About
What Is a Data Catalog?
A data catalog is a system that helps organizations manage and find their datasets.
When a catalog first encounters a dataset, such as a table, it extracts metadata—table schemas, column statistics, and textual descriptions—and constructs a catalog graph. In this graph, nodes represent tables and columns, and edges represent relationships among them (e.g., which columns belong to a table, which tables are joinable).
Users can then query this graph to find desired datasets via browsing, keyword search, and natural language queries.
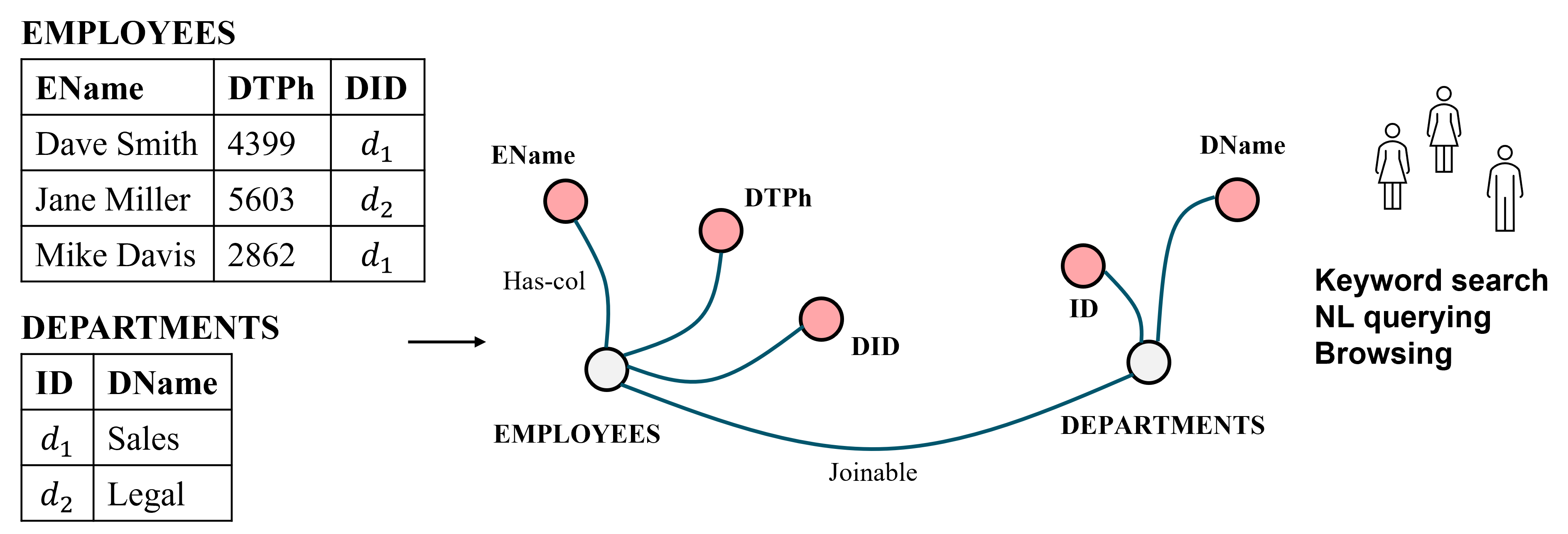
Beyond dataset discovery, data catalogs also serve a governance role. They help organizations track their datasets, improve data quality, protect against data loss and misuse, and conform to government regulations.
Why Organizations Need Data Catalogs
Organizations increasingly manage a large number of datasets, scattered across many locations and systems. When starting a data science or AI project, finding the right few datasets among this "sea of datasets" is often very difficult. Data catalogs address this challenge.
The need is felt across three broad types of organizations:
Companies
Large data integration vendors such as Informatica sell data catalog software to thousands of enterprise customers in industries such as insurance, finance, and healthcare. Many other vendors have entered this market, including Alation, Amazon, Ataccama, Collibra, Databricks, Data.world, Google, IBM, Microsoft, and Waterline.
The rapid growth of this market reflects the acute need for catalogs in the enterprise setting.
Domain Sciences
Environmental and other domain sciences have produced enormous numbers of datasets, often housed in shared data lakes. The Environmental Data Initiative (EDI), for example, has collected 87K+ data packages (each containing many CSV tables), totaling 60TB of storage, and serving 10K+ downloads per week.
As these lakes grow, helping researchers find the right datasets for analysis and AI model training has become a central challenge. Similar needs exist across many other domain science repositories, including Dryad, CUAHSI, Zenodo, Figshare, BCO-DMO, Arctic Data Center, and iDigBio.
Government Agencies
Many government agencies publish large collections of public datasets, viewing data as a valuable asset that taxpayers should have access to. Portals such as NYC Open Data and the City of Madison Open Data Portal house rich and diverse datasets, but typically provide very limited metadata and only primitive ways for users to find what they need (e.g., browsing by category or simple keyword search).
Increasingly, these organizations recognize that building good catalogs is difficult, and some have contracted with domain science repositories such as EDI to provide catalog services for their data.
Challenges in Building Data Catalogs
Despite the clear importance of data catalogs, the state of the art remains limited. We identify five key challenges:
Inferring Metadata
When a catalog first ingests a dataset, it must extract rich metadata automatically. This includes expanding cryptic table and column names into readable English phrases (e.g., "DTPh" → "Day Time Phone"), generating textual descriptions and tags, annotating columns with semantic types, and associating tables and columns with business terms from a pre-specified glossary.
It also includes discovering keys, matching schemas across tables, and finding joinable, unionable, lineage, and related-table relationships. Each of these is a research problem in its own right, and practical solutions must work well on enterprise and domain science data—which is often far more difficult than public benchmark data.
Helping Users Find Datasets
Once metadata and relationships have been inferred, users need effective ways to find desired datasets. The three main methods are browsing (navigating a taxonomy of tables or business terms), keyword search, and natural language querying.
Each presents serious challenges. Keyword search fails when table and column names are cryptic. Natural language querying requires translating user queries into structured queries over the catalog graph, a problem complicated by organization-specific synonyms (e.g., "domestic" meaning "US"). Both methods depend critically on the quality of the inferred metadata.
Curation
AI and ML solutions are imperfect, and human curation is essential to ensure metadata quality. Different metadata types may require different curation workflows—for example, table name expansion may require agreement from three users or one data steward, while column name expansion may require fewer approvals.
Drive-by curation (users editing on the fly) and bulk curation (data stewards spending dedicated time) must both be supported. Managing these workflows—and using curated outputs to improve other inferences—is a significant systems and research challenge.
Scaling
Real-world catalogs must handle hundreds of thousands to millions of tables. Many catalog tasks—schema matching, joinability detection, and others—can generate billions of candidate pairs.
Scaling these tasks requires careful use of blocking, distributed processing frameworks such as Spark, and approximate methods that balance accuracy with efficiency.
Handling Changes
Datasets in a catalog change over time—new tables are added, existing tables are updated, and metadata is curated. A catalog system must be able to incrementally update its inferred metadata and relationships in response to these changes, without re-running the full pipeline from scratch.
This requires incremental execution strategies, building on techniques from incremental view maintenance in database systems.
The State of the Art
Much academic research has addressed individual catalog components, under themes such as data lakes, data discovery, schema matching, and data integration. But from our experience at Informatica and EDI, we find that existing work often does not address many pain points, makes impractical assumptions, and does not scale to the sizes required in practice.
Catalog vendors develop their own solutions that scale well but have limited accuracy and are not open source.
There are very few, if any, open-source catalog systems that are industrial-strength. And there is very little interaction among the stakeholder communities—researchers, vendors, open-source developers, and users—which has particularly hurt domain sciences and government agencies that cannot afford commercial solutions.
SmartCat aims to bridge this gap by building an open-source, end-to-end catalog system, deploying it with real users, and advancing the research needed to make it work well.