Software deployment
For this assignment, you will get hands-on experience with Apache Storm and GraphX and MLlib. Fortunately, GraphX and MLlib are integrated in the SPARK stack and are already available due to your SPARK installation for the assignment 2. Apache Storm has its own stack, and it requires Apache Zookeeper for coordination in cluster mode.
Apache Zookeeper
To install Apache Zookeeper you should follow the instructions here. First, you need to download zookeeper-3.4.6.tar.gz, and deploy it on every VM in /home/ubuntu/software. Next, you need to create a zoo.cfg file in /home/ubuntu/software/zookeeper-3.4.6/conf directory. You can use zoo.cfg as a template. If you do so, you need to replace the VMx_IP entries with your corresponding VMs IPs and create the required directories specified by dataDir and dataLogDir. Finally, you need to create a myid file in your dataDir and it should contain the id of every VM as following: server.1=VM1_IP:2888:3888, it means that VM1 myid's file should contain number 1.
Next, you can start Zookeeper by running zkServer.sh start on every VM. You should see a QuorumPeerMain process running on every VM. Also, if you execute zkServer.sh status on every VM, one of the VMs should be a leader, while the others are followers.
Apache Storm
A Storm cluster is similar to a Hadoop cluster. However, in Storm you run topologies instead of "MapReduce" type jobs, which eventually processes messages forever (or until you kill it). To get familiar with the terminology and various entities involved in a Storm cluster please read here.
To deploy a Storm cluster, please read here. For this assignment, you should use apache-storm-0.9.5.tar.gz. You can use this file as a template for the storm.yaml file required. To start a Storm cluster, you need to start a nimbus process on the master VM (storm nimbus), and a supervisor process on any slave VM (storm supervisor). You may also want to start the UI to check the status of your cluster (PUBLIC_IP:8080) and the topologies which are running (storm ui).
Apache Spark
We assume you have SPARK already deployed in your cluster. Otherwise please take a look at assignment 2 for deployment instructions.
Questions
In this assignment, you will write simple Storm applications to process tweets. Next you will create a graph using the output of your Storm applications and you will apply various graph processing techniques to answer several questions. Finally, you will create feature vectors and apply machine learning algorithms to classify the extracted tweets.
Part A - Apache Storm
Prepare the development environment
To write a Storm application you need to prepare the development environment. First, you need to untar apache-storm-0.9.5.tar.gz on your local machine. If you are using Eclipse please continue reading otherwise skip the rest of this paragraph. First, you need to generate the Eclipse related projects; in the main storm directory, you should run: mvn eclipse:clean; mvn eclipse:eclipse -DdownloadSources=true -DdownloadJavadocs=true. (We assume you have installed a maven version higher than 3.0 on your local machine). Next, you need to import your projects into Eclipse. Finally, you should create a new classpath variable called M2_REPO which should point to your local maven repository. The typically path is /home/your_username/.m2/repository.
Typical Storm application
Once you open the Storm projects, in apache-storm-0.9.5/examples/storm-starter, you will find various examples of Storm applications which will help you understand how to write / structure your own applications. The figure below shows an example of a typical Storm topology:
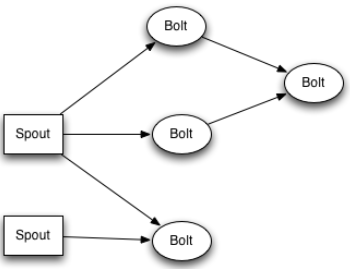
The core abstraction in Storm is the stream (for example a stream of tweets), and Storm provides the primitives for transforming a stream into a new stream in a distributed and reliable way. The basic primitives Storm provides for doing stream transformations are spouts and bolts. A spout is a source of streams, while bolts are consuming any number of input streams either from spouts or other bolts. Finally, networks of spouts and bolts are packaged into a topology that is submitted to Storm clusters for execution. The links between nodes in your topology indicate how data should be passed around. For detailed information please read here.
We recommend you place your Storm applications in the same location as the other Storm examples (storm-starter/src/jvm/storm/starter/PrintSampleStream.java). To rebuild the examples, you should run: mvn clean install -DskipTests=true; mvn package -DskipTests=true in the storm-starter directory. target/storm-starter-0.9.5-jar-with-dependencies.jar will contain the "class" files of your "topologies". To run a "topology" called "CS838Assignment" in either local or cluster mode, you should execute the following command:
storm jar storm-starter-0.9.5-jar-with-dependencies.jar storm.starter.CS838Assignment [optional_arguments_if_any].Connect to Twitter API
In this assignment, your topologies should declare a spout which connects to the Twitter API and emits a stream of tweets. To do so, you should do the following steps:
- You should instantiate the TwitterSampleSplout.java class located in storm-starter/src/jvm/storm/starter/spout/TwitterSampleSpout.java.
- TwitterSampleSpout instantiation requires several authentication parameters which you should get from your Twitter account. Concretely, you need to provide consumerKey, consumerSecret, accessToken, accessTokenSecret. For more information you can check here.
- You can start by filling your credentials in PrintSampleStream.java topology. It creates a spout to emit a stream of tweets and a bolt to print every streamed tweet.
Questions
Question 1. To answer this question, you need to extend the PrintSampleStream.java topology to collect tweets which are in English and match certain keywords (at least 10 distinct keywords) at your desire. You should collect at least 500'000 tweets which match the keywords and store them either in your local filesystem or HDFS. Your topology should be runnable both in local mode and cluster mode.
Question 2. To answer this question, you need to create a new topology which provides the following functionality: every 30 seconds, you should collect all the tweets which are in English, have certain hashtags and have the friendsCount field satisfying the condition mentioned below. For all the collected tweets in a time interval, you need to find the top 50% most common words which are not stop words (http://www.ranks.nl/stopwords). For every time interval, you should store both the tweets and the top common words in separate files either in your local filesystem or HDFS. Your topology should be runnable both in local mode and cluster mode.
Your topology should have at least three spouts:
- Spout-1: connects to Twitter API and emits tweets.
- Spout-2: It contains a list of predefined hashtags at your desire. At every time interval, it will randomly sample and propagate a subset of hashtags.
- Spout-3: It contains a list of numbers. At every interval, it will randomly sample and pick a number N. If a tweet satisfies friendsCount < N then you keep that tweet, otherwise discard.
Notes:
- Please pick the hashtags list such that every time interval, at least 100 tweets satisfy the filtering conditions and are used for the final processing.
- You may want to increase the incoming rate of tweets which satisfy your conditions, using the same tricks as for Question 1.
Part B - Building a Machine Learning application using Spark's MLlib
This part of the assignment is aimed at familiarizing you with Machine Learning (ML) applications on big-data frameworks. You will use MLlib (Spark's machine learning library), to execute clustering algorithms on tweets collected in Part A of the assignment. The focus here is **not** to come up with your own ML algorithm or feature extraction methods, but rather to use available libraries to build an end-to-end application. Please refer to Spark's extensive documentation on the available ML libraries here.
The task (should you choose to accept it) is to group a large number of tweets (say, a million) into a small number of clusters (say 100). The idea is that tweets on the same topic (say, "@nytimes Breaking News: Biden says he won't run for president" and "@AC360 I will not be a candidate, but I will not be silent -- Joe Biden on not running for Pres") will be grouped into one cluster, and a tweet on a totally different topic (say, "@businessinsider Apple just launched a big new update for the iPhone that adds tons of new emojis") will be grouped into another. These clustering algorithms are extensively used in finding "trending topics" on Twitter.
You will be using the bag-of-words model to find the similarity between two tweets. Essentially, the bag-of-words model says that the words contained in a tweet characterize it; the ordering does not matter. Two tweets that have common words are similar; the more words they have in common, the higher their similarity.
The task involves the following steps:
Part C - GraphX
Prepare the development environment
GraphX is a component in SPARK for graphs and graph-parallel computation. To get a better understanding about how to write simple graph processing applications using GraphX, you should check here.
Developing a GraphX application involves the same steps you followed for assignment 2. Your SparkContext should have the same configuration parameters you used before.
Building the graph
You will run GraphX on a graph you will build based on the output of Question 2 from Part A. More concretely you graph should be as following:
- A vertex embodies the top most common words you found during a time interval.
- Two vertices A and B have an edge if they share at least a common word among themselves.
Note:
- Please ensure that your graph has at least 200 vertices.
Questions
Given the graph you build as mentioned above, you should write Scala scripts to answer the following questions:
Question 1. Find the number of edges where the number of words in the source vertex is strictly larger than the number of words in the destination vertex.
Hint: to solve this question please refer to the Property Graph examples from here.