Introduction
Optical music recognition (OMR) is the process of taking an image of sheet music and converting it into a computer readable format (such as musicXML or MIDI).
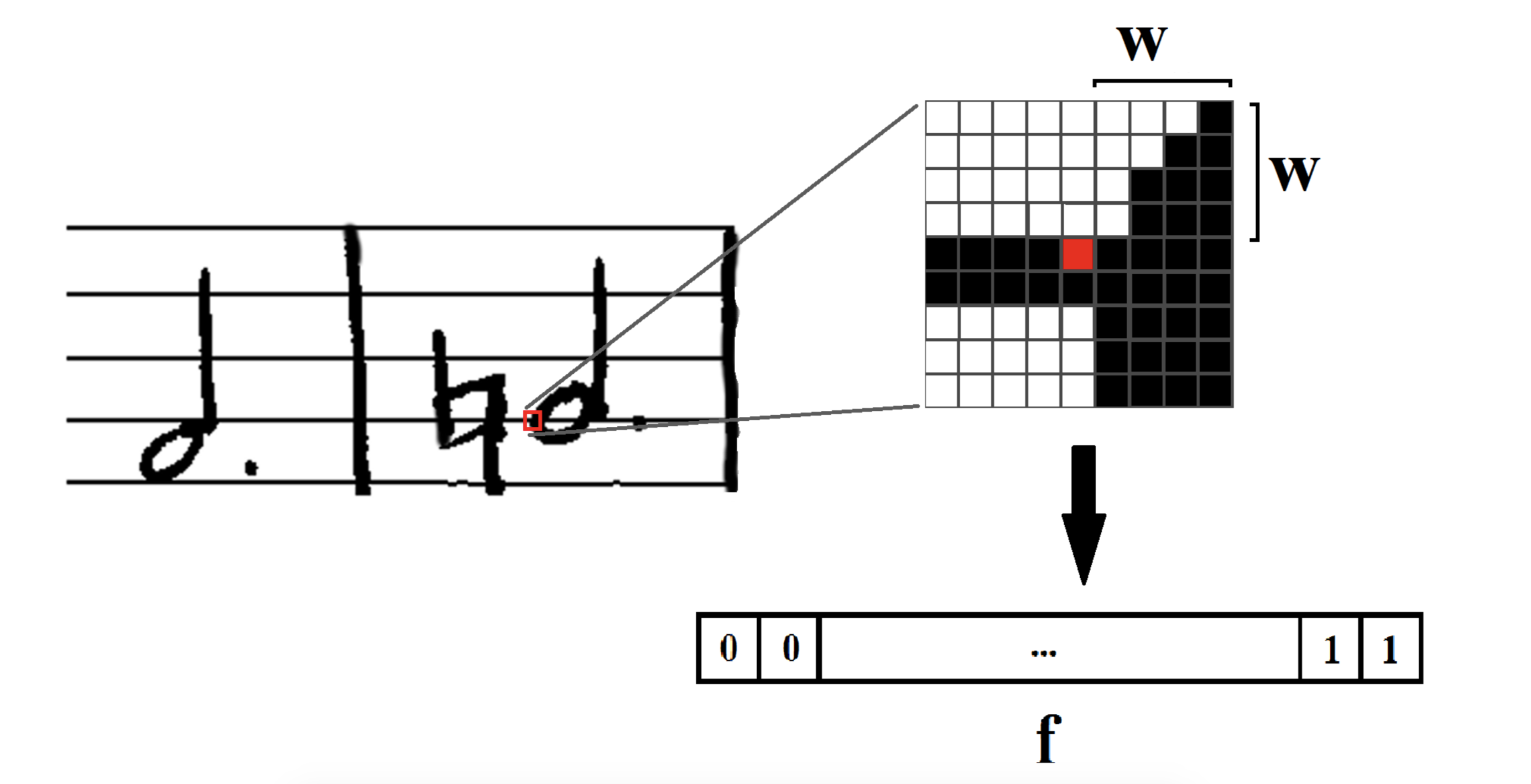
OMR is similar to optical character recognition, which is the task of identifying handwritten text. However, OMR is much more difficult due to the hierarchical and nonlinear structure of sheet music.
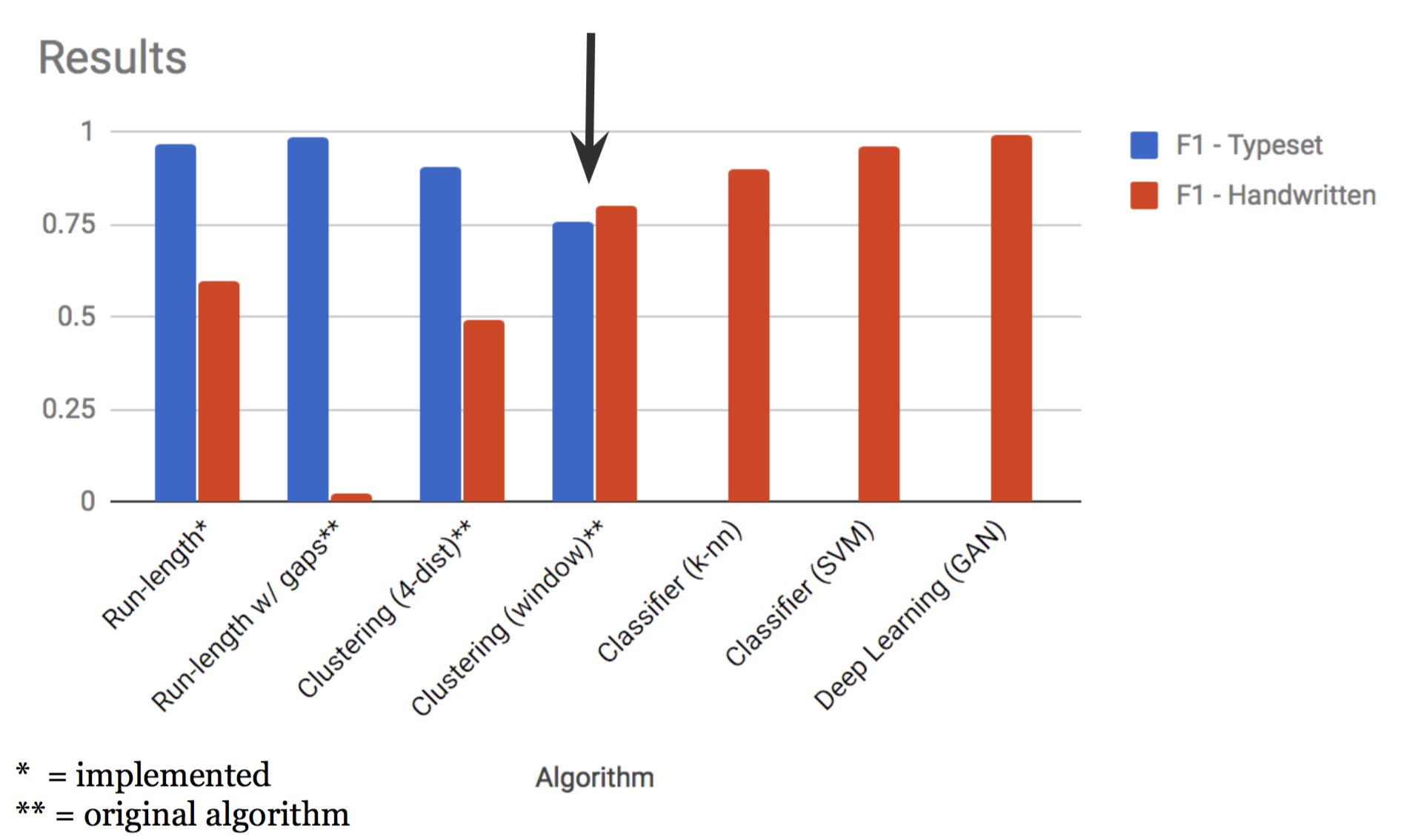
There has been a great deal of work in OMR in recent years. For a thorough overview of the field, see [Novotny and Pokorny, 2015].