Prev: L18, Next: L20
Course Links: Canvas, Piazza, TopHat (212925)
Zoom Links: MW 4:00, TR 1:00, TR 2:30.
Tools
📗 You can expand all TopHat Quizzes and Discussions: , and print the notes: , or download all text areas as text file: .
📗 For visibility, you can resize all diagrams on page to have a maximum height that is percent of the screen height: .
📗 Calculator:
📗 Canvas:
pen
# Adversarial Search
📗 The search problem for games (one or more opponents are searching at the same time) is adversarial search: Link, Wikipedia.
➩ The initial state is the beginning of the game.
➩ Each successor represent an action or a move in the game.
➩ The goal states are called terminal states, the search problem tries to find the terminal state with the lowest cost (highest reward).
📗 The opponents search at the same time and tries to minimize their costs (or maximize their rewards).
➩ For zero-sum games, the sum of the rewards and costs for the two players is 0 at every terminal state. The opponent minimizes the reward (or maximizes the cost) of the first agent: Wikipedia.
In-class Discussion
📗 [1 points] pirate got gold coins. Each pirate takes a turn to propose how to divide the coins, and all pirates who are still alive will vote whether to (1) accept the proposal or (2) reject the proposal, kill the pirate who is making the proposal, and continue to the next round. Use strict majority rule for the vote, and use the assumption that if a pirate is indifferent, they will vote reject with probability 50 percent. How will the first pirate propose? Enter a vector of length , all integers, sum up to .
📗 Answer (comma separated vector): .
In-class Discussion
📗 [1 points] Two players, A and B, objects, each player can pick 1 or 2 each time. Pick the last object to win. If you pick first, how many should you pick?
📗 In the diagram, the node has the player name (or G for end of game) and the subscript means how many objects are left. The terminal nodes where player A wins are marked green, and where player B wins are marked blue.
📗 Answer: .
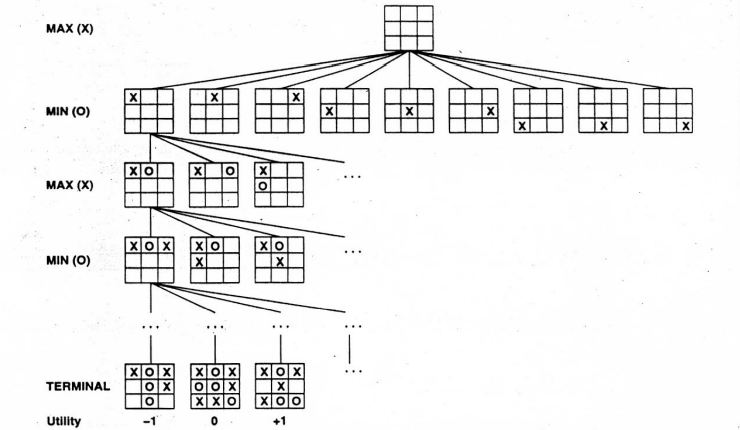
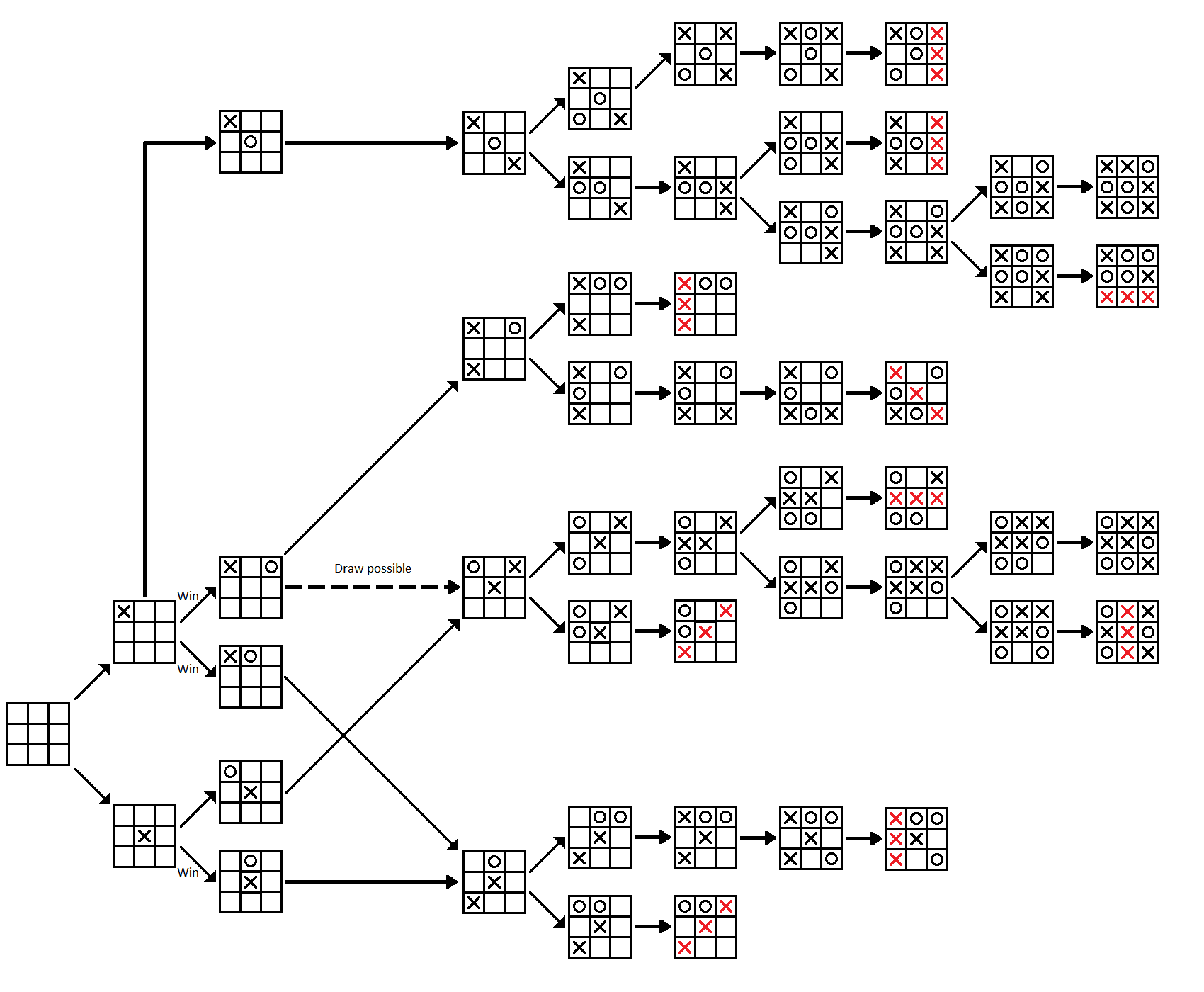
# Minimax Algorithm
➩ The game is solved backward starting from the terminal states.
➩ Each agent (player) chooses the best action given the optimal actions of all players in the subtrees (subgames).
📗 For zero-sum games, the optimal value at an internal state for the MAX player is called \(\alpha\left(s\right)\) and for the MIN player is called \(\beta\left(s\right)\).
📗 The time and space complexity is the same as DFS with \(D = d\).
In-class Discussion
📗 [4 points] Highlight the solution of the game (drag from one node to another to highlight the edge connecting them).
Algorithm

# Non-Determinstic Games
📗 For non-deterministic games, some internal states represent moves by Chance (can be viewed as another player), for example, dice roll or coin flip. For those states, expected cost or reward are used instead of max or min.
📗 DFS on games with Chance is called expectiminimax: Wikipedia.
In-class Quiz
(Past Exam Question) ID:📗 [4 points] Consider a zero-sum sequential move game with Chance. player moves first, then Chance, then . The values of the terminal states are shown in the diagram (they are the values for the Max player). What is the (expected) value of the game (for the Max player)?
📗 Note: in case the diagram is not clear, the probabilities from left to right is: , and the rewards are .
📗 Answer: .
# Pruning
📗 When a branch will not lead the current agent (player) to win, the branch can be pruned (both players will not need to search the subtree). DFS with pruning is called Alpha-Beta Pruning: Wikipedia.
➩ During DFS, keep track of both \(\alpha\left(s\right)\) and \(\beta\left(s\right)\) for each state.
➩ Here, the \(\alpha\left(s\right)\) and \(\beta\left(s\right)\) values are the current best value of an internal state so far (based only on the successor states that are expanded), which are not necessarily the final optimal values.
➩ Prune the subtree after \(s\) if \(\alpha\left(s\right) \geq \beta\left(s\right)\).
In-class Discussion
📗 [4 points] Highlight the nodes that will be alpha-beta pruned in the following game.
Algorithm

test prt,nim,mnx,chn,abp q
📗 Notes and code adapted from the course taught by Professors Jerry Zhu, Yingyu Liang, and Charles Dyer.
📗 Content from note blocks marked "optional" and content from Wikipedia and other demo links are helpful for understanding the materials, but will not be explicitly tested on the exams.
📗 Please use Ctrl+F5 or Shift+F5 or Shift+Command+R or Incognito mode or Private Browsing to refresh the cached JavaScript.
📗 You can expand all TopHat Quizzes and Discussions: , and print the notes: , or download all text areas as text file: .
📗 If there is an issue with TopHat during the lectures, please submit your answers on paper (include your Wisc ID and answers) or this Google form Link at the end of the lecture.
📗 Anonymous feedback can be submitted to: Form.
Prev: L18, Next: L20
Last Updated: June 27, 2026 at 9:06 PM