Back to index
The Grid File: An Adaptable, Symmetric Multikey File Structure
J. Nievergelt, Hans Hinterberger, and Kenneth C. Sevcik.
Institut for Informatik, ETH, and University of Toronto
One-line Summary
A balanced multikey file structure provides efficient, uniform access to multidimensional data which identified by several attributes in each record of highly dynamic files.
Overview/Main Points
- Problem statement
- A file F consisting of a collection of records R = [a1, a2, ..., ak], where the a are fields containing attribute values.
- [LastName, FirstName, MiddleInitial, YearOfBirth, SSN]
- [Doe, John, -, 1951, 123456789]
- Query classification
- exact match query, point query: entire record specified
- partially specified query: Doe born in 1951
- single-key query: all records with last name Doe
- presumably unique: ssn 987654321
- range or interval query: everybody born between 1940 and 1960
- Multikey access problem
- a record is characterized by a small number of attributes (less than 10)
- the domain Si of each attributes is large, independent, and linearly ordered (li ≤ ai ≤ ui)
- Idea for multikey access file structure
- bitmap representation of the attribute space: reserve one bit for each possible record in the space
- k-dimensional matrix represents all possible values of k attributes
- dynamic partition (directory) on all key-value space for compressed bitmap
- Performance criteria adapts from response times to multikey access request to the number of disk access due to fixed data transfer rate of the disks
- Design principles
- Two-disk-access principle: at most two disk accesses for a single record retrieve (one for the directory, the other data bucket)
- Efficient range queries with respect to all attributes
- Grid partitions
- Two categories of searching techniques
- organize the specific set of data to be stored: comparative search techniques, such as binary search trees, since the boundaries between different regions are determined by values of stored data.
- organize the embedding space from which the data is drawn: address computation techniques, including radix trees, since region boundaries are drawn at fixed places regardless of the content of the file.
- Space partition techniques
- recursively divide and conquer results in progressively shorter region boundaries
- inverted file where the primary key determines region boundaries for a uniform bucket occupancy, while the secondary key is partitioned independently of the data to be stored (the value of the key domain may be in its own region).
- grid file whose each region boundary seperates the entire search space at fixed value of the domain, but all dimensions are treated symmetrically
- grid blocks divided by the k-dimension record space
- an one-dimensional parition is created by either splitting or merging
- Grid file
- a bucket contains c records where 10 < c < 1000.
- grid directory
- functionalities of a bucket management system
- a class to assign grid blocks in the record space to data buckets
- a data structure (called grid directory) that represents the assignment and supports operations to update the assignments when bucket overflow or underflow
- an algo to update the directory for the changes of the assignment
- all the records in one grid block store in the same bucket, but several grid blocks (called region of the bucket) may share a bucket.
- convex assignment of grid blocks to buckets
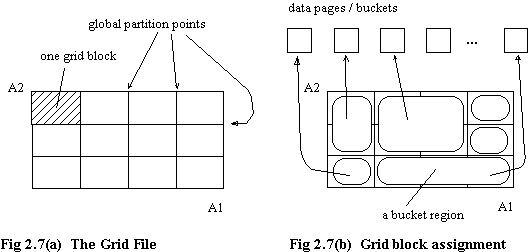
- the union of the shared assignments of the grid blocks forms a rectangular box in the space of records.
- the regions of buckets are pairwise disjoint, and together span the space of records
- grid directory
- grid array: a dynamic k-dimensional array whose elements (pointers to data buckets) are one-to-one correspondent with the gird blocks of the partition.
- linear scales: k one-dimensional arrays whose scale defines a partition of a domain S.
- Example of two-dimensional space S = X × Y
- nx > 0, ny > 0, 0 ≤ cx < nx, 0 ≤ cy < ny
- G(0, ..., nx-1, 0, ... ny-1)
- X(0, ..., nx), Y(0, ..., ny)
- Operations
- direct acess: G(cx, cy)
- Next in each direction
- nextxabove: cx ← (cx + 1) mod nx
- nextxbelow: cx ← (cx - 1) mod nx
- nextyabove: cy ← (cy + 1) mod ny
- nextybelow: cy ← (cy - 1) mod ny
- Merge
- mergex
- given px, 1 ≤ px < nx, merge px with nextxbelow
- rename all elements above px
- adjust X-scale
- mergey: for any py, 1 ≤ py < ny
- Split
- splitx
- given px, 0 ≤ px < nx, create new element px+1
- rename all cells above px
- adjust X-scale
- splity: for any py, 0 ≤ py < ny (≤ ny in the paper)
- Constrains on the values: if G(i', j') = G(i'', j''), then for all i, j such that i' ≤ i ≤ i'' and j' ≤ j ≤ j'', G(i, j) = G(i', j') = G(i'', j'')
- A query on 2-dim space using grid directory
- [a, z]. A1 = (a, f, k, p, z)
- [0, 10]. A2 = (0, 2, 7, 10)
- Query: A1 = 'x' AND A2 = 6
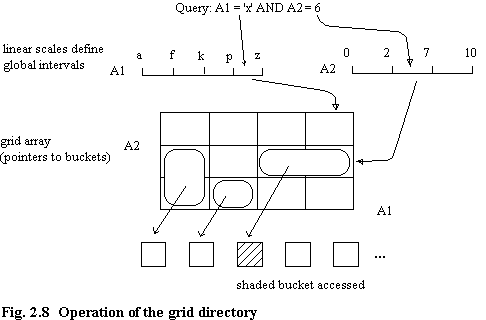
- Decisions
- grid partitions of the search space
- convex assignments of grid blocks (region) to buckets
- grid directory, a (large) dynamic array but small linear scales
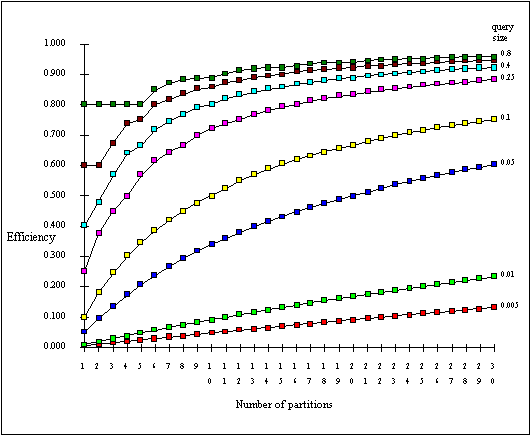
- Performance with respect to partition size
- Issues
- splitting and merging policy
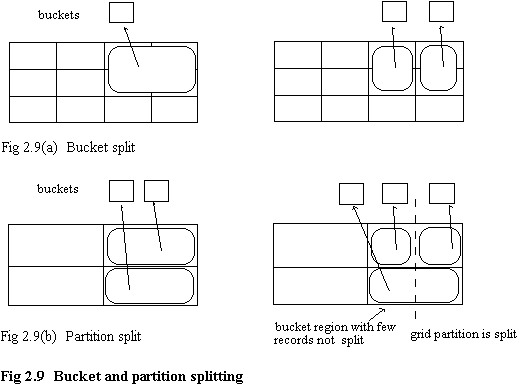
- implementation of the grid directory
- concurrent access
- Precision: the number of records retrieved that meet the query specification / total number of records retrieved
- High precision VS mapping of cell to bucket
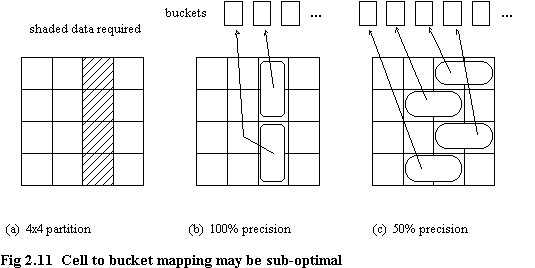
- High precision VS contiguous access

Relevance
Flaws