|
|
Text-to-Picture Synthesis Project
|
|
One challenge in artificial intelligence is to enable natural interactions between people and computers via multiple modalities. It is often desirable to convert information between modalities. One example is the conversion between text and speech using speech synthesis and speech recognition. However, such conversion is rare between other modalities. In particular, relatively little research has considered the transformation from general text to pictorial representations.
This project will develop general-purpose Text-to-Picture synthesis algorithms that automatically generate pictures from natural language sentences so that the picture conveys the main meaning of the text. Unlike prior systems that require hand-crafted narrative descriptions of a scene, our algorithms will generate static or animated pictures that represent important objects, spatial relations, and actions for general text. Key components include extracting important information from text, generating corresponding images for each piece of information, composing the images into a coherent picture, and evaluation. Our approach uses statistical machine learning and draws ideas from automatic machine translation, text summarization, text-to-speech synthesis, computer vision, and graphics.
Text-to-picture synthesis is likely to have a number of important impacts. First, it has the potential for improving literacy across a range of groups including children who need additional support in learning to read, and adults who are learning a second language. Second, it may be used as an assistive communication tool for people with disabilities like dyslexia or brain damage, and as a universal language when communication is needed simultaneously to many people who speak different languages. Third, it can be a summarization tool for rapidly browsing long text documents. Our research will foster collaboration between researchers in computer science and other disciplines, including psychology and education.
Findings
Publications
-
Michael Maynord, Jitrapon Tiachunpun, Xiaojin Zhu, Charles R. Dyer, Kwang-Sung Jun, and Jake Rosin.
An Image-To-Speech iPad App.
Department of Computer Sciences Technical Report TR1774, University of Wisconsin-Madison. 2012.
[link]
-
Arthur Glenberg, Jonathan Willford, Bryan Gibson, Andrew Goldberg, and Xiaojin Zhu.
Improving reading to improve math.
Scientific Studies in Reading, 2011.
-
Jake Rosin, Andrew Goldberg, Xiaojin Zhu, and Charles Dyer.
A Bayesian model for image sense ambiguity in pictorial communication systems.
Department of Computer Sciences Technical Report, University of Wisconsin-Madison. 2011.
-
Raman Arora, Charles R. Dyer, Yu Hen Hu, and Nigel Boston.
Distributed curve matching in camera networks using projective joint invariant signatures.
Proc. 4th ACM/IEEE International Conference on Distributed Smart Cameras. Atlanta, GA, 2010.
-
Andrew B. Goldberg, Jake Rosin, Xiaojin Zhu, and Charles R. Dyer.
Toward Text-to-Picture Synthesis.
In NIPS 2009 Symposium on Assistive Machine Learning for People with Disabilities, 2009.
[pdf]
-
Arthur Glenberg, Andrew B. Goldberg, and Xiaojin Zhu.
Improving early reading comprehension using embodied CAI.
Instructional Science, 2009.
[link]
-
Andrew B. Goldberg, Xiaojin Zhu, Charles R. Dyer, Mohamed Eldawy, and Lijie Heng.
Easy as ABC? Facilitating pictorial communication via semantically enhanced layout.
In Twelfth Conference on Computational Natural Language Learning (CoNLL), 2008.
If you have pictures for individual words in a sentence, how do you compose them to best convey the meaning of the sentence? We learn an "ABC" layout using semantic role labeling and conditional random fields, and conduct a user study.
[pdf]
-
Xiaojin Zhu, Andrew Goldberg, Mohamed Eldawy, Charles Dyer, and Bradley Strock.
A text-to-picture synthesis system for augmenting communication.
In The Integrated Intelligence Track of the Twenty-Second AAAI Conference on Artificial Intelligence (AAAI-07), 2007.
Synthesizing a picture from general, unrestricted natural language text, to convey the gist of the text.
This is an overview, as well as proof of concept, paper.
[pdf]
Faculty
Graduate Students
Undergraduate Students
- Benjamin Burchfield
- Valerie Lo
- Molly Maloney
- Michael Maynord
- Mia Mueller
- Peter Ney
- Bradley Strock
- Jitrapon Tiachunpun
- Nicholas Wharton
- Steve Yazicioglu
Collaborators
- Arthur Glenberg, Department of Psychology, Arizona State University.
-
Jamie Murray-Branch, Department of Communicative Disorders, University of Wisconsin-Madison.
-
Julie Gamradt, Department of Communicative Disorders, University of Wisconsin-Madison.
-
Katie Hustad, Department of Communicative Disorders, University of Wisconsin-Madison.
-
Josh Tenenbaum, Department of Brain and Cognitive Sciences, Massachusetts Institute of Technology.
-
Suman Banerjee, Department of Computer Sciences, University of Wisconsin-Madison.
 This project is based upon work supported by the National Science
Foundation under Grant No. IIS-0711887, and by the Wisconsin Alumni Research
Foundation. Any opinions, findings, and conclusions or
recommendations expressed in this material are those of the authors and do not
necessarily reflect the views of the National Science Foundation.
This project is based upon work supported by the National Science
Foundation under Grant No. IIS-0711887, and by the Wisconsin Alumni Research
Foundation. Any opinions, findings, and conclusions or
recommendations expressed in this material are those of the authors and do not
necessarily reflect the views of the National Science Foundation.
|

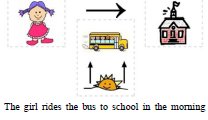
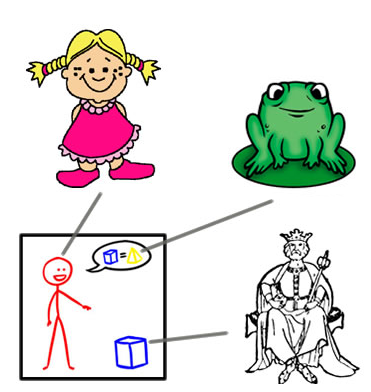 "The girl called the king a frog."
"The girl called the king a frog."
 Now you see cheese.
Now you see cheese.
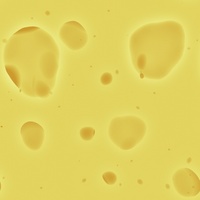

 Now you see Swiss cheese.
Now you see Swiss cheese.
 Children manipulate the icons in the picture while reading the story.
Children manipulate the icons in the picture while reading the story.

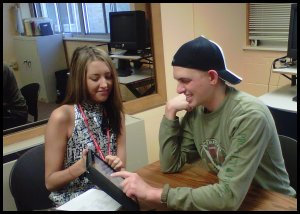 A University of Wisconsin Speech and Hearing Clinic client (right) using a text-to-picture iPad app. Photo courtesy of Jamie Murray-Branch. 2011.
A University of Wisconsin Speech and Hearing Clinic client (right) using a text-to-picture iPad app. Photo courtesy of Jamie Murray-Branch. 2011.