Zero Knowledge Proofs
Shrey Shah · February 2020
The concept of being able to prove to someone that you know the correct passcode without them ever knowing the correct passcode seems to hold universal appeal. It is not the common computational paradigm that can hold rapt attention at a dinner party. Thus, this article will be more geared towards developing the intuition behind why and how zero knowledge proofs work (along with some extensions of the regular ZKP) rather than rigorous analysis of the methods described.
Intuition
We first begin by understanding what we want out of any zero knowledge paradigm. All zero knowledge proofs must satisfy 3 properties:
- completeness: if the statement (password) is true, the prover should be able to convince the verifier
- soundness: a malicious (dishonest) prover should not be able convince an honest verifier if the statement is false
- zero knowledge: the verifier should not be able to learn any information other than the fact that the statement is true; that is an outside observer should not be able to tell that the prover knows the true statement
While certain parts of this may seem ridiculously hard and others extremely easy, this semi-formal definition is sufficient for now. We will revisit and come to a greater understanding of these definitions through examples.
Ali Baba’s Cave
We come to a story where Peggy (the prover) is trying to convince Victor (the verifier) that she knows the secret passcode to a door in the middle of Ali Baba’s Cave. She, however, does not want to tell Victor the password and also wants to ensure that no one else will know if she knows the password or not.

Thus, she comes up with a brilliant strategy. She tells Victor to go to the mouth of the cave and look away while she randomly decides to go down one of the two paths of the cave.

Victor then comes into the cave and shouts the side from which he wants Peggy to come out from, at random.
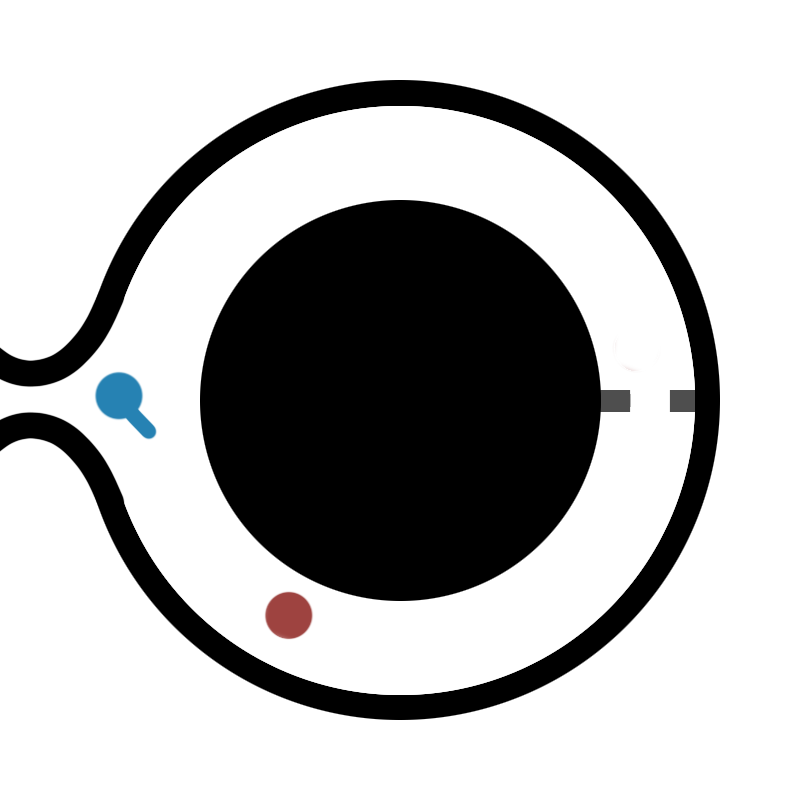
Victor can now be 50% confident that Peggy knows the password, as there is a 50% change that Victor yelled out the side from which Peggy went and she did not need to use the passcode to the door. Victor and Peggy repeat this process \(n\) times, with there being a \(2^{-n}\) chance that Peggy is lying, as each time they repeat the process, Victor can be 50% more sure than the previous trial that Peggy must have known the passcode to have gotten to the correct side.
Now let’s say we come upon a recording of Victor and Peggy going through this entire process to prove that Peggy knows the passcode. We cannot be sure that this recording is not fake. Peggy and Victor could have faked this by agreeing on the sequence of sides Victor would call beforehand, rendering the entire proof worthless to an outside viewer. That is an outside viewer would find it impossible to distinguish between Victor and Peggy faking doing this process and having pre-agreed on the sequence of sides called and Victor and Peggy actually going through this process. As a slight twist, Victor thus must choose the sides in a way that could be fakeable (such as a pseudorandom number generator); he must not choose something that makes it obviously random such as a coin flip, as then the outside viewer could see that the coin flip must be random and thus will know Peggy must know the secret.
That’s it! We have fulfilled the requirements for a zero knowledge paradigm!
I remember when I first read about this, it felt like it shouldn’t work. After all, we are leaving some probability on the table that Peggy will be able to fool Victor with some lucky streak of guesses.
To understand this, let us look at the standard password. As of the writing of this post, most passwords tend to be around 8 characters long, with a combination of numbers, uppercase and lowercase letters, and special characters. Let us be extremely generous and assume that everyone is able to perfectly distribute their passwords and hackers use only brute force guessing to guess someone’s password. It seems impossibly unlikely that someone would be able to simply guess a password like this out of thin air, and indeed it is; the possibility that someone just guesses this password is something like 1 in 6 quadrillion. For the more visually oriented, that is \(\frac{1}{6000000000000000}\). While very large, this is not 0. If we use the same probability as a benchmark, Peggy and Victor only have to do this process 53 times. Indeed, if they want to achieve a higher level of security, let’s say that of a 15 character password (1 in 400 octillion - \(\frac{1}{400000000000000000000000000000}\)), they would do this process 100 times. Let’s assume they are incredibly privacy oriented and want the equivalent of a 20 character passcode (1 in 2 duodecillion - \(\frac{1}{2000000000000000000000000000000000000000}\)); they would only need to do this process 120 times (I realize the zeros get overwhelming, but I want to convey the sheer size of the numbers we are dealing with).
I would be remiss if I did not remind you that that is with the assumption that passwords can only be guessed through brute force (which is wildly far from the truth) and in exchange, we get a zero knowledge protocol, where Victor cannot give out our password (via a password leak or otherwise) even if he wanted to. Furthermore, while 100 iterations of this process may seem like many, computers are fast and this process is relatively inexpensive to carry out. If we wanted to improve this, we could even have a have with many exits rather than just 2. Using a sufficiently complex cave, we would be able to achieve the same result in one
While this example of Ali Baba’s Cave conveys the idea of what a zero knowledge proof is, you can find a crude implementation that you can see how the same concept can be done in code and what each side is doing at each step here.
Non-Interactive Zero Knowledge Proofs
The above techniques are still susceptible to indirect attacks (such as DoS or DDoS), where a malicious user is able to prevent others from using the system (slowloris comes to mind). Let us say we want to prevent against that by ensuring that the verifier and prover do not need to interact during the proof; we would use NIZKs. NIZKs are currently built upon the assumption that \(P \neq NP\).
I will not delve into this discussion, but for the uninformed reader, this is a reasonable assumption to make. Intuitionally, NIZKs work very similar to the above interactive version, but you play both Peggy and (an objective) Victor. How it is possible to ensure objectivity is beyond the scope of this post, but the relevant papers are easy to find and I would be happy to send a more detailed explanation for the curious reader. Thus, we proceed on the above intuition and explore real world use of ZKPs.
zk-SNARKS
zk-SNARKS (Zero-Knowledge Succinct Non-Interactive Argument of Knowledge) was first popularized by Zcash, a cryptocurrency, as part of its optional privacy features. Thus, transactions can be encrypted but still be checked as valid without having to look at the actual transaction details. zk-SNARKS require an initial trusted setup (parameter generation for randomness); Zcash’s initial setup was a relatively elaborate public affair as if people do not believe in the security of the parameter generation, Zcash will not be trusted (à la Dual_EC_DRBG). zk-SNARKS must also be small in size (succinct) and thus are generally one-shot algorithms, where they don’t require many trials and are able to do it in one “trial” (although the terminology falls apart at this level). The soundness is based on the idea of trusting greater computational work (so with a sufficiently complex machine, one could theoretically overcome this). At a very high level, zk-SNARKS works by encoding the problem as a polynomial, homeomorphic encoding to allow the prover to compute the values for the verifier, and a permutation of the values of the encoded schema so that the verifier is able to verify without knowing the initial value (zero knowledge).
zk-STARK
zk-STARK (Zero-Knowledge Succinct Transparent Argument of Knowledge) is quite similar to zk-SNARKS other than the fact that it no longer needs the setup (Transparent). This does, however, come with the downside of a larger proof size. While it does cut down on the main security risk of zk-SNARKS, the larger proof size means that this will probably not get implemented at scale at the current iteration. However, this does look promising for NIZKs, as this paradigm can probably be improved, or else wait for Moore’s Law.
Usage
While this sounds cool, one may ask what use can this have in the real world. Almost any transaction that happens (not just monetary) on the internet can benefit from zero knowledge. Voting is the obvious example that comes to mind, as the votes could be encrypted and vote verification be done through zero knowledge (fulfilling both anonymity and trust requirements). However, almost every application (Tinder, Uber, etc) could implement this to benefit. Even from the most selfish view, companies would be able to access more data as they no longer would be in violation of privacy laws (Secure Multi-Party Computation and Federated Learning) and people would be more willing to share data.
We do see an increasing number of companies and libraries start to understand and implement ZKPs, although it is, at its core, important to understand the intuition behind how the next wave of cryptography that holds your life together works.