We have run a set of experiments using WPB (version 1.0) to analyse how the above systems perform under different loads. We varied the number of client processes and collected statistics for caching and no caching configurations. Before presenting the mains results obtained, we describe the hardware platform where the experiments were run.
We ran our experiments in a COW - Cluster of Workstatsions, that consists of forty Sun Sparcstations 20, each one with 2 66 Mhz CPUs, 64 MB of main memory and two 1 GB disk. The COW nodes are interconnected through different network interfaces, including a 100 Base-T interface, which we used during the experiments. We ran experiments varying the number of clients from 8 to 96, using four client machines and two server machines. We kept the ratio 4:1 between number of client processes and number of server processes. The cache size was set to 75 MB. The server latency is set to 3 seconds in all the experiments. The inherent hit ratio in the client request stream is the default value 50%. Thus, the maximum hit ratio that can be observed in the experiments (which is an average of the two phases) is around 25%.
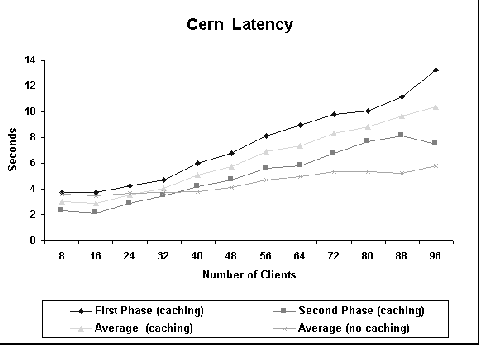
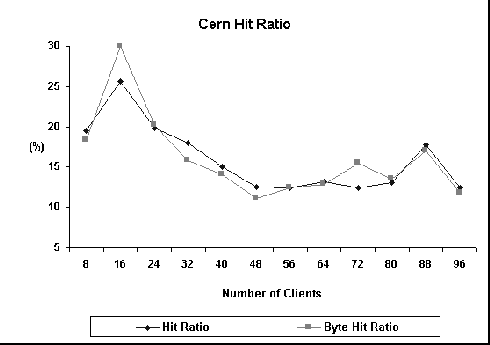
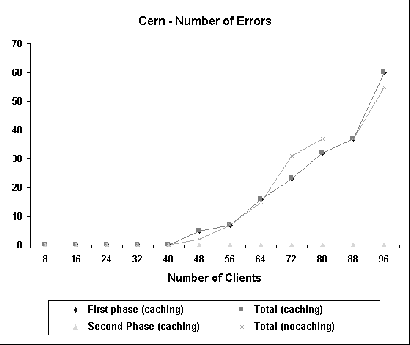
Figure 2 shows, for CERN 3.0A, how the average latency varies as a function of the number of clients in both caching and no caching configurations. For caching configuration, it also shows how the latency in the first and second phases of the experiment varies. For no caching, latency increases very slowly; for caching, however, it does increase with the number of clients. These curves show that, for our experiments, the cost of a hit may offset the cost of accessing the remote server if a great number of clients are concurrently trying to connect to the proxy. In other words, network transmission time is shorter than the time spent retrieving the file from disk. It is interesting to note that this is true despite the fact that we try to model transmission overhead by imposing a delay of 3 seconds in the server. For Cern, this limit is 32 clients; after this point, the second phase latency is bigger than the no caching average latency. Figure 3 shows the hit and byte hit ratios as a function of the number of clients. Both curves are very similar and, roughly, they show a decrease in the hit ratio. As the number of clients increases, the total number of unique files retrieved from the proxy also increases (since each client uses a different seed for the random number generator). As a consequence, hit ratio decreases. Figure 4 shows how CERN is effective in handling the incoming requests. As can be seen, after 40 concurrent clients, CERN is unable to handle all the connection requests that it receives. The number of errors increases as the number of clients increases. However, during the second phase of the caching experiment, when hits occur, no errors are observed
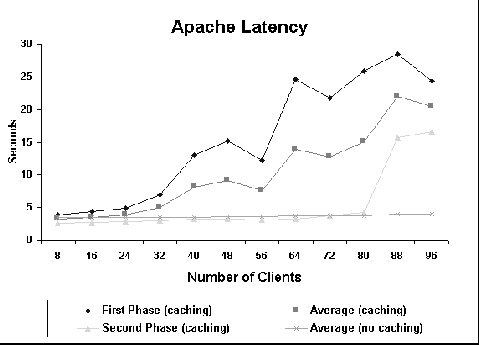
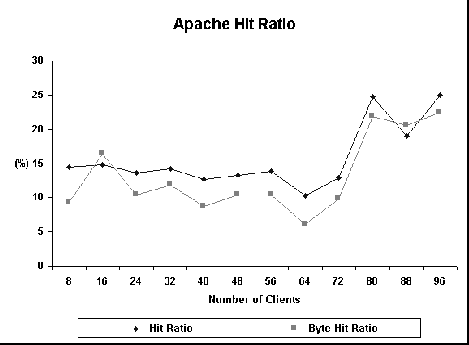
Figure 5 shows how latency varies for Apache. Although the curves are quite unstable, it is clear that latency for the caching experiments increases as a function of the number of clients. However, latency remains roughly constant when caching is disabled. Latency for the second phase of the caching experiments remains shorter than the no caching latency up to 72 clients. After this point, it increases significantly. The degradation of Apache performance as the number of clients increases is also noteworthy. The latency increases up to almost 30 seconds for 88 clients when no hit is observed. This probably is a consequence of the two-phase write that may involve several memory operations. Figure 6 shows the hit ratio curves for Apache. It seems like hit ratio in Apache is not significantly affected by the number of clients. We are currently unable to explain Apache's behavior. No errors were observed during the experiments.
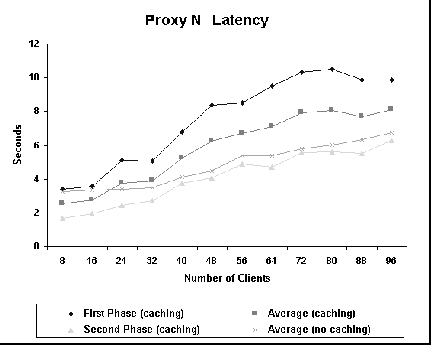
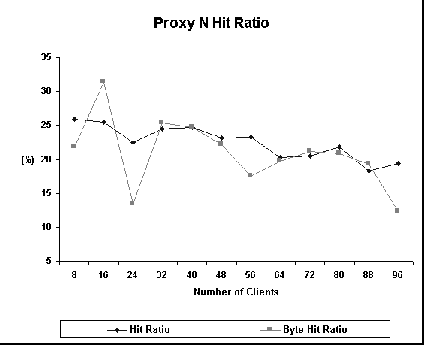
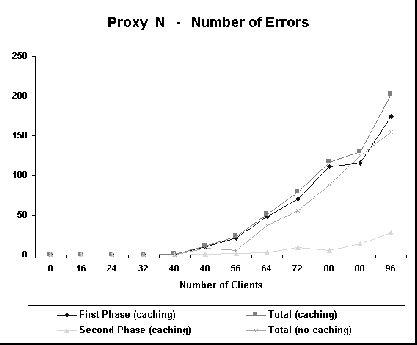
Figure 7 shows the latency curves for Proxy N. The average latency for no caching experiments increases linearly with the number of clients for this proxy. Also, the second phase latency for the caching experiments is always lower than the no caching latency. This may be due either to a better usage of disk resources or a more expensive implementation. Since latency increases linearly with the number of clients even when caching is disabled, we conjecture that overhead of proxy implementation is responsible for this behavior. One explanation is that because the number of proxy processes is always the same, as the number of client increases, more requests must be delayed waiting for available processes to handle them. This is true for both caching and no caching experiments. Figure 8 shows hit ratio curves for Proxy N. Hit ratio degrades very slowly. The only proxy that has a better hit ratio is squid, as will be shown next. This may be due to different algorithms for cleaning the cache. Figure 9 shows that the fixed number of process implementation results in a high number of errors during the experiments, especially when there is no hit in the cache. With 32 processes, the proxy is unable to handle all the requests if there are more than 48 clients. If the number of proxy processes is inceased to 64, the overall behavior is the same, but the saturation point is shifted to 88 clients. So, this parameter must be carefully tuned in order to minimize the number of errors. As a consequence, proxy N may have problems in handling bursty traffic since this parameter must be statically chosen.
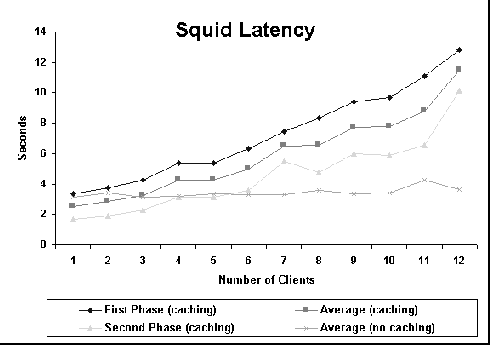
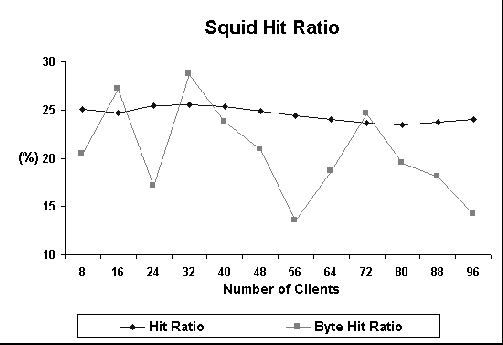
Figure 10 shows the latency curves for Squid. These curves have a behavior similar to those for Apache and Cern. However, Cern has a slightly better average latency for caching experiments. These results are consistent to those presented in [9]. When caching is disabled, Squid performs better. Figure 11 shows the hit ratio curves. Byte hit ratio is very unstable but it can be seen that Squid can sustain a fairly constant hit ratio, independent of the number of clients. We are currently trying to investigate this behavior with more details.