship, the parent-child relationship between the
book and author elements is maintained. Similarly, the information about
the sections of a book are stored in a Section
relation. Since, the section element in the XML Schema is recursive, it
means that a section element in an instance XML document may have either
a book parent element (top-level sections in the book) or a section
parent element (nested sections). To keep track of this in the
relational schema, there is an additional column in the Section relation called parentcode - in this case, a value
of 1 in this field indicates a top-level section and a value of 2
indicates a nested section. The relationship between the XML Schema and
the relational schema created to store the XML data can be expressed as
annotations on the XML schema. Some of these annotations are shown in
red in the figure above.
Consider the following query : Retrieve all the Section titles. This
query can be written in XQuery as follows.
Q1:
for $title in document(*)//section/title
return
$title
Notice how both the XML Schema and the XML query are recursive. An
equivalent SQL query would be as follows:
SQ1: with Temp(id,title) as (
select S.id, S.title
from Book B, Section S
where B.id = S.parentid and S.parentcode = 1
union all
select S.id, S.title
from Temp T, Section S
where T.id = S.parentid and S.parentcode = 2
)
select
title
from Temp
This is the relational query output
by the algorithm we developed earlier. Intuitively, our algorithm
matches the query with the schema, identifies the corresponding
matching paths, and issued the root-to-leaf query for these matching
paths. The final query SQ1 corresponds to the matching
book/section*/title path in the XML schema.
Looking at the XML-to-Relational mapping we notice that the following,
much simpler relational query is also a correct translation under
this particular mapping.
MASQ1: select title
from
Section
Why is MASQ1 equivalent to SQ1 and therefore to Q1? For this
particular example, it is due to the fact that there is
only one schema node mapped to Section.title
and all elements corresponding to this schema node were part of the
query result. By looking at the annotations in the XML-to-Relational
mapping, we can get this information and realize that MASQ1 is a correct
translation for Q1. In general, any algorithm that uses the mapping
information to make such observations and remove redundant parts of the
SQL query can be viewed as a mapping-aware algorithm. We have extended
our algorithm for translating path expression queries into SQL to use
the mapping information and eliminate redundant parts of the final SQL
query.
We next give another example queries to illustrate how our
mapping-aware algorithm can generate efficient SQL queries.
Q2:
Retrieve all the top-level
section titles
for $title in document(*)/book/section/title
return
$title
Using a non-mapping-aware algorithm,
the equivalent SQL query will be
SQ2: select S.title
from Book B,
Section S
where B.id = S.parentid and S.parentcode = 1
On the other hand, the output of our mapping-aware algorithm will be
MASQ2: select title
from Section
where
parentcode = 1
Notice how this is an example scenario where the XML schema is
recursive but the XML query is not. We next present a scenario where the
XML query is recursive but the XML schema is not and mapping-aware
techniques are still important. Let us modify the above XML schema to
allow only sections and subsections. The modified schema is shown below.
The same relational decomposition is still valid. Let us assume that we
use the same decomposition.
 Consider the query
Q1 over this schema
Consider the query
Q1 over this schema
One equivalent SQL query will be
SQ2:
select S.title
from Book
B, Section S
where B.id = S.parentid and S.parentcode = 1
union all
select S2.title
from
Book B, Section S1, Section S2
where B.id = S1.parentid and S1.parentcode = 1 and
S1.id = S2.parentid and S2.parentcode = 2
On the other hand, using the mapping information, we can obtain the far
simpler, equivalent SQL query given below.
MASQ1:
select title
from
Section
The above examples show how
mapping-aware query translation can result in far simpler SQL queries.
We have extended our algorithm for translating path expression queries
into SQL to use the mapping information and avoid
redundant computation in the SQL query that is implied by the
XML-to-Relational mapping. We make the following assumptions about the
XML-to-Relational mapping in this case.
- All the XML data
is completely shred into relations and no part of the XML data is stored
multiple times.
- There is no data in the relations other than that which is
present in the XML document.
- Enough information is maintained in the relational data to enable
reconstruction of the original XML data.
We would like to point out the every decomposition scheme we have
encountered in the literature satisfies the above properties.
Are the two subproblems independent?
Recall that there are two main problems in the XML Storage domain: one
is to pick a good relational decomposition and the other is to translate
queries over this XML-to-Relational mapping. Are these two independent
subproblems that can solved in isolation? In this work, we show that
they are not. In fact, the presence of mapping-aware translation
algorithms that make use of the properties of the relational
decomposition indicate that the two subproblems are closely related.
- We show, through experiments with a commercial RDBMS and the
XMark XML benchmark, that there exist query translation algorithms T1
and T2, and relational decompositions D1 and D2, such that for a simple
path expression query, if we use translation algorithm T1, then
decomposition D1 is better than D2, while with translation algorithm T2
decomposition D2 is better than D1. This implies that one cannot talk
about the quality of a decomposition without discussing the query
translation algorithm to be used.
- By examining an interesting problem embedded in choosing a
relational decomposition, we show that choices of different translation
algorithms and cost models result in very different complexities for the
resulting optimization problems. Our results suggest that,
contrary to the trend in previous work, the eventual development of
practical algorithms for finding relational decompositions for XML
workloads will require judicious choices of cost models and translation
algorithms, rather than an exclusive focus on the decomposition problem
in isolation.
More details can be found in the ICDT 2003 paper On the
Difficulty of Finding Optimal Relational Decompositions for XML
Workloads: A Complexity Theoretic Perspective.
Next: XML Publishing
- [STZ+99] Jayavel Shanmugasundaram, Kristin Tufte, Chun
Zhang,Gang He, David J. DeWitt, Jeffrey F. Naughton: Relational
Databases for Querying XML Documents: Limitations and Opportunities.
VLDB 1999: 302-314
- [ML02] Murali Mani, Dongwon Lee: XML to Relational Conversion
Using Theory of Regular Tree Grammars. EEXTT 2002: 81-103
- [Choi02] Byron Choi: What Are Real DTDs Like,
WebDB 2002