Simulation studies using R
Table of Contents
1 Simulation studies
One of the great advantages of having statistical software like R available, even for a course in statistical theory, is the ability to simulate samples from various probability distributions and statistical models.
This area is worth studying when learning R programming because simulations can be computationally intensive so learning effective programming techniques is worthwhile.
We begin with some background on R functions associated with distributions.
2 R functions associated with probability distributions
A simulation study typically begins with a probability model for the
data and simulation of responses from this model. For several common probability distributions R provides a set of functions, sometimes
called a d-p-q-r family, to evaluate the probability density
function (for continuous distributions - the probability mass function
for discrete distributions), the cumulative distribution function or
the quantile function (inverse of the c.d.f) and for simulation of a
random sample.
As shown in the table the names of the functions are composed of the initial letter indicating
- d
- density function (or probability mass function)
- p
- (cumulative) probability function (values are always in the interval [0,1])
- q
- quantile function - the inverse (more-or-less) of the p function
- r
- simulation of a random sample from the distribution
and an abbreviation of the distribution name, as shown in this table, which also states the parameter names used for the distribution.
2.1 Common distributions
Common continuous distributions include
- Exponential
-
(
exp) The parameter israte(defaults to 1). The mean of the distribution is 1/rate. - Normal (or Gaussian)
-
(
norm) The most famous distribution in statistics, this is the well-known "bell-curve". Parameters of the distribution aremean(defaults to 0) andsd(defaults to 1). - Uniform
-
(
unif) Parameters aremin(defaults to 0) andmax(defaults to 1).
Common discrete distributions include
- Binomial
-
(
binom) Parameters aresize, the number of trials, andprob, the probability of success on a single trial (no defaults). - Geometric
-
(
geom) Parameter isprob, the probability of success on each independent trial. Note that the distribution is defined in terms of the number of failures before the first success. - Poisson
-
(
pois) The parameter islambda, the mean.
2.2 Less common and derived distributions
Less common continuous distributions include
- Beta
-
(
beta) Parameters areshape1andshape2(without defaults) andncp, the non-centrality parameter, with a default of 0, corresponding to the central beta. - Cauchy
-
(
cauchy) Parameters arelocation(defaults to 0) andscale(defaults to 1). - Gamma
-
(
gamma) Parameters areshapeand one ofrateorscale. The last two parameters are inverses of one another and both default to 1. - Logistic
-
(
logis) Parameters arelocationandscale. - Log-normal
-
(
lnorm) Parameters aremeanlogandsdlog. - Weibull
-
(
weibull) Parameters areshapeandscale.
Continuous distributions describing sample statistics from a Gaussian population include
- Chi-square
-
(
chisq) Parameters aredfandncp, the non-centrality parameter. - F
-
(
f) Parameters aredf1anddf2, the numerator and denominator degrees of freedom. An optional parameter isncp, the non-centrality parameter. If omitted a central F distribution is assumed. - t
-
(
t) Parameters aredfandncp, the non-centrality parameter. If omitted a central t distribution is assumed.
Less common discete distributions include the hypergeometric (hyper)
and the negative binomial (nbinom).
3 Reproducibility of "random" samples
Although the "random" numbers generated by the r<dabb> functions
appear to be random they are, in fact, calculated according to
systematic algorithms. We say they are pseudo-random numbers. For
all intents and purposes they seem to be random (and there are
extensive checks performed on the generators to ensure that they do
have the properties we would expect for a random sample) but they are
reproducible, if we so choose.
3.1 Setting the seed for the pseudo-random number generator
The random number stream depends on a seed value. If we want to produce a reproducible example (so, for example, we can talk about properties of a particular sample and the reader can generate the same sample for herself so she can examine it) then we set the seed to a known value before generating the sample. The stored seed is a complicated structure but we can set it to an integer, often something trivial like
set.seed(1) # Ensure a reproducible stream
If we simulate a sample,
(s1 <- rnorm(5))
[1] -0.6264538 0.1836433 -0.8356286 1.5952808 0.3295078
then similate a second sample
(s2 <- rnorm(5))
[1] -0.8204684 0.4874291 0.7383247 0.5757814 -0.3053884
we get different values. However, if we reset the seed to 1 and then simulate the second sample we reproduce the original values.
set.seed(1)
(s2 <- rnorm(5))
[1] -0.6264538 0.1836433 -0.8356286 1.5952808 0.3295078
We can see from the output that the printed values of the two samples are similar. However, the printed values are rounded. A more reliable check is
all.equal(s1, s2)
[1] TRUE
4 A first use of simulation - verifying theoretical properties
With resources like Wikipedia we now have effectively instant access to many of the theoretical results about distributions that, in the past, many of us needed to memorize. Nevertheless, it is still a good idea every once in a while to validate expressions for, say, the mean, the variance (or standard deviation), the median, etc. of a distribution.
4.1 Comparing sample statistics to theoretical values
The theoretical expected value and variance of a distribution are defined in terms of the parameters. Sometimes the definitions are simple and easy to remember; other times they aren't. A simple way to examine how, say, the expected value depends on the parameter is to simulate a very large sample from the distribution and evaluate the sample mean.
Recall that the parameter rate in the R d-p-q-r functions for the
exponential distribution is the inverse of the expected value. We
would anticipate that the sample mean for a large sample will be very
close to the theoretical mean, 1/rate.
mean(rexp(1e6, rate = 1))
[1] 1.000786
mean(rexp(1e6, rate = 0.5))
[1] 2.000935
mean(rexp(1e6, rate = 2))
[1] 0.5007178
So the theoretical value of 1/rate seems to hold.
What about the variance or the standard deviation. I can remember that one of them is also 1/rate but sometimes I forget which one.
var(rexp(1e6, rate = 1))
[1] 1.000989
var(rexp(1e6, rate = 0.5))
[1] 4.002376
var(rexp(1e6, rate = 2))
[1] 0.2494673
So it looks as if the variance is 1/rate2 which would mean that it is the standard deviation that is 1/rate.
- Exercises
-
Evaluate the sample mean, variance and standard deviation of one or
more large samples from the Geometric distribution for different
values of
prob(remember that this parameter represents a probability and must be between 0 and 1). Look at the Wikipedia description for the Geometric distribution, which describes two ways of writing the distribution- the number of failures before the first success
- the number of trials until the first success
Which version is implemented in R?
-
Evaluate the sample mean, variance and standard deviation of one or
more large samples from the Uniform distribution for different
values of the parameters
minandmax. How does the variance related tominandmax. -
Evaluate the sample mean, variance and standard deviation of one or
more large samples from the Binomial distribution for different values
values of the parameters
sizeandprob. Compare these to the theoretical values.
-
Evaluate the sample mean, variance and standard deviation of one or
more large samples from the Geometric distribution for different
values of
4.2 What is a "large" sample?
We use a large sample size (the notation 1e6 indicates 106 or one
million) so that the sample statistic will be very close to its
theoretical value based on the parameter values. Because I work on a
netbook computer with a comparatively slow processor one million is a
large sample size for me. You may be able to use larger sizes.
5 Simulation of sample statistics
A more common use of simulation is to assess the distribution of a sample statistic for a sample from a particular probability distribution. Just about every introductory text book shows simulations of the distribution of the mean from i.i.d. samples from different probability distributions when the Central Limit Theorem is introduced.
It is important here to distinguish between n, the size of the sample being considered, and N, the number of replications of the value of the statistic to be simulated. In practice n is small, often less than 100, and N is large, perhaps on the order of hundreds of thousands or more. The interest is in the properties of statistics calculated from "real world" samples for which n, the sample size, may be moderate. We use a large number of replications, N, to get a realistic representation of the distribution, so that we can examine its empirical distribution expecting that it will be close to the theoretical distribution.
5.1 Simulation of the Central Limit Effect
We just saw that for an exponential distribution with parameter rate
the mean is 1/rate and the standard deviation is also 1/rate. The
shape of the distribution is, of course, the negative exponential
shape.
The Central Limit Theorem states that for the distribution of the sample mean of i.i.d. samples of size n from a distribution with mean mu and standard deviation sigma will have mean mu and standard deviation sigma/sqrt(n) and, furthermore, the shape of the distribution will tend to a normal or Gaussian shape as n gets large.
But the result on the shape is an asymptotic result (i.e. as n gets large). Can we count on it holding for moderate values of n?
Our steps in such a simulation are:
- Choose the values on n that we wish to examine. Because of the factor of sqrt(n) in the denominator of the standard deviation of the sample mean, we may want to use numbers that are squares, such as 1, 4, 9, 16, 25, 36, 49.
- Choose a value of N, the number of replications. I would recommend at least 105 and perhaps as much as 106. The trade-offs are that a larger value allows you to get a smoother approximation to the density and more precise approximations to the theoretical quantities but large values of N take longer. Start with a moderately large value and, if your computer can handle that quickly then scale up until it seems to be taking too long.
-
Choose the distribution and parameter values and the statistic of
interest. For our simulation we will use the exponential (
rexp) and the default value of the parameterrate. We use the functionmeanto evaluate the sample mean.
5.2 Automatic replication of a calculation
If we want just one value of the sample mean from an i.i.d. sample of
size n = 9 we could use
mean(rexp(9, rate = 1))
[1] 1.08991
but now we want to repeat that operation N times and save the resulting values for later analysis.
Because R is a programming language we can use some of the control
structures to accomplish this. Neophyte R programmers often do this
in a for loop but you have to be careful exactly how you set up the
loop if you want to do this effectively.
Fortunately, there is an alternative to the for loop.
The replicate function in R is a convenient way of repeating a
calculation, usually involving a simulation, and collecting the
results.
str(mns9 <- replicate(10^5, mean(rexp(9, rate = 1))))
num [1:100000] 0.657 1.358 0.938 0.994 1.659 ...
5.3 Examining the sample of realizations of the test statistic
So now we have generated a sample of size 100,000 of means of samples of size 9 from the standard exponential distribution.
We expect
mean(mns9)
[1] 1.000712
to be close to 1 and
sd(mns9)
[1] 0.334026
to be close to 1/3.
To examine the shape of the distribution we can use an empirical density plot
library(ggplot2) qplot(mns9, geom="density", main="Means of samples of size 9 from an exponential dist.")
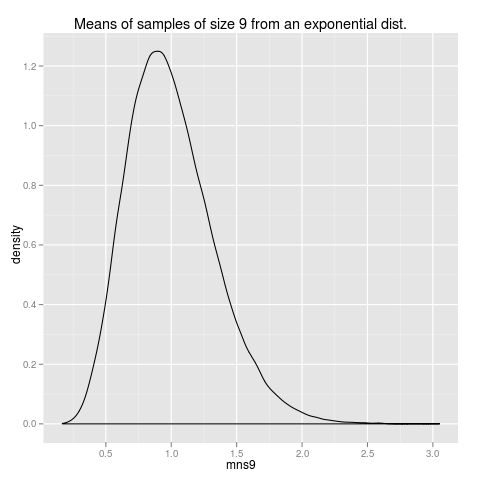
or a normal probability plot, also called a qq or quantile-quantile plot.
qplot(sample=mns9, main="Means of samples of size 9 from an exponential dist.")
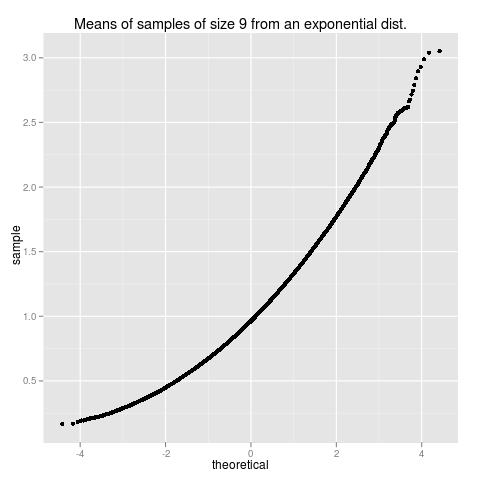
That last plot takes a long time to produce because there are so many points to plot. There are techniques, to be discussed later, to thin the plot and avoid plotting so many points.
6 Summary
-
R functions for producing a random sample from a particular
distribution have names of the form
r<dabb>wheredabbis an abbreviated for of the distribution name. -
For a large sample the values of sample statistics, such as
mean,var,sd,median, etc. should be close to the theoretical values determined by the model parameters. - We also use simulation to approximate the distribution of sample statistics calculated from small-sized samples. To evaluate the distribution we replicate the operation of selecting the sample and evaluating the sample statistic. The number of replicates, N, is as large as feasible. The larger N is, the better we approximate the distribution but it also can take much longer to run. The sample size, n, is often small.
- An idiom to remember is
statSamp <- replicate(N, <statFun>(r<dabb>(n, <par values>)))
where statFun is the function to calculate the sample statistic
(mean, median, etc.), <dabb> is the abbreviated name of the
distribution and <par values> are values of the parameters of the
distribution.
Date: 2010-08-19 Thu
HTML generated by org-mode 7.01h in emacs 23