Heaps
A heap is a way to implement a priority queue.
The property of a priority queue is:
The highest priority item could be:
For these notes the bigger item has a higher priority.
What are some uses for priority queues:
Why not use an ADT we already know to implement priority queues?
Heaps have same complexity as a balanced search tree but:
A heap is a binary tree that has special structure compared to a general binary tree:
This is easier because we only require property 1 and not the BST properties.
Complete binary tree: parents of all but leaf nodes have 2 children. Leaves can differ in depth by 1 but the smaller depth leaves must be on the right part of the binary tree. The nodes on the bottom level fill from left to right.
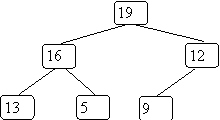
The example from BST as a heap could be:
As with a BST, the location in the heap is not unique. This is a heap with the same values:
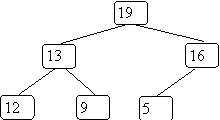
This isn't a heap since it is not complete
How do you add a value to a heap?
If the binary tree is to be complete, some item must wind up in the next location. To begin we place the new item there. The problem is it may be in the wrong place so we have to fix this. Overall you get:
Step 2. lets the item percolate up to its correct location.
Let's insert 14 into our first example:
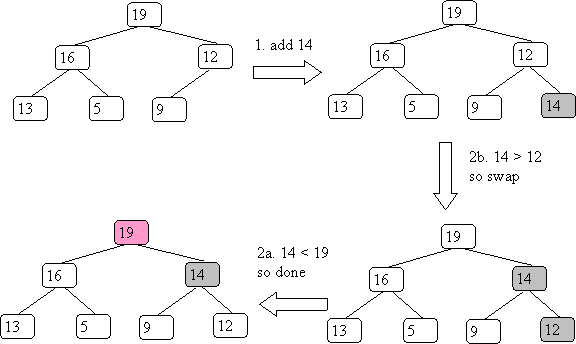
Since the height is log(n), the complexity is worst case O(log(n)). It has been shown that on average you only shift the inserted value 1.6 locations up. Thus, it is O(1) in practice.
How do you remove a value?
Finding the item to remove is easy - it is the root of the tree.
Removing this item destroys the heap structure.
As with insert, we begin by maintaining the complete binary tree structure. Next we fix up the ordering rule for a heap.
The steps are:
Step 3. lets the item percolate down to its correct location.
Continuing our example:
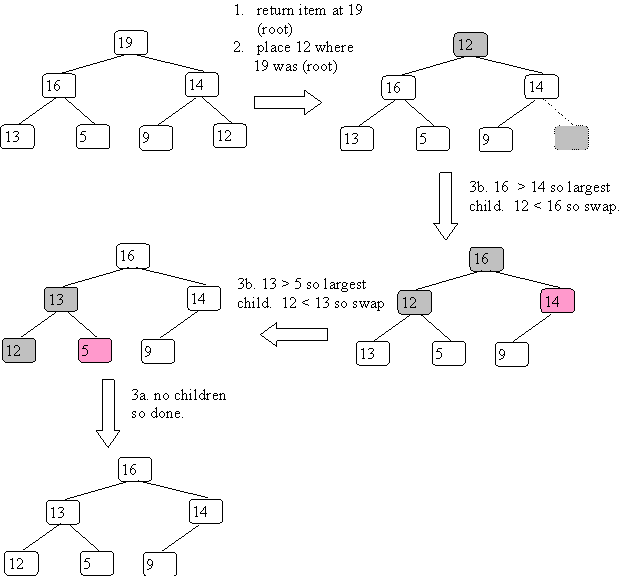
Since the height is log(n), the complexity is O(log(n)). Since you take a value from the bottom, which is small, you generally have to do all log(n) steps.
How should you represent a heap?
When we talked about general trees, we saw two ways to store them:
We needed this generality because the number of children varied.
For a complete binary tree we can easily use an array since you must have 2 children of every node except for leaves and these must at the bottom of the tree.
The storage scheme is simple: you put them in the array starting at index 0 as they occur in a level-order traversal.
Our previous example is:
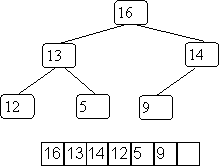
A good question is how do you know what size array to use?
If you know the number of nodes then create an array of that size.
If you don't know the exact number you will have but have an idea of the maximum height you can use:
If the tree grows beyond this you can resize it.
How can you get the tree structure from the array location?
You can tell if the child does not exist by:
To do the inverse operation:
In our example:
The root that has the maximum priority is at index 0.
Why not use this for a general binary tree?
You can have "missing children" in a general binary tree. These represent empty locations (null references) in the array. Using a linked representation can cut down on this (you only need the first null child). Which is better depends on how full the binary tree is.
Heap Sort
If you have values in a heap and remove them one at a time they come out in (reverse) sorted order. Since a heap has worst case complexity of O(log(n)) it can get O(nlog(n)) to remove n value that are sorted.
There are a few areas that we want to make this work well:
If we achieve it all then we have a worst case O(nlog(n)) sort that does not use extra memory. This is the best theoretically for a comparison sort.
The steps of the heap sort algorithm are:
You repeat steps 2 & 3 until you finish all the data.
You could do step 1 by inserting the items one at a time into the heap:
Instead we will enter all values and make it into a heap in one pass.
As with other heap operations, we first make it a complete binary tree and then fix up so the ordering is correct. We have already seen that there is a relationship between a complete binary tree and an array.
Our standard sorting example becomes:
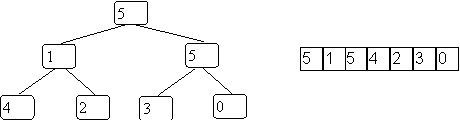
Now we need to get the ordering correct.
It will work by letting the smaller values percolate down the tree.
To make into a heap you use an algorithm that fixes the lower part of the tree and works it way toward the root:
Here is how the example goes:
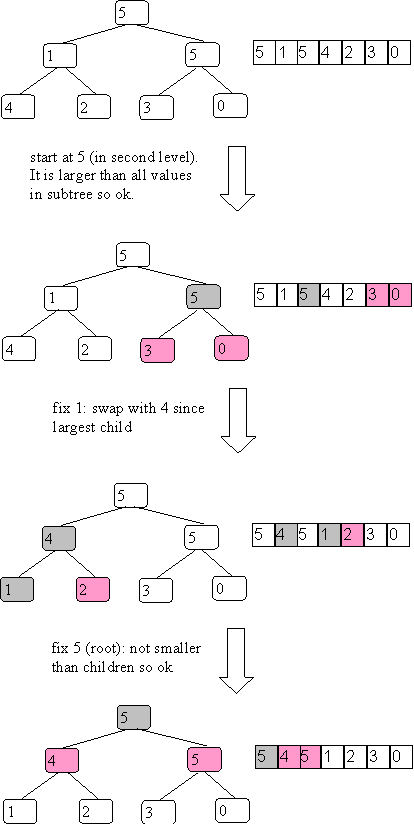
This example has very few swaps. In some cases you have to percolate a value down by swapping it with several children.
The Weiss book has the details to show that this is worst case O(n) complexity. It isn't O(nlog(n)) because each step is log(subtree height currently considering) and most of the nodes root subtrees with a small height. For example, about half the nodes have no children (are leaves).
Now that we have a heap, we just remove the items one after another.
The only new twist here is to keep the removed item in the space of the original array. To do this you swap the largest item (at root) with the last item (lower right in heap). In our example this gives:
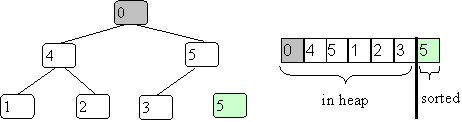
The last value of 5 is no longer in the heap.
Now let the new value at the root percolate down to where it belongs.
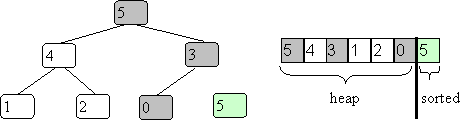
Now repeat with the new root value (just chance it is 5 again):
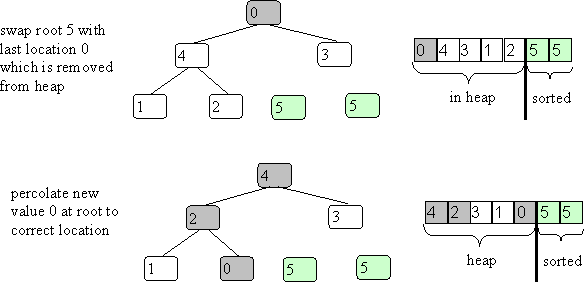
And keep continuing:
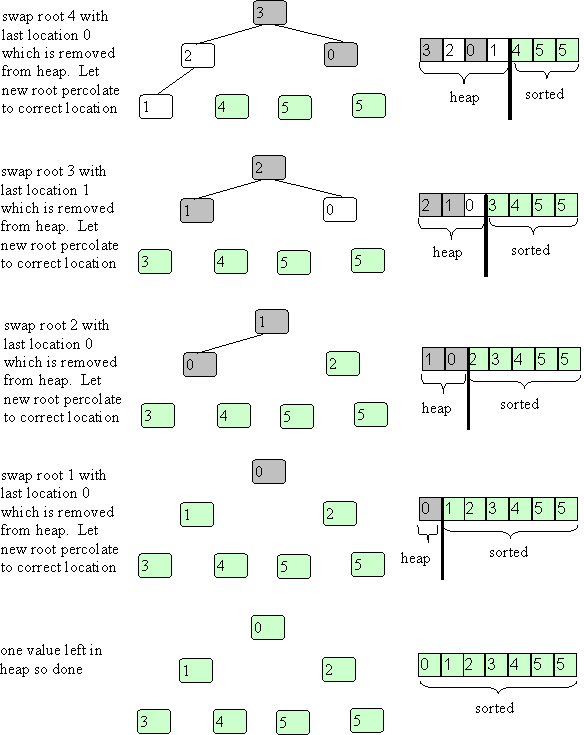
What is the complexity?
The part just shown very similar to removal from a heap which is O(log(n)). You do it n-1 times so it is O(nlog(n)). The last steps are cheaper but for the reverse reason from the building of the heap, most are log(n) so it is O(nlog(n)) overall for this part. The build part was O(n) so it does not dominate. For the whole heap sort you get O(nlog(n)).
There is no extra memory except a few for local temporaries.
Thus, we have finally achieved a comparison sort that uses no extra memory and is O(nlog(n)) in the worst case.
In many cases people still use quick sort because it uses no extra memory and is usually O(nlog(n)). Quick sort runs faster than heap sort in practice. The worst case of O(n2) is not seen in practice.