Back to index
Parallel Database Systems: The Future of High Performance Database Systems
David J. DeWitt and Jim Gray
University of Wisconsin and DEC
Scribe by: Zuyu Zhang
One-line Summary
Overview/Main Points
- Goals for parallelism
- linear speedup
- Speedup = small system time⁄big system time
- 2x hardware does the same problem in ½ time.
- linear: n times as large means 1⁄n the time
- Superlinear speedup
- NO!
- Yes, but it is tricky: one system does not fit in memory, but two fit! Thus, the speedup is larger than two.
- linear scale-up
- 2x hardware does problem 2x bigger in the same time.
- Relational operators
- select-project / scan
- sort
- aggregate: sum, min, max, or count
- insert, update, delete
- set operators: union, intersection, difference
- join, division
- Generic Barries
- startup time
- time to initiate the parallel operation
- interference
- slowdown each new process imposes due to access to shared resource. Shared-nothing vs SMP.
- skew and load imbalance
- unevenly partitioned work
- Kinds of parallel systems
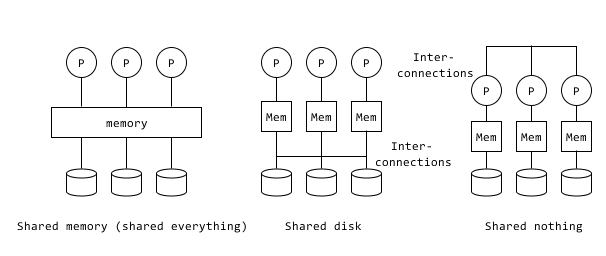
- shared memory (shared everything)
- Scaleup to a certain amount
- shared disk, with interconnection between local memory and disks
- The network bandwidth at least equals that the combined bandwidth of all the disks, or there may be network bottlenecks.
- Scaleup lower than shared memory due to communication contention
- Data consistency issues may happen because data may be cached in multiple places and accessed by any node in the system at any time.
- shared nothing, with interconnection among machines using Message Passing Interface
- Parallel database
- Typical relational systems execute queries as a collection of operations, with tuples streaming between them.
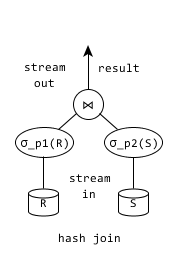
- Ex: σp1(R)⋈ σp2(S)
- hash join, and R fits in memory
- Option #1
- run each operator on a different processor
- bad, because
- no enough operators
- lots of skew between operators
- Option #2
- data parallel, partitioned execution of operators
- two new operators
- split
- merge (FIFO)
- three phases of repartition
- split: each node splits its portion of the table into fragments.
- shuffle: redistribute the fragments.
- merge: combine the shuffled fragments at their destinations.
- Data partition schemes
- range partition: not always clear to pick boundaries
- round-robin
- hashing
- Distribution strategy (RR)
- Suppose R and S are already partitioned on join attribute (no re-partitioning needed)
- Suppose R is partitioned on join attribute, but S is not ⇒ repartition S
- Suppose neither R nor S are already partitioned, and R is small
- replicate R in every processor
- network may not be the bottleneck
- Parallel in index lookup
- partition on the index attribute
- may not speedup
- a big query and partition transactions on many processors
- Select A, count(B) from R group by R.A
| R.A |
count(B) |
| a1 |
7 |
| a2 |
16 |
| ... |
... |
- Option #1
- repartition on R.A
- do local aggregation
- Option #2
- do local grouping on R.A
- repartition groups
- combine groups to do final aggregation
Relevance
Flaws