| allocate: allocate a virtual memory block to use | |
| deallocate: free a virtual memory block allocated before | |
| reallocate: grow or shrink virtual memory allocated before. Tries to return the same address but may also return a new address |
| user process wants to get a (virtual) memory block, e.g., malloc | |
| kernel wants to increase/decrease its memory space |
| User programs keep track of allocated blocks | |||||||||||||||||
| Kernel (memory manager) keeps track of holes (=free blocks) | |||||||||||||||||
Data
structure
|
best
fit: return the smallest hole which is larger than the requested size
|
|||||||
first
fit: return the first hole which is larger than the requested size
|
|||||||
buddy
system
|
| return error, | |
| compaction, or | |
| garbage collection |
procedure
|
|||||||
problems
|
Pointers
to blocks need to be kept track of, but not necessarily - Conservative
garbage collection
|
|||||||||||||||||||||||||||
Algorithms
|
| Virtual address, physical address, MMU | |||||||||||||||||||||||||
Procedure
to translate virtual to physical
|
| A page table for each process | |||||||||
| An entry for each virtual page: valid bit, protection bits, modified bit, ref bit | |||||||||
Challenges
of page table
|
|||||||||
Page
table organization
|
|||||||||
TLB:
Translation Look-aside Buffer
|
Bug
in the program
|
|||
Request
to grow a segment (data segment or stack area) - reference to the just
beyond the end of a process's stack
|
|||
The
requested page is not in memory but in disk
|
| Random | |||||||
FIFO:
kick the oldest page out
|
|||||||
Belady's
MIN: kick the page which will not be used for the longest time in the
future
|
|||||||
LRU:
Least Recently Used - approximate optimum
|
|||||||
NRU:
Not recently used
|
|||||||
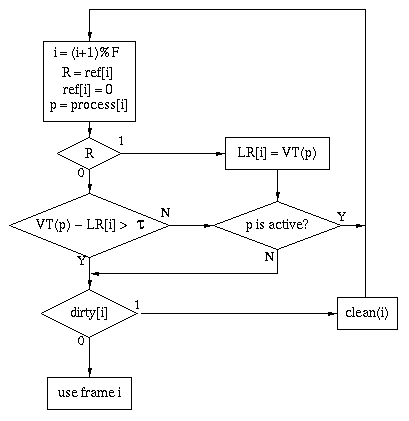
Sampled
LRU: similar to NRU
|
|||||||
Clock
|
|||||||
Belady's
Anomaly
|
The
problems of naive extension of methods for single process
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Working
set model
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Medium-term scheduling (also called load control): swapping out & in to let each runnable process has its working set in memory | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Work
set is just a model. We need algorithms:
|
The
virtue of paging
|
|||||||||||
Segment
goes further. It gives multiple virtual memories, which can:
|
|||||||||||
| Address Space of a process = union of segments | |||||||||||
Unix
Segments
|
|||||||||||
|
Difference between paging and segment |
| paging | segment | |
| size | fixed | variable |
| start addr | multiple of page size | any address |
| physical addr | frame number concate offset | start addr + offset |
| virtual address ->(by segment)-> linear address ->(by paging)-> physical address | |||||||
virtual
address: 16-bit segment selector + 16(or 32)-bit segment offset
|
|||||||
| linear address(32-bit): page number(10-bit) + page number(10-bit) + page offset(12-bit) |
| Capability based addressing | |
| Converting a swap-based system to do paging in an architecture lacking page-referenced bits |